An fMRI Dataset for Concept Representation with Semantic Feature Annotations
Published in Research Data
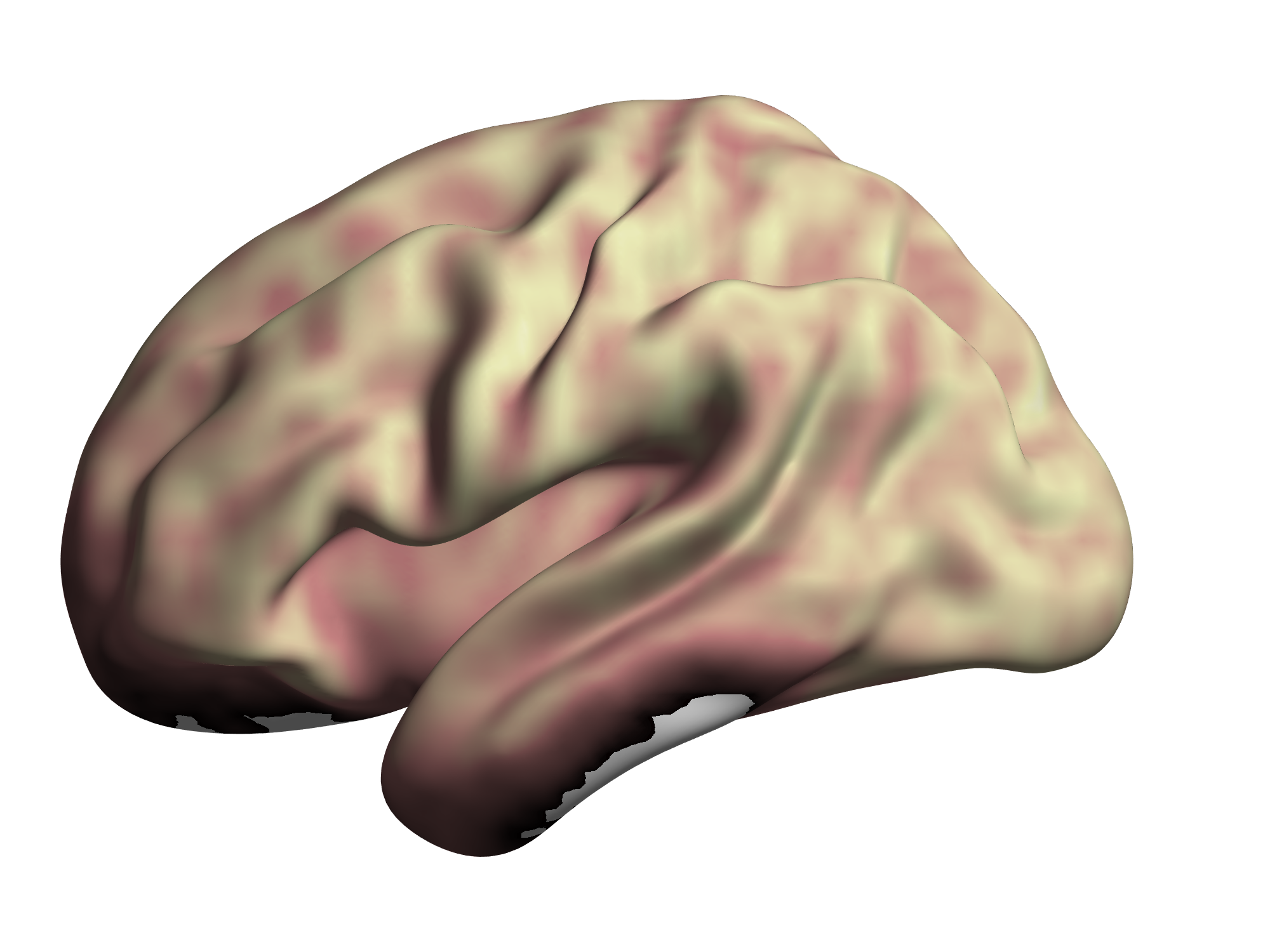

Language cognition is the most significant manifestation of human intelligence, and yet we know little about the language mechanism of brain: how the brain represents lexical meanings in a multimodal environment, how to integrate lexical meanings into the meanings of larger-grained language units, and how to carry out knowledge memory and reasoning. The newly emerging cognitive neuroscience research, combined with neuroimaging and computer modelling methods, has been able to infer the observed objects and the thought words from the patterns of human brain activity to a certain extent. These studies bring hope for researchers to reveal the neural mechanism of semantic memory and decode the mapping relationship between thinking and brain neural activities. Although current research has made some breakthroughs on the semantic representation of objects and nouns, other types of semantic representation (such as verbs, abstract words and function words) still need further research and exploration. Moreover, most existing studies focus on English, and there are few studies concentrating on neural coding in Chinese. The similarity and difference of brain coding between different languages is still unclear. One of the most important reasons is the lack of corresponding neuroimaging dataset for large-scale vocabulary comprehension.

In response to the above problems, our team (the Natural Language Processing Group of the Institute of Automation, Chinese Academy of Sciences) constructs a neuroimaging (fMRI) dataset including brain understanding of the Chinese words, named an fMRI Dataset for Concept Representation with Semantic Feature Annotations (CRSF), which has been published in Scientific data. We aim to provide a data basis for subsequent in-depth research on the language mechanism of brain. In CRSF, we collected about 58 hours of neuroimaging data, and 126 participants' annotation data for 54 semantic features (Figure 1). Finally, we present an fMRI data in which 11 participants thought of 672 individual concepts, including both concrete and abstract concepts. The concepts were probed using words paired with images in which the words were selected to cover a wide range of semantic categories. Furthermore, according to the componential theories of concept representation, we present the 54 semantic features of the 672 concepts comprising sensory, motor, spatial, temporal, affective, social, and cognitive experiences by crowdsourcing annotations (Figure 2). What’s more, in order to facilitate the research of brain language mechanism using computational models, we present different kinds of embedding on 672 concepts, including static word embeddings, contextual word embeddings and visual embeddings (Figure 3).


Furthermore, our team (the Natural Language Processing Group of the Institute of Automation, Chinese Academy of Sciences) also presents a synchronized multimodal neuroimaging dataset for studying brain language processing (SMN4Lang) and has been published in Scientific data, which includes functional magnetic resonance imaging (fMRI) and magnetoencephalography (MEG) data on the same 12 healthy volunteers who listened to 6 hours of naturalistic stories, as well as high-resolution structural (T1, T2), diffusion MRI and resting-state fMRI data for each participant.
CRSF and SMN4Lang provide a way to explore how the brain mobilizes different brain regions and how different brain regions work together when understanding words, phrases and sentences in real scenes. Using CRSF and SMN4Lang, we can not only study the brain’s cognitive mechanism to understand Chinese but also explore the relationship between language computing models and human brain language processing mechanisms. In addition, we can study how to use neuroimaging data to improve the performance of existing language computing models, and then build more effective language computing models.
Prof. Shaonan Wang is the first author and corresponding author of this article, Yunhao Zhang, Xiaohan Zhang, Jingyuan Sun, Prof. Nan Lin, Prof. Jiajun Zhang and Prof. Chengqing Zong have made important contributions to this article.
Citation:
Wang, S., Zhang, Y., Zhang, X. et al. An fMRI Dataset for Concept Representation with Semantic Feature Annotations. Sci Data 9, 721 (2022). https://doi.org/10.1038/s41597-022-01840-2
Wang, S., Zhang, X., Zhang, J. et al. A synchronized multimodal neuroimaging dataset for studying brain language processing. Sci Data 9, 590 (2022). https://doi.org/10.1038/s41597-022-01708-5
Follow the Topic
-
Scientific Data
A peer-reviewed, open-access journal for descriptions of datasets, and research that advances the sharing and reuse of scientific data.

Related Collections
With Collections, you can get published faster and increase your visibility.
Computer vision in plant science and agriculture
Publishing Model: Open Access
Deadline: Oct 10, 2026
Datasets in education
Publishing Model: Open Access
Deadline: Nov 19, 2026

Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in