Boosting machine learning for materials properties by denoising multi-fidelity data
Published in Materials
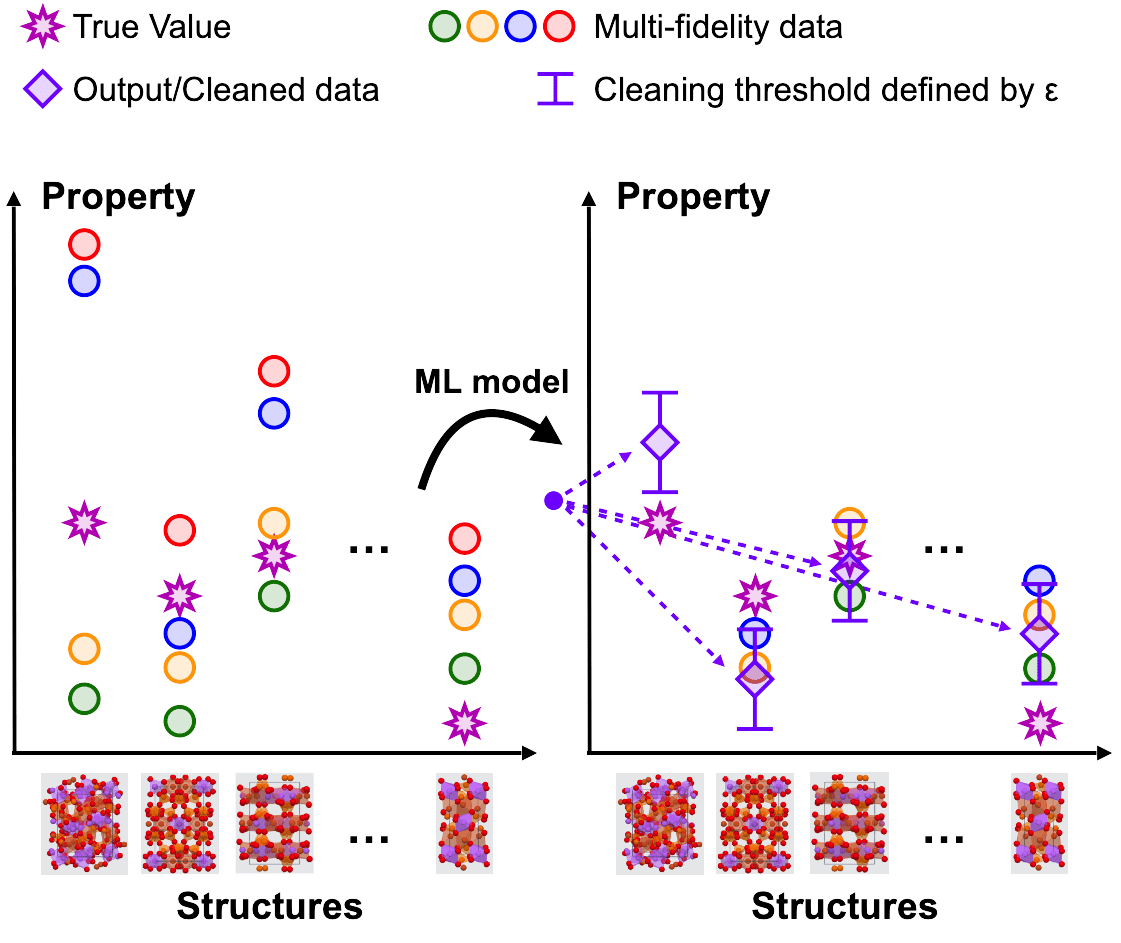

The current era is characterized by an ever-growing amount of data, which are typically gathered in databases. Since these may come from various sources, with diverging standards, protocols, approximations and curation methods, different databases present varying degrees of accuracy. This points directly to the concept of multi-fidelity (MF) data, which is a cross-field notion.
Let us consider a student preparing for the theoretical driving license exam. After carefully learning the theory, the student will typically practice on a series of available questions and answers (Q&As). Usually, the examination center provides a few typical Q&As. As these come from the highest trusted source, the student can safely study them. Nonetheless, such highly trustable Q&As are often scarce. Most of the Q&As that the student has gathered regularly originate from unofficial sources such as books or apps, which are more or less trustworthy. The larger the number of Q&As, the better the student will, in principle, be prepared for taking the exam. However, the student needs to take into account the quality of the Q&As from which they study. How should they extract as much knowledge as possible from the available Q&As of varying trustworthiness? This is the core of the multi-fidelity problem.
In our recent publication, we tackle this problem in the field of materials informatics. The questions of the above example become materials, the answers turn into properties, and the student is a machine-learning (ML) model. The analogy comes from the fact that, when probing a property for a material, the quality of the result varies depending on the method of determination (be it experimental or computational) leading to different fidelities. Furthermore, there is typically an inverse relationship between the amount of data and their accuracy, given that high accuracy results are more difficult to obtain.
Most previous works have focused on the ML model (i.e., finding the most talented student). Here, we take a different route by first determining what is the best learning strategy (i.e., finding the best teacher). We demonstrate that the ML model performance can be improved by first acquiring knowledge from all available data,and then performing additional sequential learning while removing low-fidelity data (i.e., less trustworthy questions) at each step. In particular, it is better to start by learning on the simulated data and fine-tune the model on the experimental (high-fidelity) data. In the example above, the student would be spending most of the time before the exam on the official Q&As.
We also approach the problem from a noise perspective. The target property of a material has various estimates (simulations) around the ground truth (experimental), in the same way as different answers can be given for the same exam question. When the low-fidelity data is far from the prediction from a pre-trained ML model, the data is assumed to be inaccurate and canthus be replaced by the prediction. This procedure can be repeated iteratively.
Our implementation is shown to perform well at predicting electronic band gaps and is general enough to be applied in a wider contest. We hope that our result will extend and stimulate the use of multi-fidelity data in ML. This will become even more important in a world driven by automated high-throughput labs.
Follow the Topic
-
npj Computational Materials
This journal publishes high-quality research papers that apply computational approaches for the design of new materials, and for enhancing our understanding of existing ones.

Related Collections
With Collections, you can get published faster and increase your visibility.
Altermagnetic Materials: Theory, Simulation, and Renewed Perspectives
Publishing Model: Open Access
Deadline: Feb 28, 2027
Recent Advances in Active Matter
Publishing Model: Open Access
Deadline: Sep 01, 2026



Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in