Results and Implications for Generative AI in a Large Introductory Biomedical and Health Informatics Course
Published in Healthcare & Nursing and Computational Sciences
Generative artificial intelligence (AI), driven by large language models (LLMs), has had a profound impact in all scientific disciplines, including biomedicine. Accomplishments in the latter include passing medical board exams, solving clinical cases, drafting empathetic notes to patients, and proposing new drugs for treatment of diseases. Those of us who are educators have new challenges from generative AI, which is based on their ability to perform as well as students in a variety of learning assessments. One researcher, business professor Ethan Mollick from the University of Pennsylvania, has called this the “homework apocalypse.”
I decided to put this notion to the test in a large online introductory course that I teach in my field of biomedical and health informatics. The course is offered at the graduate, continuing education, and medical student levels. The curriculum for these offerings is essentially identical, with the course updated annually. Teaching occurs mainly via voice-over-Powerpoint lectures and threaded discussion forums, with assessment taking place via multiple-choice questions (MCQs; 10 per unit for each of the 10 units of the course) and a 33-question, short-answer final exam. Some instances of the course require a term paper and a few make use of flipped classrooms, virtual or in-person, for faculty-student discussion.
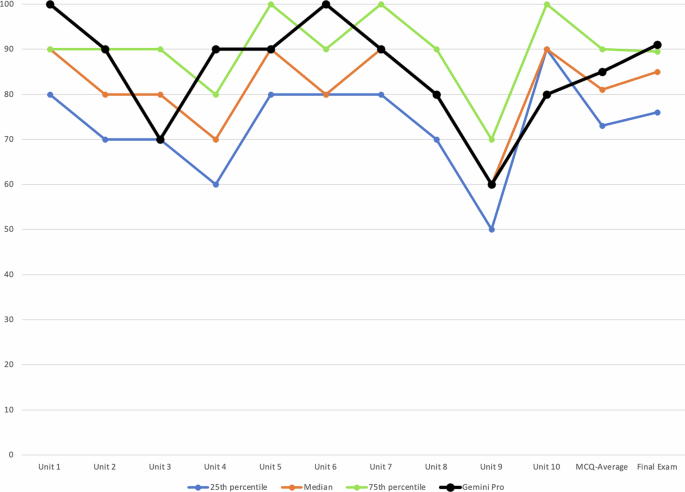
As in many fields, AI has become an increasing focus of the course. This naturally led to the question of how LLMs would perform on the assessments in the course. I put this to the test by submitting the assessments of last year’s (2023) version of the course. I prompted six high-profile commercial LLMs with the MCQs and final exam for the course. I used the LLMs as students would likely use them, i.e., through their Web interfaces. The LLMs included ChatGPT, Bing CoPilot, Google Gemini, Meta Llama, Claude, and Mistral.
Sure enough, the LLMs scored better than 50-75% of the students. Of the 139 students who completed the course in 2023, the best LLMs scored around the 75th percentile of all students. All of the LLMs did about the same, with Google Gemini scoring the best, but ChatGPT, Meta’s Llama, and the others scoring not too far behind. Another interesting finding, not surprisingly really, was that the LLMs completed the assessments, from the MCQs to the final exam, in about one minute’s time.
The implication for these results is that generative AI systems challenge our ability to assess student learning. This will require us to make modifications in how we evaluate students. This does not mean we should ban such tools, but that we need to find ways to ensure enough learning so students can think critically from a core of fundamental knowledge.
While the first thought the comes to mind with LLMs performing capably on student assignments and assessments is “cheating,” there are many larger issues of concern. In any academic discipline, is there a core of knowledge about which students should be able to answer questions without digital assistance? Does this core of knowledge facilitate higher-order thinking about a discipline? Does it enable thoughtful searching for information, via classic search or LLMs, for information beyond the human’s memory store?
The paper can be found at https://doi.org/10.1038/s41746-024-01251-0.
Hersh W, Fultz Hollis K. Results and implications for generative AI in a large introductory biomedical and health informatics course. NPJ Digit Med. 2024 Sep 13;7(1):247. doi: 10.1038/s41746-024-01251-0. PMID: 39271955.
I am a Professor in the Department of Medical Informatics & Clinical Epidemiology (DMICE) in the School of Medicine at Oregon Health & Science University (OHSU). I served as the inaugural Chair of DMICE from its inception in 2003 through 2022. I am a leader and innovator in biomedical informatics both in education and research.
In education, I served as Director of OHSU's Biomedical Informatics Graduate Program, from its inception in 1996 through 2023. The program has nearly 1000 alumni. I also conceptualized and implemented the first offering of the American Medical Informatics Association (AMIA) 10x10 ("ten by ten") program, which has been completed by more than 3000 individuals since 2005. In addition, I am Editor of the textbook, Health Informatics: Practical Guide, Eighth Edition (Lulu.com, 2022), which is available in print and eBook format and has an associated Web site.
I have also made many contributions in research. My research originally focused in the area of information retrieval (IR, also known as search), where I have authored over 200 scientific papers as well as the book, Information Retrieval: A Biomedical and Health Perspective (Springer, 2020), now in its fourth edition, available from Springer (including SpringerLink) or Amazon, and which has an associated Web site.
Follow the Topic
-
npj Digital Medicine
An online open-access journal dedicated to publishing research in all aspects of digital medicine, including the clinical application and implementation of digital and mobile technologies, virtual healthcare, and novel applications of artificial intelligence and informatics.

Related Collections
With Collections, you can get published faster and increase your visibility.
Evaluating the Real-World Clinical Performance of AI
Publishing Model: Open Access
Deadline: Jun 03, 2026
Impact of Agentic AI on Care Delivery
Publishing Model: Open Access
Deadline: Jul 12, 2026




Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in