Motivated decision making strategies: Can rewards help us deal with conflict?
Published in Neuroscience and Behavioural Sciences & Psychology

In some places where biking is popular, cities have installed bike-specific traffic lights. While helpful, they can sometimes cause internal conflict when the traffic light for the general road traffic indicates you should stop, but a bike-specific green traffic light suggests you can proceed. Small action conflicts like this are ubiquitous in our everyday lives.
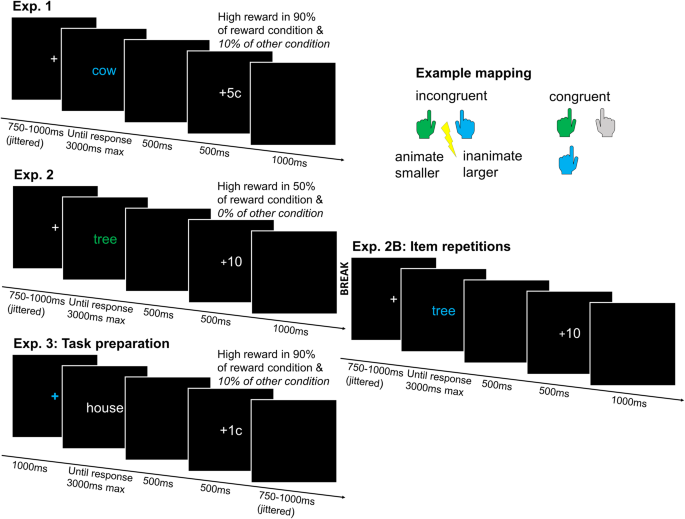
In our study recently published in Communications Psychology, we sought out to investigate if people become better at dealing with such conflicts if we reinforce them after successfully resolving them. We studied this by rewarding participants for correct performance in a task with many conflicts, using one critical manipulation. Namely, uninstructed to participants, one group was sometimes rewarded with more money if they managed to correctly respond to words that induced conflicting actions, while another group was rewarded more after successfully responding to words without any conflict. If you like to know more about what makes a word a conflict word, check out our full article, or just bear with us for now and accept that “banana” could be a conflict word while “pencil” was not.
In line with our hypothesis, we found that participants rewarded more following conflict words improved at resolving conflict, even when seeing new words they had not responded to before. To get a more fine-grained idea of which mental function was affected by our intervention, we applied computational modelling to dissect this decision process into several cognitive process components. These functions comprise a (stimulus) processing stage, the speed of information gathering, and response cautiousness. We found that participants in the group rewarded more following conflict words increased their cautiousness more after detecting conflict in new words, foregoing speed to increase the chance to earn a reward. Overall, these findings suggest that people can learn to optimize an abstract mental process when it is rewarding to do so, much like adaptive chassis control adjusting the car’s dampening system when the road gets bumpy.
Lastly, we made another interesting observation. While performance improvements did occur when being shown new conflict words, such improvements were much more pronounced when specific words that were rewarded before were encountered again (“banana!”). In other words, learning about explicit reward cues was much easier while learning that all conflict is rewarding was hard. To draw another analogy, it is easier to slow down when encountering a well-known bump, than to learn to adapt the most suitable driving style to a global landscape’s condition.
To conclude, perhaps you can become more efficient in resolving specific conflicts, such as quickly navigating through complex traffic situations when rewarding yourself to do so, for instance by getting a coffee when you arrive at your destination. Moreover, you may learn to generalize this across all scenarios comprising conflict such as new intersections, most likely by a dynamic monitoring of conflict and flexible adjustments in cautiousness before reacting to your impulse.
Follow the Topic
-
Communications Psychology
An open-access journal from Nature Portfolio publishing high-quality research, reviews and commentary. The scope of the journal includes all of the psychological sciences.

Related Collections
With Collections, you can get published faster and increase your visibility.
Replication and generalization
Publishing Model: Open Access
Deadline: Dec 31, 2026
Stress and Health
Publishing Model: Open Access
Deadline: Aug 31, 2026




Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in