Unlocking the Secrets of Material Literature: text mining facilitates alloy design
Published in Materials


The explosion of scientific literature has amassed a vast amount of invaluable knowledge and data. Text mining, as the key to unlocking this treasure, provides an ever-flowing wellspring of vitality for data-driven materials design. We introduce an automated pipeline for superalloy composition, synthesis and processing routine, and property extraction by text mining. Unlike the large-scale corpora in the field of chemistry, there is a scarcity of literature on alloys. For a relatively small corpus that lacks high-quality annotations, how can we extract knowledge and data by less expert intervention while maintaining high accuracy and recall? That was what we set out to answer in our study. The whole pipeline (Fig. 1) comprises several stages of scientific documents download, preprocessing, table parsing, text classification, named entity recognition (NER), table and text relation extraction (RE), and interdependency resolution.
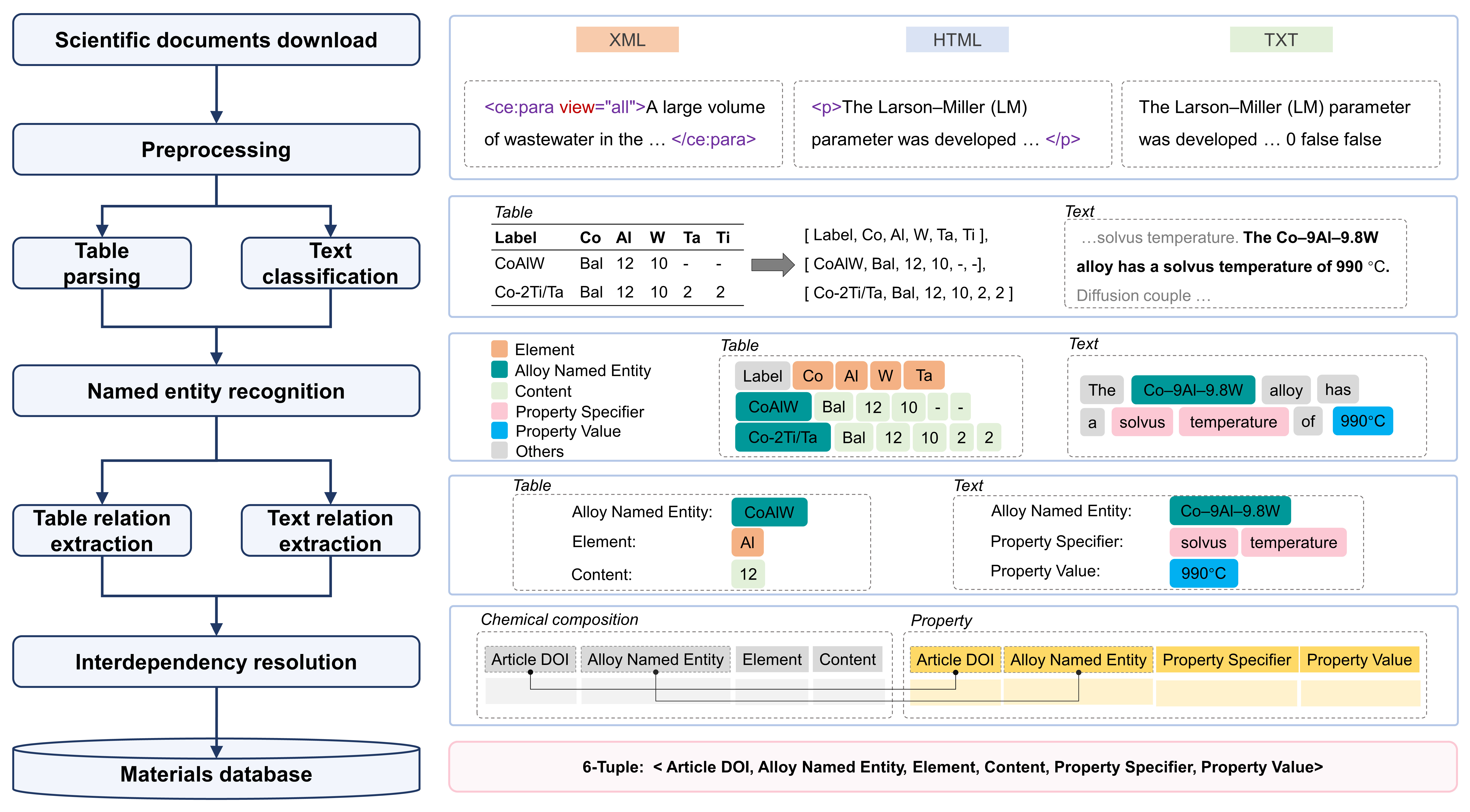
Fig. 1 Schematic workflow of the automated text mining pipeline. The workflow involves several stages of scientific documents download, preprocessing, table parsing, text classification, named entity recognition, table and text relation extraction, and interdependency resolution. A corpus of scientific articles is scraped and the irrelevant information in raw corpus is then filtered during preprocessing. According to the table parsing and text classification, the tables and sentences with target information are determined for named entity recognition and relation extraction. The alloy named entity, property specifier and property value are recognized by named entity recognition, and relation extraction of text and table gives the specific tuple relations. Interdependency resolution resolves the linkage to chemical composition and property data fragments for one specific material, and finally outputs a complete record into materials database.
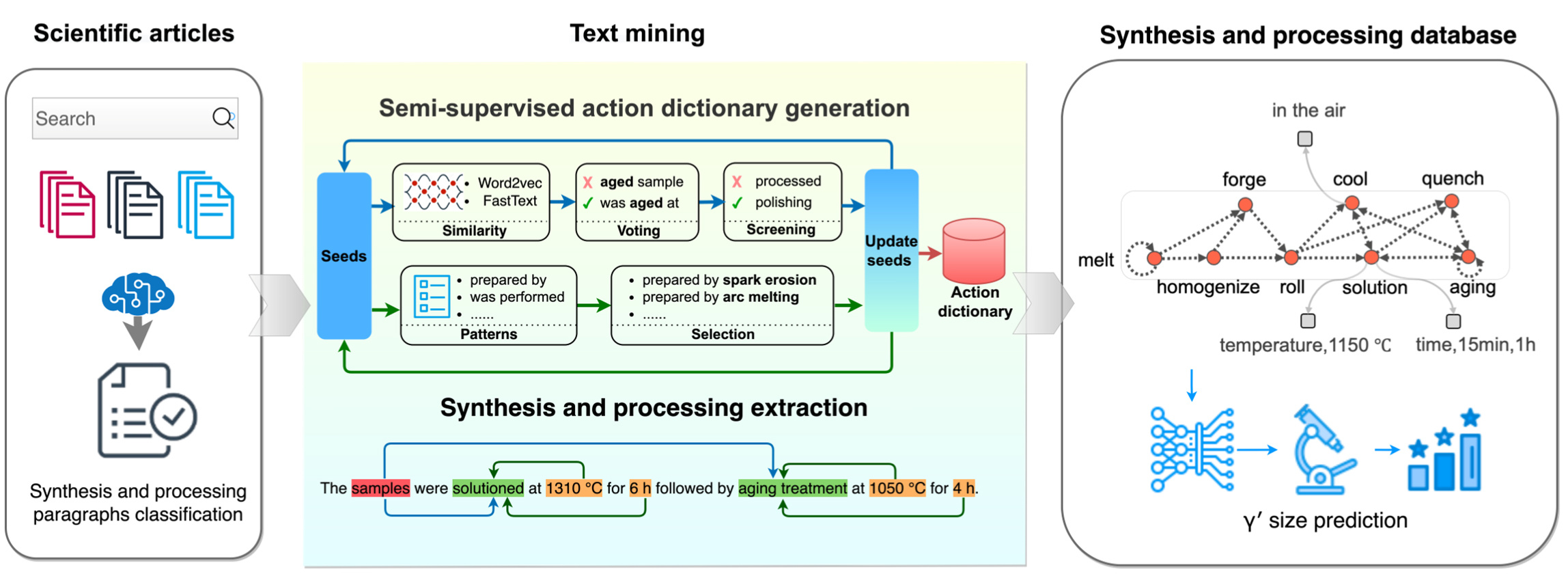
Amongst, rule-based NER and RE methods for composition/property are proposed to guarantee the precision and recall on small corpus. For synthesis and processing actions, a semi-supervised recommendation algorithm (Fig. 2) for token-level action and a multi-level bootstrapping algorithm for chunk-level actions are developed with just a limited amount of domain knowledge and human-machine interaction. Utilizing this pipeline, we obtain a machine learning available dataset containing alloy chemical composition, synthesis and processing actions and γ’ size records from a corpus of 16,604 superalloy articles published up to 2022.
The data are further used to capture an explicitly expressed synthesis factor, providing valuable insights for the study of phase evolution in superalloy (Fig. 3). We have shown how knowledge presented in the past literature can be extracted by text mining and provide actionable insights for materials discovery. As the scientific literature grows, it is inevitable that NLP will become a promising tool to extract and learn from published and unpublished work and provide a format that is machine-readable and AI-useable.
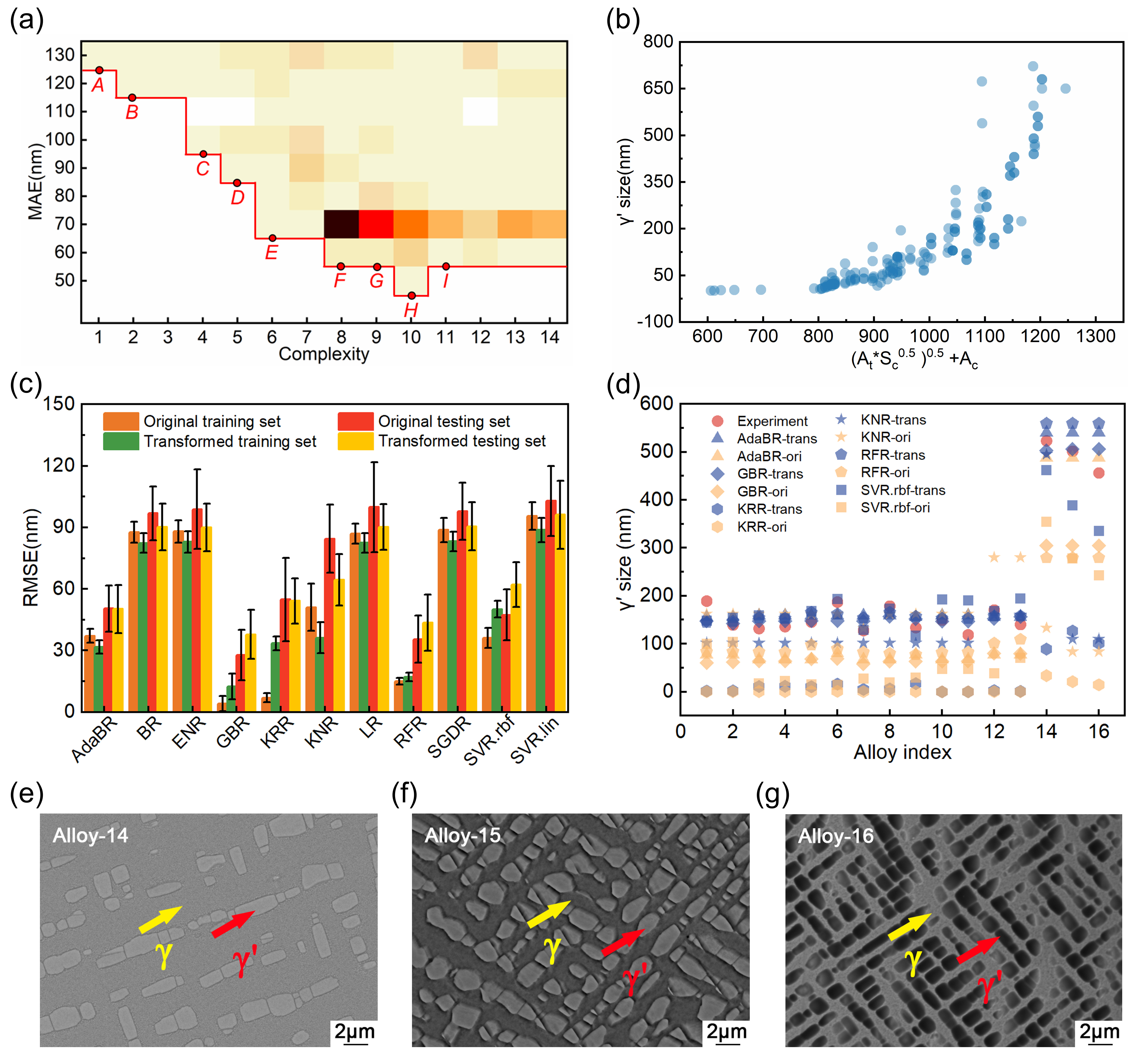
Fig. 3 The generated superalloy synthesis factor by SR which greatly improves γ′ size prediction performance. a Pareto front of MAE vs. complexity among 60,000 mathematical formulas shown via density plot. b Scatter plot of γ′ size vs (At*Sc0.5)0.5 + Ac. c RMSE for model selection under original and transformed feature space by fivefold cross validation. d The measured and predicted γ′ size of 13 superalloys newly reported in 2023 and 3 superalloys which we synthesized among all models. e The microstructure for alloy Co-29.6Ni-10.8Al-2Ti-2.5W1.6Ta-1Mo-3.5Cr. f The microstructure for alloy Co-30Ni-10.4Al-1.5Ti-1.6W-3Ta-1Mo-4.9Cr. g The microstructure for alloy Co-29.9Ni-10.4Al-1.9Ti1W-3.3Ta-1.1Mo-5.2Cr-0.8Re.
In recent years, large-scale language models (LLMs), such as GPT (Generative Pretraining Transformer), have revolutionized the field of natural language processing. These models are trained on vast amounts of unannotated texts and can then be fine-tuned for specific NLP tasks. Essentially, these models are creating a “well-read” black box that interprets language at a high level and can perform a multitude of tasks within that language. GPT-4 has supported multi-modal input by integrating the visual information. This new wave of technology would potentially lead to a prosperous ecosystem of real-world applications based on LLMs. We argue that by fine-tuning some prompts, it is possible to exploit the emergent abilities of LLMs for regression, classification, and information extraction in a small corpus and attain a higher accuracy and recall.
As we stand on the precipice of the age of artificial general intelligence, the potential for synergy between AI and materials is vast and promising. Creating AI powered assistants offers unprecedented opportunities to revolutionize the landscape of material research by applying knowledge across various disciplines, efficiently processing labor-intensive and time-consuming tasks such as literature searches, compound screening, and data analysis.
You can read more about our work in our article in npj Computational Materials following the link: https://www.nature.com/articles/s41524-023-01138-w and https://www.nature.com/articles/s41524-021-00687-2.
Follow the Topic
-
npj Computational Materials
This journal publishes high-quality research papers that apply computational approaches for the design of new materials, and for enhancing our understanding of existing ones.

Related Collections
With Collections, you can get published faster and increase your visibility.
Altermagnetic Materials: Theory, Simulation, and Renewed Perspectives
Publishing Model: Open Access
Deadline: Feb 28, 2027
Recent Advances in Active Matter
Publishing Model: Open Access
Deadline: Sep 01, 2026


Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in