Behind the scenes of the massive COVID-19 case report dataset – lessons from the unreadiness of artificial intelligence
Published in Research Data
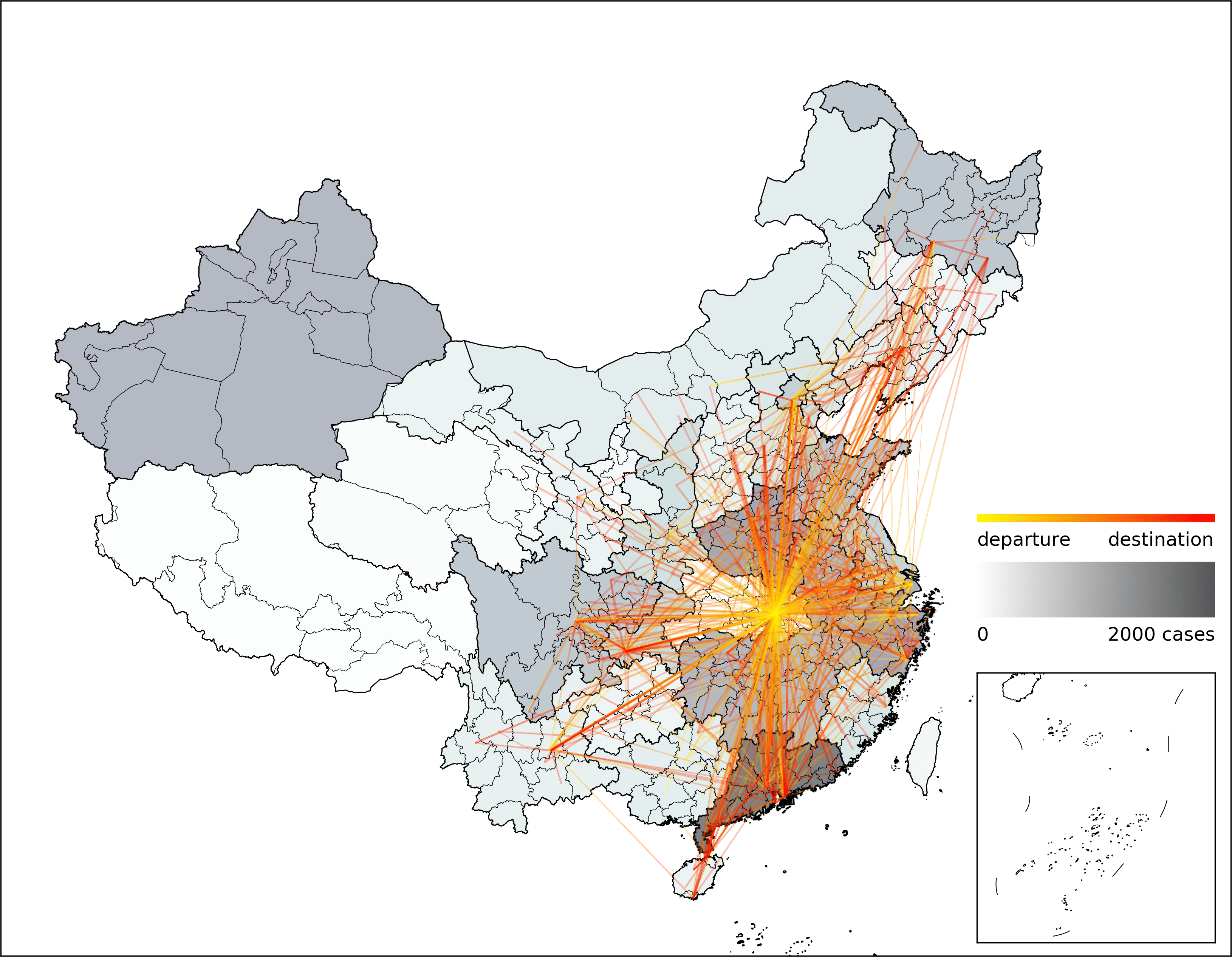
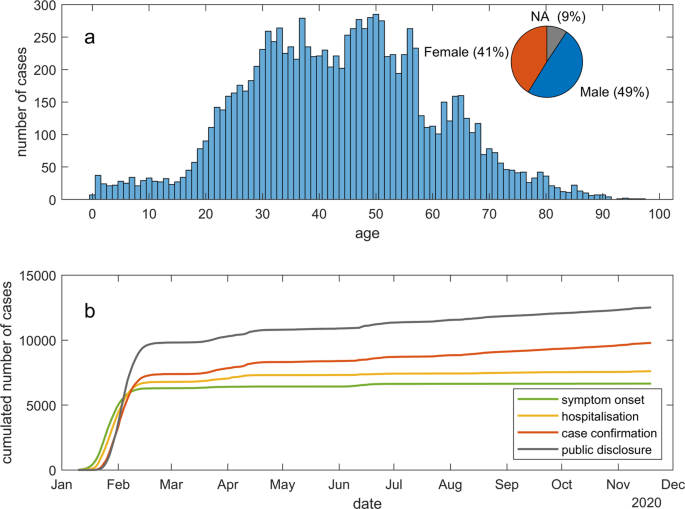
We’ve just published a massive line-list data on Scientific Data (https://doi.org/10.1038/s41597-021-00844-8), containing 14k+ COVID-19 cases with their detailed mobility and epidemiological information (28 data fields). The dataset is still being constantly updated, on a bi-weekly basis.
More than 20 research assistants are enrolled in this labor-intensive work, curating the 28 different features from a paragraph of report for each case disclosed by the health authorities online.
This is not an easy job.
Some of the features, e.g., the interim transits of the cases’ mobility, the close contact scenario, and when the symptoms were discovered, have proven quite difficult to be accurately understood. Disputes happen between coders, and an extra help is often needed to resolve the disputes.
We thought about seeking help from artificial intelligence for extracting the information in the first place. But only until now, i.e., a whole year after the outbreak, have we developed a first version of usable algorithm, achieving ~80% of accuracy for some easy fields. The machine learnt results are still far from immediately publishable, but they are already helping to speed up the human coding process.
Don’t get us wrong. We (and our collaborators) are not amateurs in NLP algorithms. Actually, our collaborators in Dalian University of Technology are among the best NLP scientists on Chinese language. Now, why artificial intelligence doesn’t help, then?
We think the reasons are two folds.
First, coding these online reports is a highly non-standard task. Although the nature of the tasks is just to extract entities and time, the problem is not that simple. Different types of entities are mixed, the coupling of entities and time (e.g., the mobility trajectory and epidemiological timeline) are complex, and the usage of languages by authorities in different regions are largely ... different. The algorithms trained from and performed well on standard datasets are just “unacclimatized” on these non-standard data.
Second, machine needs to learn from human. Humans have to feed the machine with enough samples for them to learn. In our case, 14k case reports seem like a massive number for human but are just an appetizer for the algorithm.
Now that we (luckily) have our first version algorithm running, the research assistants can finally catch a breath. But what we really hope is that they can easily sleep at night, without worrying about more jobs to be done when they wake up in the morning.
Follow the Topic
-
Scientific Data
A peer-reviewed, open-access journal for descriptions of datasets, and research that advances the sharing and reuse of scientific data.

Related Collections
With Collections, you can get published faster and increase your visibility.
Genomics in freshwater and marine science
Publishing Model: Open Access
Deadline: Jul 23, 2026
Genomes of endangered species
Publishing Model: Open Access
Deadline: Jul 01, 2026



Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in