Identifying and Mitigating Systematic Bias in Federated Learning for Biomedical Images: The MyThisYourThat Approach
Published in Computational Sciences and Biomedical Research

Artificial intelligence (AI) holds significant potential in medical applications, particularly in the analysis of biomedical imaging data. However, privacy concerns and the distributed nature of medical data across various institutions present major challenges for AI development. Federated Learning (FL), a distributed collaborative approach, offers a solution by allowing multiple data owners (clients) to jointly train a model without sharing their data. Despite the promise of FL, challenges such as low model interpretability and poor data interoperability due to hidden biases remain. Our work titled "MyThisYourThat for Interpretable Identification of Systematic Bias in Federated Learning for Biomedical Images" addresses these issues through an innovative approach that adapts a prototypical part learning network to the FL setting.
The Challenges in Federated Learning for Medical Data
Federated Learning allows collaborative model training while preserving data privacy, making it particularly appealing for sensitive biomedical imaging data. However, the typical FL process can introduce challenges:
- Low Interpretability: FL models, often based on complex deep learning architectures, are inherently black-box in nature, meaning that their decision-making process is difficult to understand and trust.
- Poor Data Interoperability: Systematic biases, such as institutional-specific artifacts or demographic imbalances, can lead to a model learning incorrect associations. For example, a model might incorrectly associate a hospital logo with a particular diagnosis due to its frequent appearance in certain cases.
These challenges undermine the reliability and clinical applicability of FL models in medical practice.
Introducing MyThisYourThat (MyTH)
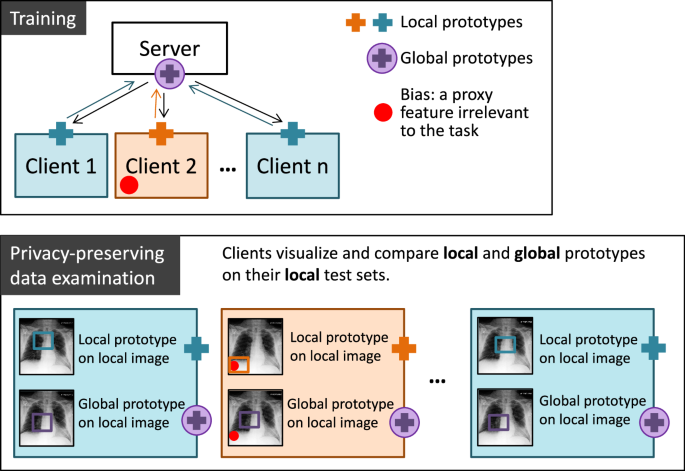
The MyTH approach leverages an interpretable prototypical part learning network, ProtoPNet, adapted to a federated setting to address these issues. ProtoPNet is designed to use human-interpretable prototypes for classification, making the decision-making process of the model more transparent. MyTH extends this approach by allowing clients in a federated setting to visualize and compare the prototypes learned on their local data against the global prototypes aggregated from all clients. This comparison enables the identification of data biases in a visually interpretable and privacy-preserving manner.
Methodology
In MyTH, each client learns local prototypes on their own dataset and then shares these prototypes with a central server. The server aggregates these prototypes to form global prototypes, which are sent back to the clients. This process allows clients to:
- Visualize and compare the local and global prototypes on their local data to identify differences that may indicate data bias.
- Assess how the model has generalized across different datasets without sharing the actual data.
This approach was demonstrated using a benchmark dataset of chest X-rays, focusing on two conditions: cardiomegaly (enlarged heart) and pleural effusion (fluid in the pleural cavity). The figure below gives a schematic overview of our model.
Results: Identifying and Understanding Bias
Unbiased Setting: In the unbiased setting, models trained collaboratively using federated learning performed comparably to centralized models, achieving balanced accuracies of 74.14% for cardiomegaly and 74.08% for pleural effusion. This indicates that the FL setting, when properly configured, can match the performance of traditional centralized models without compromising data privacy. The prototypes learned in the unbiased setting represent meaningful class-characteristic features such as an enlarged heart for cardiomegaly class and a lower part of the lungs for pleural effusion class (see figure below).
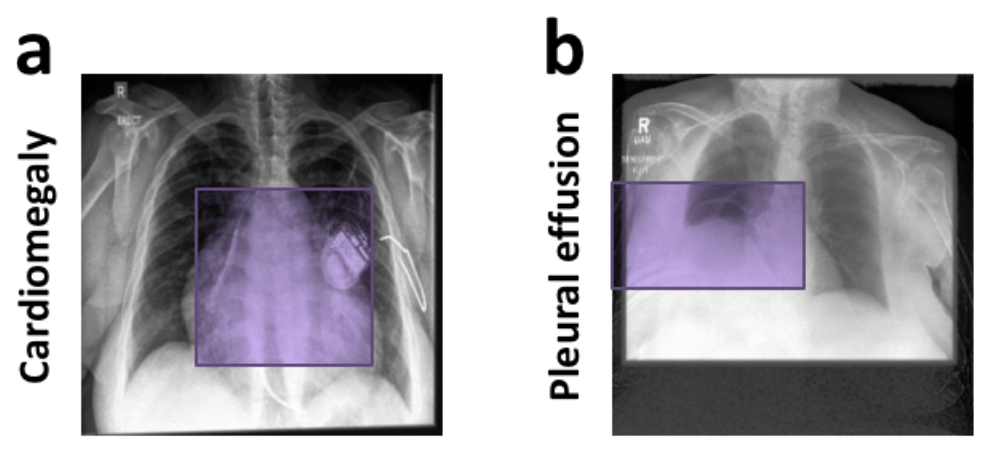
Prototypes learned in an unbiased setting. Examples of prototypical parts learned by global models in an unbiased FL setting for cardiomegaly (a) and pleural effusion (b) classes.
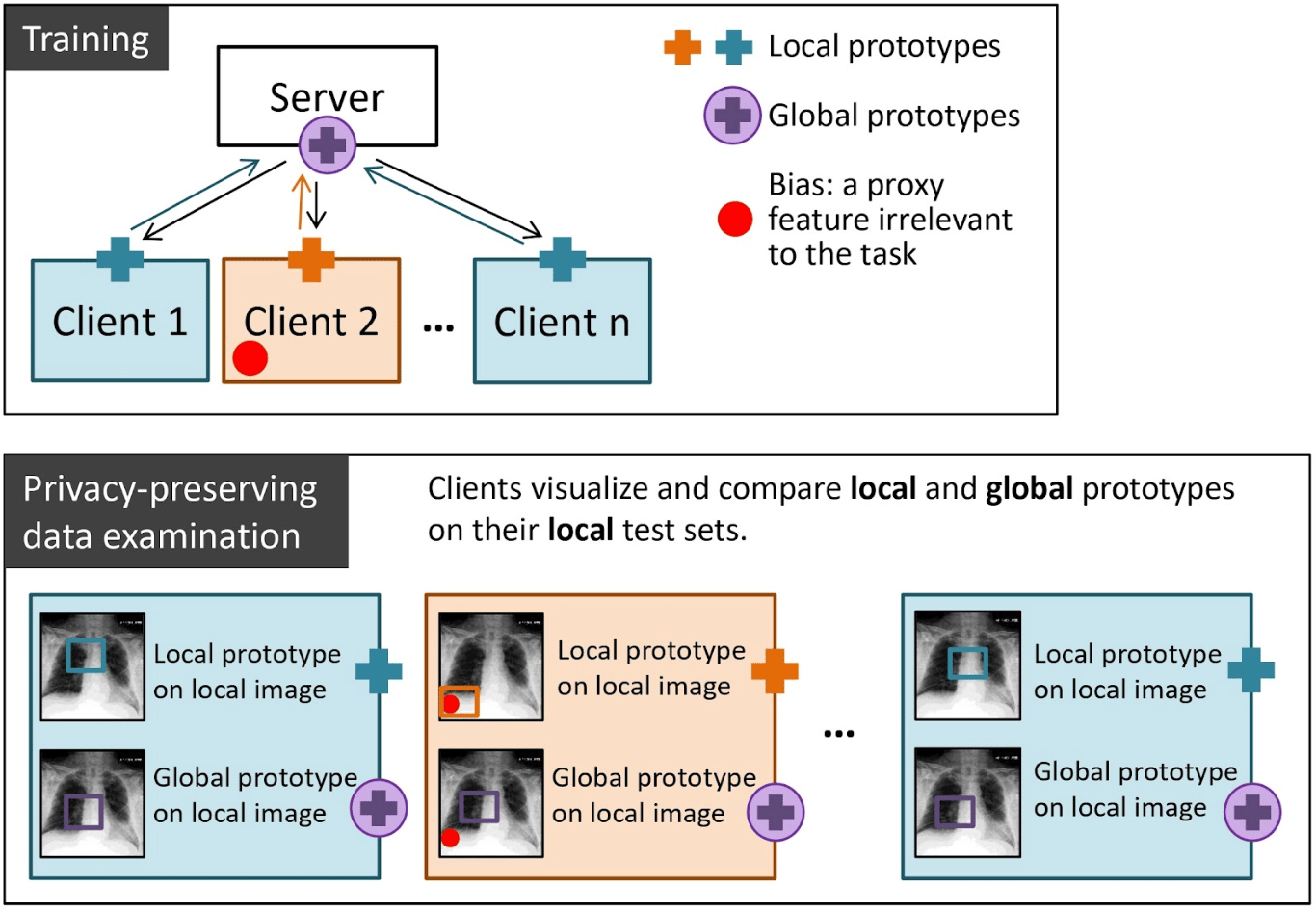
Biased Setting: In the biased setting, MyTH effectively highlighted the presence of biases through prototype visualization. For instance, one client was systematically biased by introducing a visual artifact (e.g., an emoji or chest drains) associated with positive cases of a condition. This bias led to the models relying on these irrelevant features for classification, which was revealed by significant differences between the local and global prototypes.
- Synthetic Bias: When a red emoji was added to the images of a positive class in cardiomegaly classification, the local model achieved 100% accuracy on the biased data but failed (50% accuracy) on unbiased data, indicating a reliance on the emoji rather than the actual pathological features. In this case, the difference between the local and global prototypes visualized on a biased client image is particularly outstanding.
- Real-World Bias: In the pleural effusion task, chest drains, which are frequently associated with effusion treatment, were introduced as a bias. Models trained with this bias relied on the presence of drains rather than the actual pleural effusion, as shown by the activation of irrelevant image regions. This finding is further supported by comparing the local and global prototypes on local images.
Examples of bias-identification with MyTH are shown in the figure below.
 and pleural effusion (b) classification. FL setting includes three unbiased and one biased clients. The difference between local (LM) and global (GM) prototypes signals about poor data interoperability in the federation.")
Implications and Future Directions
The MyTH approach provides a robust framework for understanding and mitigating biases in federated learning. By enabling a comparison of local and global prototypes, MyTH allows for the identification of biases without compromising the privacy of individual datasets. This has profound implications for deploying AI in medical settings, where trust and transparency are crucial.
Scalability and Real-World Applications: MyTH's capacity to visualize and interpret data biases extends beyond healthcare and can be applied to any collaborative AI setting where data privacy is a concern. Future work includes extending MyTH to more diverse and larger datasets and exploring its integration into real-world clinical workflows.
Enhancing Trust in AI: The interpretability offered by MyTH could play a crucial role in increasing the adoption of AI in clinical practice. By providing transparency to the decision-making process, MyTH helps clinicians to better understand and trust the models, which is essential for AI acceptance in healthcare.
Next Steps: Future research may focus on integrating MyTH with debiasing strategies, such as weighting prototypes differently based on their relevance, or using counterfactual explanations to further elucidate model decision-making. Additionally, we started expanding MyTH into a web-based DISCO application. Such adaptation would facilitate broader use and integration of our approach into existing AI platforms, supporting more effective federated learning across various fields.
Conclusion
MyTH represents a significant advancement in federated learning by addressing two of its most critical challenges: low interpretability and poor data interoperability. Through interpretable prototypes and privacy-preserving visualization techniques, MyTH not only identifies biases but also provides a means to understand and mitigate them, paving the way for more reliable and trustworthy AI models in healthcare and beyond.
Follow the Topic
-
npj Digital Medicine
An online open-access journal dedicated to publishing research in all aspects of digital medicine, including the clinical application and implementation of digital and mobile technologies, virtual healthcare, and novel applications of artificial intelligence and informatics.

Related Collections
With Collections, you can get published faster and increase your visibility.
Evaluating the Real-World Clinical Performance of AI
Publishing Model: Open Access
Deadline: Jun 03, 2026
Impact of Agentic AI on Care Delivery
Publishing Model: Open Access
Deadline: Jul 12, 2026




Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in