How Emotional Discrepancy Stopped Looking Like Error
Published in Social Sciences and Computational Sciences

For years, one sentence kept returning in clinical and interpersonal settings:
“I’m fine.”
The people producing the most composed language were often the ones carrying the heaviest emotional load.
Existing frameworks could describe this psychologically. None could place it on a coordinate.
The turning point came when discrepancy stopped looking like residual error.
What the existing instruments could not see
Emotion regulation research described the process.
Psychoanalysis described the symbolic gap.
Sentiment analysis quantified affect.
None of them measured the geometry between narrative structure and emotional intensity.
In early modelling work, the discrepancy between the structural complexity of a narrative and the intensity of expressed affect repeatedly appeared as a leftover quantity, something to be minimised before the “real” analysis began.
But the pattern persisted too consistently to dismiss.
Some writers produced structurally elaborate narratives with flattened affect. Others compressed intense affect into sparse language. The discrepancy was not behaving like random variance.
It behaved like structure.
The methodological shift
The study therefore treated discrepancy itself as a variable.
Each narrative was scored independently on two 0–10 scales:
- Narrative complexity (N)
- Expressed affective intensity (A)
Their discrepancy, D = N − A, was preserved as a coordinate rather than collapsed into noise.
Across 351,734 anonymous relationship narratives, the Pearson correlation between N and A was 0.009.
Statistically indistinguishable from zero.
Stronger emotion did not reliably produce more elaborate language.
More elaborate language did not reliably carry stronger affect.
The two axes were doing different work.
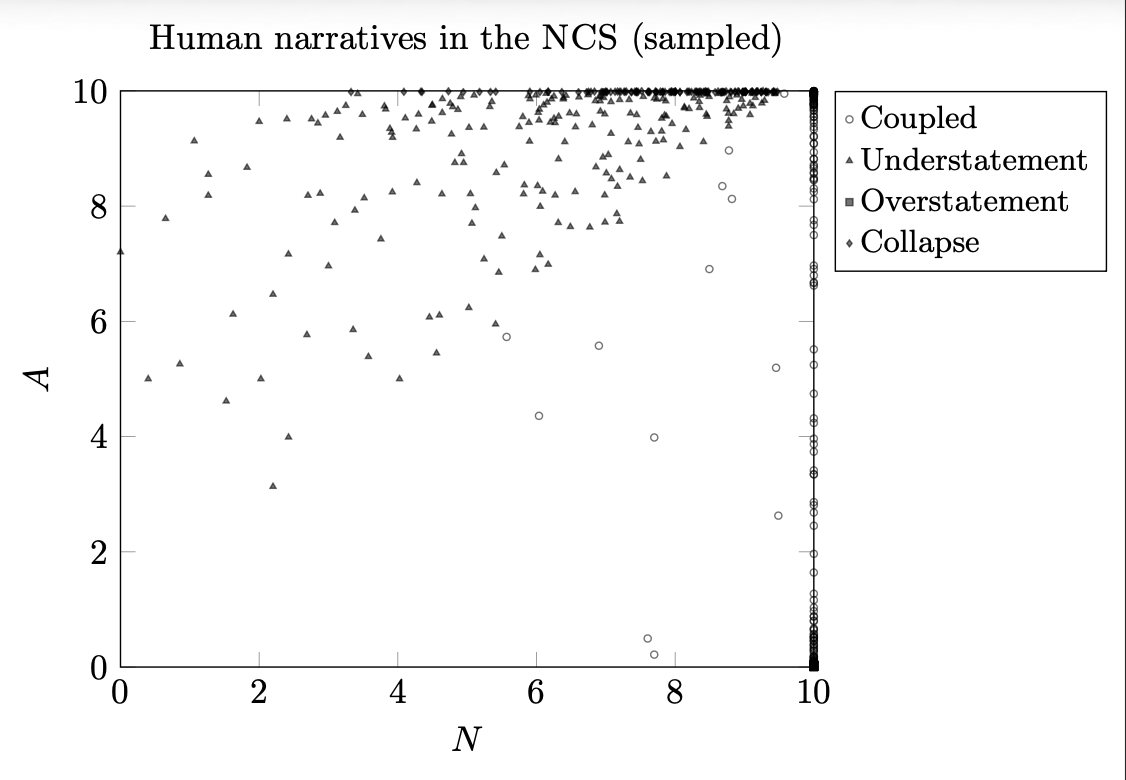
 and affective intensity (A) projected on the full expressive plane, showing the emergence of four stable regions.")
When the geometry appeared
Once plotted on the full N × A plane, the structure appeared immediately.
Most narratives occupied a dense central region later termed coupled expression.
But three additional regions emerged consistently across subsamples and threshold perturbations:
- Strategic understatement
- Strategic overstatement
- Collapse
These regions were not theoretically imposed categories.
They emerged from the density structure of the data itself.
The most striking moment was not the clustering.
It was the recognition that affectively flattened language was not randomly distributed across the plane.
The field had spent decades treating discrepancy as something communication should minimise.
The data suggested discrepancy was one of the things humans were using.
The RLHF comparison
The comparison with aligned language models entered later and unexpectedly became one of the paper’s most consequential findings.
Using matched prompts and identical feature extraction procedures, an RLHF-aligned language model was projected into the same coordinate system.
The model occupied an expressive region approximately 1.70× narrower than the human distribution.
The contraction was not uniform.
The model rarely entered regions associated with extreme discrepancy, including strategic understatement and collapse, where affective intensity and narrative scaffolding separate most sharply.
This is not evidence that RLHF alone produces the contraction.
But it does suggest that aligned systems, as currently deployed, do not adequately reach parts of the human affective plane.
Why this matters now
Recent work has shown that alignment may compress output and conceptual diversity.
This work points toward another axis:
Affective expressive geometry.
Not simply what systems can say.
Which regions of human expression remain reachable inside the system at all.
That distinction increasingly matters outside research settings.
The EU AI Act’s Article 5(1)(f), which entered into force in February 2025, prohibits certain forms of workplace and educational emotion recognition.
Yet current governance frameworks define prohibited inference practices more clearly than expressive freedom itself.
The discrepancy coordinate introduced here offers one possible way to begin operationalising that missing layer.
Closing
A system can become progressively more accurate inside the expressive region it already occupies while continuing to leave other regions of human expression structurally unreachable.
The study began as an attempt to measure emotional discrepancy.
It ended by suggesting that discrepancy itself may be one of the hidden organisational principles of human expression, and one that current aligned systems still struggle to preserve.
Reference
Kim, R. S. (2026). Narrative–affect discrepancy as a regulated degree of freedom in 351,734 relationship narratives. PLOS ONE, 21(5), e0348715. https://doi.org/10.1371/journal.pone.0348715
Ryan Sangbaek Kim is the founding director and principal investigator of the Ryan Research Institute (RRI), an independent institute based in Paris. Working across affective neuroscience, theoretical psychology, philosophy of mind, AI ethics, and law, he has developed a sustained interdisciplinary research program on the interpretation, suppression, and governance of emotion in human and machine systems.
He is best known for introducing Affective Sovereignty, a socio-technical design right that locates the person as the final interpreter of his or her own emotional life under conditions of computational mediation. His broader body of work includes the concepts of Affective Suppression Fatigue (ASF), Algorithmic Affective Blunting (AAB), and Predictive Emotional Self-Modeling (PESAM), through which he integrates computational formalism, phenomenological inquiry, and regulatory thought.
His work moves across academic research, public writing, and emotion-centered design, guided by the view that scholarship, culture, and technological form are not separate domains but continuous sites of interpretation.
Follow the Topic
Introducing: Social Science Matters
Social Science Matters is a campaign from the team at Palgrave Macmillan that aims to increase the visibility and impact of the social sciences
Continue reading announcement




Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in