A single-cell view of pancreatic cancer diversity
Published in Cancer, Protocols & Methods, and Mathematics
Explore the Research
 ebi.ac.uk
ebi.ac.uk
BioStudies < The European Bioinformatics Institute < EMBL-EBI
BioStudies – one package for all the data supporting a study
Why we finally decided to look more closely at models we had been working with for years
Why this mattered to us
We have been working with patient-derived pancreatic cancer cells for a long time. These are living cells, taken from real patients, that we grow in the laboratory and use to study the disease and test treatments. Over the years we have published a lot using these models: drug response data, transcriptomic signatures, metabolic profiles. We thought we knew them well.
But there was always something uncomfortable sitting in the back of our minds. When we exposed these cells to a drug and some survived, we did not really know why. Were those survivors a distinct population that was always there? Or did they adapt? We were averaging signals across millions of cells and calling it a day. That felt increasingly inadequate.
Single-cell sequencing changed what was possible. And we had 41 well-characterised models sitting in our freezers. So we did it.
What we actually did and what nearly went wrong
The technical side was not straightforward. Processing 41 different cell cultures, each with its own growth characteristics and culture conditions, across two separate experimental batches introduced variability we had to be very careful about. There were moments where we were not sure the batch correction would work well enough to make the data usable across samples.
We chose SPLiT-seq over droplet-based technologies deliberately. Not because it is perfect, it has real limitations particularly around sequencing saturation, but because it was the only approach that let us profile this many samples in a way that was actually feasible. Science is full of trade-offs and this was one we made with open eyes.
The data processing took longer than expected. Quality control decisions that seem straightforward on paper become genuinely difficult when you are looking at 34,000 cells across two batches with different characteristics. Every threshold you set excludes real cells. That tension never fully goes away.
What we found and what surprised us
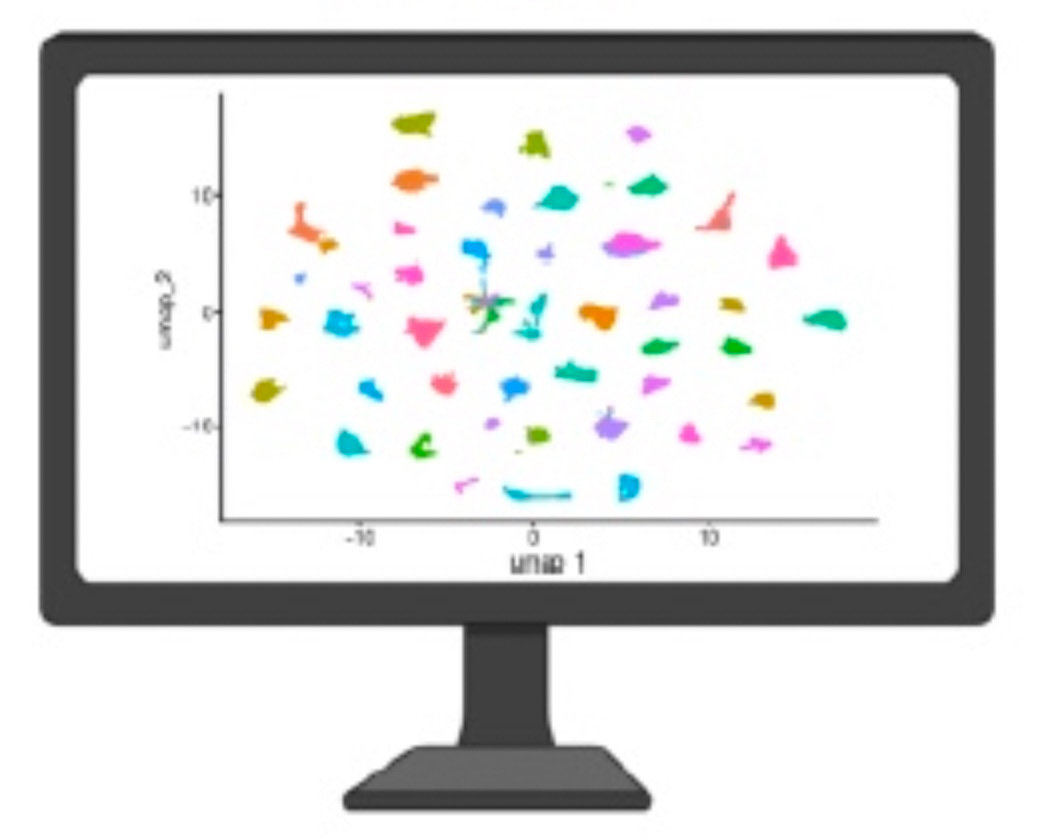
The heterogeneity was bigger than we expected. Not just between patients, which we anticipated, but within individual cultures from the same patient. Cells that should be relatively uniform, grown from a single source in controlled conditions, were showing dramatically different transcriptional states.
Some looked classical and well-differentiated. Others were clearly basal-like, the more aggressive phenotype associated with treatment resistance. And they were sitting side by side in the same flask.
That was the moment that shifted something for me. We had been treating these cultures as relatively homogeneous units in our drug response experiments. They are not. They never were. We just could not see it before.
What this is really for
We are making the full dataset publicly available: 30,593 cells, all the metadata, all the code. Not as an afterthought but as the main point.
There are very few large, well-characterised single-cell datasets from patient-derived pancreatic cancer models that cover the full disease spectrum, from localised to metastatic. Most single-cell work focuses on surgically resected tumours, which represent maybe 15% of patients. We wanted to offer something broader.
We hope others will use this to benchmark computational tools, explore cell states we have not looked at yet, and ask questions we have not thought of. That is not a polite thing to say at the end of a paper. We genuinely mean it.
What comes next and what we still do not know
The honest answer is that generating this dataset raised more questions than it answered.
We now want to know which of those cell states are associated with drug resistance. If a culture contains a subpopulation with a basal-like signature before treatment starts, does that predict poor response? Can we use that information prospectively?
Those experiments are underway. But they take time and the answers are not guaranteed.
What I can say is that after years of working with these models, I feel like we are finally seeing them properly. That alone felt worth doing.
Dataset: ArrayExpress E-MTAB-16856 https://www.ebi.ac.uk/biostudies/arrayexpress/studies/E-MTAB-16856
Code: zenodo.18273699 https://doi.org/10.5281/zenodo.18273699
References
- Chocoloff V. et al. Single-cell transcriptomic profiling of patient-derived pancreatic ductal adenocarcinoma primary cell cultures. Scientific Data (2026). https://www.ebi.ac.uk/biostudies/arrayexpress/studies/E-MTAB-16856
- Fraunhoffer N. et al. Development and validation of AI-assisted transcriptomic signatures to personalize adjuvant chemotherapy in patients with pancreatic ductal adenocarcinoma. Annals of Oncology, 35(9), 780-791 (2024). https://doi.org/10.1016/j.annonc.2024.06.010
- Fraunhoffer N. et al. Multi-omics data integration and modeling unravels new mechanisms for pancreatic cancer and improves prognostic prediction. NPJ Precision Oncology, 6, 57 (2022). https://doi.org/10.1038/s41698-022-00299-z
- Hwang W.L. et al. Single-nucleus and spatial transcriptome profiling of pancreatic cancer identifies multicellular dynamics associated with neoadjuvant treatment. Nature Genetics, 54, 1178-1191 (2022). https://doi.org/10.1038/s41588-022-01134-8
Follow the Topic
-
Scientific Data
A peer-reviewed, open-access journal for descriptions of datasets, and research that advances the sharing and reuse of scientific data.

Related Collections
With Collections, you can get published faster and increase your visibility.
Computer vision in plant science and agriculture
Publishing Model: Open Access
Deadline: Oct 10, 2026
Wearable and Computer Vision Data for Health and Behaviour Research
Publishing Model: Open Access
Deadline: Aug 08, 2026

Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in