Building a robust tool for processing metagenomes, one error at a time
Published in Microbiology
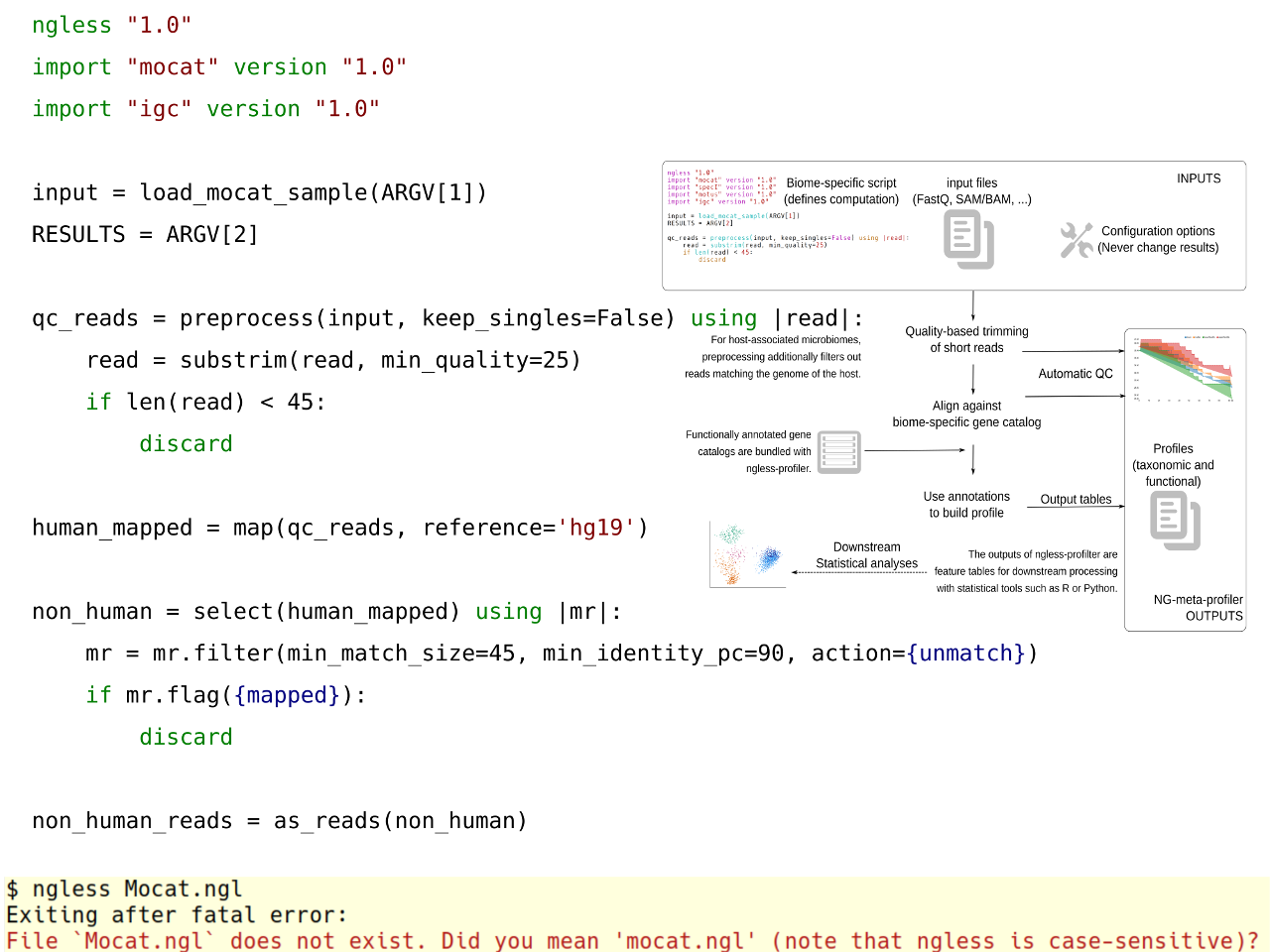

The goal of NG-meta-profiler is to take metagenomes as inputs and produces estimates of either taxonomic or functional abundances. At a high-level, we use a well-validated approach to metagenomic analysis: use a pre-annotated gene catalogue as a reference against which to align metagenomic reads [1-3]. The big innovation is in the way the tool was designed and is presented to the users.
What do we want from our computational tools?
On the one hand, we want standard pipelines that embody best practices and enable comparisons between different studies and datasets, we want them to be easy to install and use by individuals without a strong background in bioinformatics. On the other hand, we want the flexibility to adapt to the specificity of each dataset and expert bioinformaticians will want to tweak and combine tools to address different contexts and requirements.
We propose a solution to these seemingly conflicting goals by presenting a set of standard pipelines that can be easily adapted while maintaining reproducibility. The central concept behind the work is a novel programming language for processing NGS data called NGLess which was used to write these standard pipelines.

NG-meta-profiler and NGLess are just now being published as a journal article, but the tools themselves have been in development for several years and were always available as open-source software. In fact, the initial intuition that this could be a good idea first came to me back in 2012! Looking back at my mail archives, I found an email from me to co-author Ana Teresa Freitas from September 21st 2012 with some initial thoughts on the idea as a follow-up to a conversation we had earlier.
Then, the project proceeded through three phases:
Proof-of-concept (2013-2014).
Internal use, maturation (2015-2016).
Release to wider public (2017-present).
The initial goal was to design a simple programming language and write a piece of software that would solve some toy problems. This work was the bulk of Paulo Monteiro’s MS Thesis, which he submitted at the end of 2014.
At this point, most of the ideas were in place and we had proved that the concept could work to process data, but the tool was slow and would often produce hard-to-understand error messages. After improving the performance, we started using the tool internally for our own projects (e.g., [4]). The NGLess interpreter became more robust with time and started to produce better error messages. This was a slow process as behind each little improvement there was often a confusing debugging session. For example, a malformed FastQ file could cause an “Out of memory” error. Naturally, we would then attempt to run the analysis in a large-memory machine before realizing what was going on.

Around 2017, we started encouraging others to use the tools and receiving feedback. We realized that the way the software was built caused issues with some types of HPC clusters (even though it had run fine on our systems). We received further reports of confusing error messages and improved those. We realized that there were some inconsistencies that confused new users and streamlined the interface.
Individually, all of these were minor changes, but collectively these hundreds of small improvements make all the difference between the finicky proof-of-concept we had in 2014 and a tool we could proudly recommend to others. So, in 2018, we finally decided it was time to submit it as a manuscript to a journal, and you can now read about it at Microbiome.
REFERENCES
[1] Kultima JR, Coelho LP, Forslund K, Huerta-Cepas J, Li SS, Driessen M, Voigt AY, Zeller G, Sunagawa S, Bork P. MOCAT2: a metagenomic assembly, annotation and profiling framework. Bioinformatics. 2016 Apr 8;32(16):2520-3.
[2] Huerta-Cepas J, Forslund K, Coelho LP, Szklarczyk D, Jensen LJ, von Mering C, Bork P. Fast genome-wide functional annotation through orthology assignment by eggNOG-mapper. Molecular biology and evolution. 2017 Aug 1;34(8):2115-22.
[3] Ugarte A, Vicedomini R, Bernardes J, Carbone A. A multi-source domain annotation pipeline for quantitative metagenomic and metatranscriptomic functional profiling. Microbiome. 2018 Dec;6(1):149.
[4] Schmidt TS, Hayward MR, Coelho LP, Li SS, Costea PI, Voigt AY, Wirbel J, Maistrenko OM, Alves RJ, Bergsten E, de Beaufort C. Extensive transmission of microbes along the gastrointestinal tract. eLife. 2019 Feb 12;8:e42693.
Follow the Topic
-
Microbiome

This journal hopes to integrate researchers with common scientific objectives across a broad cross-section of sub-disciplines within microbial ecology. It covers studies of microbiomes colonizing humans, animals, plants or the environment, both built and natural or manipulated, as in agriculture.
Related Collections
With Collections, you can get published faster and increase your visibility.
Harnessing plant microbiomes to improve performance and mechanistic understanding
This is a Cross-Journal Collection with Microbiome, Environmental Microbiome, npj Science of Plants, and npj Biofilms and Microbiomes. Please click here to see the collection page for npj Science of Plants and npj Biofilms and Microbiomes.
Modern agriculture needs to sustainably increase crop productivity while preserving ecosystem health. As soil degradation, climate variability, and diminishing input efficiency continue to threaten agricultural outputs, there is a pressing need to enhance plant performance through ecologically-sound strategies. In this context, plant-associated microbiomes represent a powerful, yet underexploited, resource to improve plant vigor, nutrient acquisition, stress resilience, and overall productivity.
The plant microbiome—comprising bacteria, fungi, and other microorganisms inhabiting the rhizosphere, endosphere, and phyllosphere—plays a fundamental role in shaping plant physiology and development. Increasing evidence demonstrates that beneficial microbes mediate key processes such as nutrient solubilization and uptake, hormonal regulation, photosynthetic efficiency, and systemic resistance to (a)biotic stresses. However, to fully harness these capabilities, a mechanistic understanding of the molecular dialogues and functional traits underpinning plant-microbe interactions is essential.
Recent advances in multi-omics technologies, synthetic biology, and high-throughput functional screening have accelerated our ability to dissect these interactions at molecular, cellular, and system levels. Yet, significant challenges remain in translating these mechanistic insights into robust microbiome-based applications for agriculture. Core knowledge gaps include identifying microbial functions that are conserved across environments and hosts, understanding the signaling networks and metabolic exchanges between partners, and predicting microbiome assembly and stability under field conditions.
This Research Topic welcomes Original Research, Reviews, Perspectives, and Meta-analyses that delve into the functional and mechanistic basis of plant-microbiome interactions. We are particularly interested in contributions that integrate molecular microbiology, systems biology, plant physiology, and computational modeling to unravel the mechanisms by which microbial communities enhance plant performance and/or mechanisms employed by plant hosts to assemble beneficial microbiomes. Studies ranging from controlled experimental systems to applied field trials are encouraged, especially those aiming to bridge the gap between fundamental understanding and translational outcomes such as microbial consortia, engineered strains, or microbiome-informed management practices.
Ultimately, this collection aims to advance our ability to rationally design and apply microbiome-based strategies by deepening our mechanistic insight into how plants select beneficial microbiomes and in turn how microbes shape plant health and productivity.
This collection is open for submissions from all authors on the condition that the manuscript falls within both the scope of the collection and the journal it is submitted to.
All submissions in this collection undergo the relevant journal’s standard peer review process. Similarly, all manuscripts authored by a Guest Editor(s) will be handled by the Editor-in-Chief of the relevant journal. As an open access publication, participating journals levy an article processing fee (Microbiome, Environmental Microbiome). We recognize that many key stakeholders may not have access to such resources and are committed to supporting participation in this issue wherever resources are a barrier. For more information about what support may be available, please visit OA funding and support, or email OAfundingpolicy@springernature.com or the Editor-in-Chief of the journal where the article is being submitted.
Collection policies for Microbiome and Environmental Microbiome:
Please refer to this page. Please only submit to one journal, but note authors have the option to transfer to another participating journal following the editors’ recommendation.
Collection policies for npj Science of Plants and npj Biofilms and Microbiomes:
Please refer to npj's Collection policies page for full details.
Publishing Model: Open Access
Deadline: Jun 01, 2026
Microbiome and Reproductive Health
Microbiome is calling for submissions to our Collection on Microbiome and Reproductive Health.
Our understanding of the intricate relationship between the microbiome and reproductive health holds profound translational implications for fertility, pregnancy, and reproductive disorders. To truly advance this field, it is essential to move beyond descriptive and associative studies and focus on mechanistic research that uncovers the functional underpinnings of the host–microbiome interface. Such studies can reveal how microbial communities influence reproductive physiology, including hormonal regulation, immune responses, and overall reproductive health.
Recent advances have highlighted the role of specific bacterial populations in both male and female fertility, as well as their impact on pregnancy outcomes. For example, the vaginal microbiome has been linked to preterm birth, while emerging evidence suggests that gut microbiota may modulate reproductive hormone levels. These insights underscore the need for research that explores how and why these microbial influences occur.
Looking ahead, the potential for breakthroughs is immense. Mechanistic studies have the power to drive the development of microbiome-based therapies that address infertility, improve pregnancy outcomes, and reduce the risk of reproductive diseases. Incorporating microbiome analysis into reproductive health assessments could transform clinical practice and, by deepening our understanding of host–microbiome mechanisms, lay the groundwork for personalized medicine in gynecology and obstetrics.
We invite researchers to contribute to this Special Collection on Microbiome and Reproductive Health. Submissions should emphasize functional and mechanistic insights into the host–microbiome relationship. Topics of interest include, but are not limited to:
- Microbiome and infertility
- Vaginal microbiome and pregnancy outcomes
- Gut microbiota and reproductive hormones
- Microbial influences on menstrual health
- Live biotherapeutics and reproductive health interventions
- Microbiome alterations as drivers of reproductive disorders
- Environmental factors shaping the microbiome
- Intergenerational microbiome transmission
This Collection supports and amplifies research related to SDG 3, Good Health and Well-Being.
All submissions in this collection undergo the journal’s standard peer review process. As an open access publication, this journal levies an article processing fee (details here). We recognize that many key stakeholders may not have access to such resources and are committed to supporting participation in this issue wherever resources are a barrier. For more information about what support may be available, please visit OA funding and support, or email OAfundingpolicy@springernature.com or the Editor-in-Chief.
Publishing Model: Open Access
Deadline: Jun 16, 2026


Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in