Decoding the Genetic Puzzle of Polyploid Crops: A Sugarcane Story
Published in Genetics & Genomics and Agricultural & Food Science
In the world of plant biology, polyploidy is a fascinating phenomenon. While most animals, including humans, are diploids-meaning we inherit two sets of chromosomes, one from each parent-many plants carry multiple sets of chromosomes. This genetic redundancy is a hallmark of some of our most important global crops, such as wheat, potatoes, cotton, and sugarcane.
In agriculture, polyploidy is often a blessing. The extra copies of genes can make plants larger, more robust, and highly adaptable to environmental stresses. However, for geneticists and breeders trying to understand these plants at a molecular level, polyploidy has historically been a profound bioinformatics roadblock.
The Analytical Bottleneck in Polyploid Genomics
To understand why polyploid plants are so difficult to study, we must look at the tools available to us. For decades, the analytical frameworks used in genomics were designed primarily for diploid organisms. When these traditional tools are applied to highly complex polyploid genomes, researchers encounter several major hurdles:
- Assembly Challenges: Imagine trying to put together a jigsaw puzzle where 10 to 12 nearly identical copies of the same picture are mixed into a single box. Sorting out which specific piece belongs to which specific copy (a process known as haplotype phasing) is an immense computational challenge.
- The GWAS Bottleneck: Genotyping and Dosage: In a diploid plant, a gene has two alleles. In a complex polyploid, a single gene might exist ten or more homologous copies. When researchers rely on a monoploid reference for genotyping, highly similar sequencing reads from different copies cause deeply inaccurate genotyping. This also makes it impossible to reliably measure the "dosage effect" which is vital for deciphering the genetic basis of plant trait formation. Traditional GWAS pipelines are simply blind to this polyploid complexity, severely skewing downstream analyses and making it incredibly difficult to confidently link genetic variations to key agricultural traits.
- Allele-Specific Expression: Because the different copies of a gene in a polyploid are highly similar, standard short-read sequencing methods cannot reliably tell which specific allele is actively being expressed. If we cannot isolate the "active" allele, we cannot fully understand how the plant controls its biology.
Sugarcane: An important and Typical Polyploid
As a team specializing in the development of algorithms for complex polyploid genomics, we wanted to tackle these challenges head-on. We chose sugarcane as our focus. Sugarcane is a vital crop that supplies the majority of the world's sugar and serves as a critical source of bioenergy.
It also happens to possess one of the most complex polyploid genomes in the plant kingdom. Modern sugarcane cultivars are the result of historical crossbreeding between a high-sugar species (Saccharum officinarum) and a hardy, disease-resistant wild species (Saccharum spontaneum). This history has left modern sugarcane with 10 to 12 sets of chromosomes. It suffers from all the genomic bottlenecks mentioned above, severely limiting molecular breeding efforts.We focused our efforts on POJ2878, an iconic hybrid cultivar developed over a century ago. Known historically as the "King of Sugarcane," it is a foundational parent for many modern varieties.
Building a Polyploid Dedicated Analytical Framework
To decode POJ2878, we realized we couldn't rely on existing software. Instead, we developed an integrated polyploid genomics framework tailored to address these specific bottlenecks.
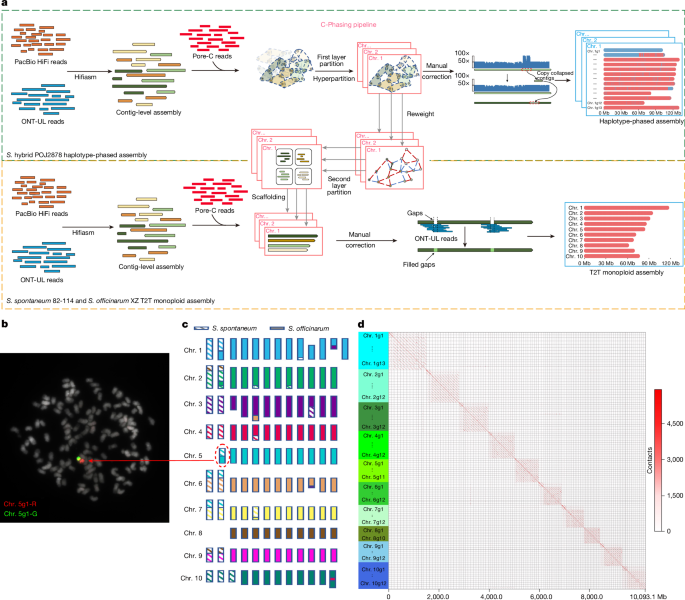
First, to solve the assembly puzzle, we utilized a new algorithm (C-Phasing) that leverages chromatin conformation data using Pore-C sequencing technologies to organize the genome. This allowed us to successfully separate and assemble the phased genome of POJ2878, resolving 118 distinct, high-quality chromosomes.
Second, to understand allele-specific expression, we developed Allele-Express. We used a custom-designed Allele Identification module to accurately identify allelic genes within the haplotype-resolved genome. Building upon this foundation, by utilizing MAS-ISO-seq, this tool allows us to confidently quantify allele-specific expression levels.
Finally, to address the genotyping and dosage problem, we implemented KMERIA. Rather than relying on traditional marker methods that fail in polyploids, this algorithm uses short, fixed-length DNA sequences (k-mers) to accurately estimate allele dosage and perform genome-wide association studies (GWAS), effectively bypassing the alignment and genotyping errors inherent to conventional GWAS pipelines for polyploids.
Uncovering the Secrets of Sugarcane
With this framework in place, the fog surrounding the sugarcane genome began to lift. By providing a high-quality phased reference genome for sugarcane and analyzing it alongside the re-sequencing data of 981 diverse sugarcane accessions, we definitively confirmed the foundational contribution of the "King of Sugarcane". We found that more than 95% of modern cultivars share extensive genetic segments with POJ2878, and we successfully traced the evolutionary path of the sugarcane. Crucially, our framework allowed us to investigate the genetic basis of sugarcane's high sugar yield. Sugarcane stores its sucrose in specialized compartments within the stem “parenchyma cells”. Using our polyploid GWAS pipeline (KMERIA), we successfully identified genetic loci associated with parenchyma cell size and sucrose storage capacity. This included pinpointing the ShSUT2 gene, a sucrose transporter. We functionally validated that manipulating this gene can significantly increase parenchyma cell size, directly impacting the plant's storage capacity.
Looking Ahead
For a long time, the complexity of polyploid genomes made it highly challenging to pinpoint the exact genes responsible for valuable agricultural traits. Without reliable molecular targets, modern molecular breeding remained out of reach, forcing breeders to rely heavily on traditional, time-consuming methods. By developing a framework that accurately phases genomes, estimates allele dosage, and quantifies allele-specific expression, we hope to have provided a clearer path for polyploid research.
The insights gained from assembling the POJ2878 genome and mapping the genetics of sugar storage lay a firm technical and theoretical foundation for the molecular breeding of sugarcane. More importantly, the computational framework we established is not exclusive to sugarcane. We believe these tools will help researchers decode the genetic architecture of other vital polyploid crops, accelerating the development of more resilient and productive agricultural systems for the future.
Follow the Topic
-
Nature
A weekly international journal publishing the finest peer-reviewed research in all fields of science and technology on the basis of its originality, importance, interdisciplinary interest, timeliness, accessibility, elegance and surprising conclusions.

Related Collections
With Collections, you can get published faster and increase your visibility.
Carbon Dioxide Removal
Publishing Model: Hybrid
Deadline: Jan 16, 2027



Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in