Behind the Paper: Using co-sharing to identify use of mainstream news for promoting potentially misleading narratives
Published in Social Sciences, Computational Sciences, and Mathematics
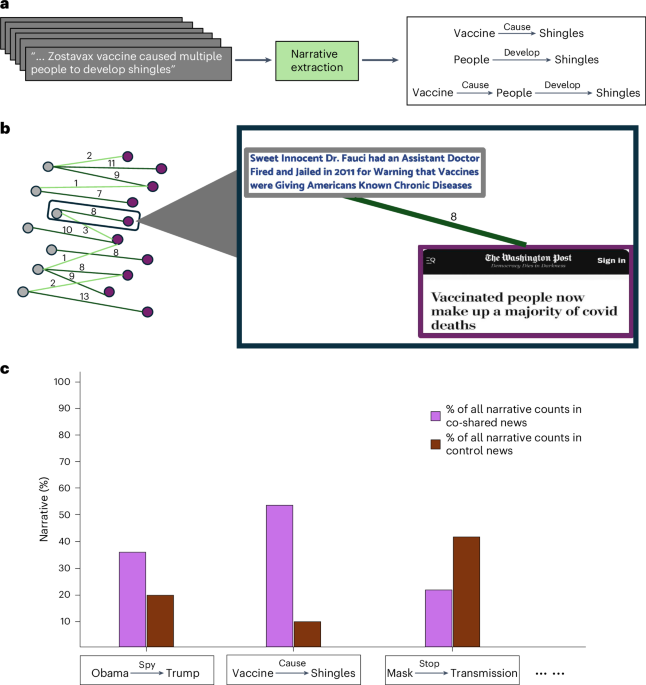
How it begins: Research interests meet anecdotally observed real-world ‘puzzles’
As researchers interested in circulation of news on social media and the challenge of misinformation spread online, there were several puzzling things we observed anecdotally that we felt called to study. One of the puzzles was how empirical studies quantifying spread of misinformation or ‘fake news’ on social media seemed to conclude that misinformation is a very small part of people’s media diet, and yet, several studies also outlined the harms and negative impact of misinformation spread in a variety of domains. Another puzzle was how misinformation sharers on social media do not exclusively share ‘fake’ news or news from domains known to be unreliable; rather, they also share ‘mainstream’ news where the sources are reputable or considered reliable. These puzzles interacted with some mainstream reporting in 2020 and 2021 on the COVID-19 pandemic which would draw a collective groan from us. Articles such as the one from the Washington Post with the original headline: “Vaccinated people now make up a majority of covid deaths” (the headline was changed 3 days later, but it was already notoriously popular on Twitter/X amongst the anti-vax community), or the one from Chicago Tribute titled “A ‘healthy’ doctor died two weeks after getting a COVID-19 vaccine; CDC is investigating why”, were obvious ammunition for folks who shared misinformation surrounding the efficacy and safety of vaccines, and arguably carried more legitimacy and potential reach (as demonstrated by case studies in our paper). But these articles would not be typically considered in much of misinformation research because of the domains publishing these articles!
The heart of the problem, and a path forward
The theoretical and operational problem here is quite clear. “Fake news” is conceptualized in a process-driven way (e.g., “fabricated information that mimics news media content in form but not in organizational process or intent”), which encourages source-level measures. Primarily due to operational ease and availability of domain-level lists, sources are categorized as reliable or unreliable, based in large part on the respective sources’ adherence (or lack thereof) to the procedures and norms of mainstream journalism, in addition to their reputations for veracity. This binary label of ‘reliable’ or ‘unreliable’ is then projected onto all of the stories and information published by a source, and thus, misinformation research tends to focus on a fixed set of ‘unreliable news domains’ created at a prior point in time. All the stories by ‘reliable’ outlets are out of consideration for misinformation research in this setup. Reputation of the source of a news story is used as a proxy for potential truth value of the story. The binary categorization of sources as either “fake” or “reliable” obscures the reality that information produced by reliable sources can be false or misleading.
Moreover, the binary categorization of information as either true or false does not account for the extent to which information — especially on the internet — does not exist independently from its social function; the extent to which information informs, rather than misinforms, often depends on how it is used!
So we understood the theoretical challenges, but offering a practical way to confront them was the real challenge we wanted to start addressing with our work. We broke down the overall challenge into two pieces:
- Moving beyond the level of news sources or domains: We need a way to identify individual mainstream articles of interest.
- Moving beyond a focus on the truth value or the factuality of a news story: We need a way to try and understand what factors could make a mainstream news story useful to misinformation sharers.
Fortunately, our backgrounds in network science and natural language processing (NLP) helped us tackle both these challenges and offer a promising path for future research.
Solution to challenge 1: Co-sharing.
Using a dataset of Twitter/X shares of news articles, We construct a weighted graph with individual articles or URLs as nodes. Edges between a fake news URL and a reliable news URL are weighted by the number of Twitter users in our dataset that shared both the incident node URLs at least once. We apply a graph-pruning algorithm to assign each edge a co-sharing score based on the likelihood of both incident node URLs getting shared by the same user, controlling for the individual popularity of each of those URLs in isolation. This co-sharing score helps us identity mainstream news articles disproportionately co-shared with “fake” news as well as establish a control set of articles from the same mainstream outlets.
The networked nature of information sharing on online social media platforms, specifically the concept of co-sharing, can therefore help identify individual pieces of content (such as mainstream news articles) of interest.
Solution to challenge 2: Automated Narrative Extraction.
Next, we use an automated NLP tool to extract narrative structures from mainstream articles, “fake” news articles, and fact-checked statements known to be false. We expect that mainstream stories with high scores on our co-sharing measure will be significantly more likely than those with low co-sharing scores to contain narratives present in misinformation content, or potentially misleading narratives. We define these potentially misleading narratives as entity-action relationships that repeatedly occur in information produced by unreliable sources or occur in statements known to be false (e.g., ‘vaccines cause autism’).
Automatically identifying narratives (structured entity-action relationships) helps us go from the ‘factuality’ focus to studying ‘usefulness’ of news articles. With current advancements in NLP, we expect scientists to have increasingly better tools for extracting narratives and underlying worldviews from text data, especially when social media context about the author of a text can supplement such narrative extraction. This means we need not rely solely on binary classifications of domains, but can increasingly study the content itself, and can operationalize detection of various social constructs in a way that enables the study of the social use of information!

(Image: Examples of tweets by people with a history of sharing unreliable news, sharing select mainstream news articles)
Implications of Our Findings and Conclusion
We find that mainstream articles that circulate among fake-news-sharing users on Twitter/X are significantly more likely to contain narratives that are prevalent in misinformation content, compared with mainstream articles from the same reliable outlets that are not co-shared with fake news. This effect is not fully attributable to partisan curation — our findings are not entirely dependent on potentially misleading narratives carrying a left- or right-leaning slant. Our finding suggests that users strategically repurpose mainstream news to develop and spread potentially misleading narratives on social media. Indeed, it is likely that users promoting misleading narratives find mainstream sources particularly attractive when they publish information that can be repurposed to fit those narratives precisely because of these sources’ credibility. To this end, analyses based on our dataset in fact show that the reach and potential audience for mainstream news articles co-shared with those fake news articles is more than twice that of fake news articles. This is consistent with related instances of partisan information being seen as more credible when it comes from unexpected sources, and suggests a general framework in which users share information that they perceive to be useful for advancing their broader worldviews.
For responsible journalistic practice: when vetting news stories and their framing, especially for the headlines, it is important to consider not just the raw information of the story itself but also the broader claims that the information could be used to support. Technological methods like the ones we have developed and used here may help go beyond checking a story’s factuality and accuracy and contribute to minimizing the risk of a story being repurposed to mislead. Journalists committed to the rigor of their reporting and how their content might get used or misused can adjust their framing accordingly before publishing to help reduce the chances of mainstream news articles potentially legitimizing world views based on false or unsubstantiated claims.
For scientific research on online misinformation, our work highlights the importance of considering the broader context in which a specific piece of information is being circulated, rather than solely relying on classifying information (to say nothing of sources) as strictly reliable or unreliable. A better framework for understanding the apparent problems with the online information ecosystem must account for user preferences and behavior, including their preferences for information for reasons other than its truth value (such as its usefulness for protecting worldviews and advancing interests as conceptualized by Williams (2022)). This, ultimately, is the framework we hope our study can promote and help the scientific community reach to address the puzzles and grievances outlined in the beginning of this post.
Follow the Topic
-
Nature Human Behaviour
Drawing from a broad spectrum of social, biological, health, and physical science disciplines, this journal publishes research of outstanding significance into any aspect of individual or collective human behaviour.

Introducing: Social Science Matters
Social Science Matters is a campaign from the team at Palgrave Macmillan that aims to increase the visibility and impact of the social sciences
Continue reading announcementRelated Collections
With Collections, you can get published faster and increase your visibility.
Digital Media and Mental Health
Publishing Model: Hybrid
Deadline: Oct 30, 2026
Basic Psychological Needs and Well-Being
Publishing Model: Hybrid
Deadline: Nov 27, 2026




Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in