Behind the Paper: Teaching AI to See What the Eye Cannot
Published in Computational Sciences
Can a deep learning model detect the subtle signs of diabetic retinopathy — before it's too late?
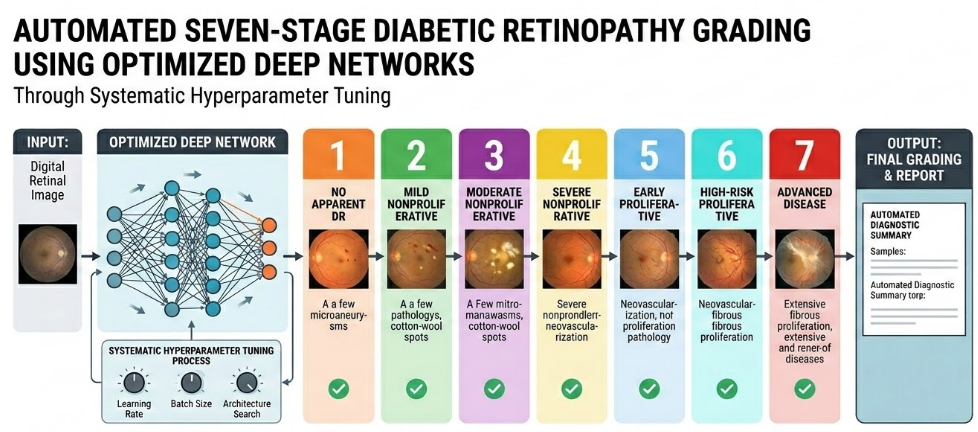
Diabetic retinopathy is one of those silent diseases that quietly steals vision while patients go about their daily lives. As a computer engineer working at the intersection of artificial intelligence and real-world problems, I've always been drawn to challenges where technology can make a tangible difference. This paper — Automated Seven-Stage Diabetic Retinopathy Grading Using Optimized Deep Networks Through Systematic Hyperparameter Tuning — represents my attempt to push automated DR diagnosis further than the conventional binary or five-stage approaches that dominate the literature.
Why Seven Stages Matter
Most existing studies simplify diabetic retinopathy into a binary problem (DR vs. no DR) or a five-class task. But clinicians don't think in binaries. The progression from mild non-proliferative DR to advanced proliferative DR involves subtle, gradual changes — each stage carrying different implications for treatment timing and strategy. A system that can distinguish all seven stages provides clinicians with the granular information they actually need to make decisions. That was the core motivation behind this work.
The Dataset Challenge
Working with a publicly available dataset of 1,437 fundus images sounds straightforward until you look at the class distribution. One of the most critical stages — Mild NPDR — had only six original images. Six. This is a common reality in medical imaging: the cases you most need to detect are often the rarest in your dataset.
Rather than giving up on fine-grained classification, I designed an extensive data augmentation pipeline — rotations, shifts, reflections, and scaling — that expanded the dataset to nearly 16,000 images while preserving the integrity of pathological features. The key was ensuring that augmentation didn't introduce artifacts that the model might learn instead of genuine disease markers.
Making the Invisible Visible with CLAHE
Fundus images can be deceptively uniform to the untrained eye. Subtle hemorrhages, tiny microaneurysms, and early exudates often hide in low-contrast regions. Before feeding images to any deep learning model, I applied Contrast Limited Adaptive Histogram Equalization (CLAHE) — a technique that enhances local contrast by processing the image in small tiles rather than globally. The difference was remarkable: features that were nearly invisible in the original images became clearly distinguishable after CLAHE preprocessing. This step alone significantly improved the model's ability to detect early-stage disease.
Letting the Algorithm Choose Its Own Architecture
Here's where the story gets interesting. Instead of hand-picking a deep learning architecture based on intuition or popularity, I used Optuna — a Bayesian optimization framework — to systematically evaluate nine pre-trained architectures: ResNet50, DenseNet121, EfficientNetB0, Xception, InceptionV3, VGG16, MobileNetV2, NASNetLarge, and InceptionResNetV2.
The winner? NASNetLarge — not the most commonly used architecture in DR literature, but the one that objectively performed best on this specific dataset. This finding reinforced an important lesson: the "best" model depends entirely on your data and task. There's no universal answer, and systematic search beats educated guessing.
Fine-Tuning with Grid Search
Once NASNetLarge was identified, I used Grid Search to exhaustively optimize hyperparameters: dropout rate, batch size, optimizer, learning rate, dense units, and the number of frozen layers. The optimal configuration — Adam optimizer, learning rate of 0.0001, dropout of 0.3, batch size of 64, and 713 frozen layers — achieved 98.39% classification accuracy, confirmed by 5-fold cross-validation at 98.50% ± 0.21%.
What struck me most was how sensitive the model was to batch size. Moving from 32 to 64 produced a dramatic accuracy jump, suggesting that the larger batch provided more stable gradient estimates during training — a detail easily overlooked but critical in practice.
Can We Trust What the Model Sees?
Accuracy numbers are important, but they don't tell the whole story. For a model to be clinically useful, we need to understand why it makes its decisions. Using saliency map visualization, I examined which regions of each fundus image most influenced the model's predictions.
The results were encouraging: in early DR stages, the model focused on central retinal areas around the optic disc and vasculature — exactly where microaneurysms and hemorrhages first appear. In advanced proliferative stages, attention patterns became more diffuse, reflecting the widespread retinal damage characteristic of severe disease. The model wasn't memorizing textures or dataset quirks; it was learning genuinely meaningful pathological features.
Honest Limitations
No study is without limitations, and I want to be transparent about mine. The Mild NPDR class, despite achieving perfect classification scores, started with only six original images. While augmentation addressed the imbalance effectively, there's always a risk that the model learned augmentation patterns rather than true disease features. External validation on independent datasets from different populations and imaging devices remains essential before any clinical deployment.
Looking Forward
This work demonstrates that systematic optimization — rather than manual trial-and-error — can push automated DR diagnosis to new levels of accuracy and reliability. But the real goal extends beyond numbers on a page. Diabetic retinopathy affects millions worldwide, and many patients in underserved regions lack access to specialist ophthalmologists. An AI system capable of reliable seven-stage grading could serve as a powerful screening tool, flagging patients who need urgent intervention and potentially saving countless eyes from preventable blindness.
The code and dataset are publicly available, and I hope this work encourages others to build upon it — with larger datasets, external validation, and ultimately, clinical trials that bring AI-assisted diagnosis from the laboratory to the clinic.
Yavuz Unal is a faculty member in the Department of Computer Engineering at Sinop University, Turkey. His research focuses on computer vision and deep learning applications in agricultural science, food quality assessment, and medical image analysis.
Read the full paper: Automated Seven-Stage Diabetic Retinopathy Grading Using Optimized Deep Networks Through Systematic Hyperparameter Tuning
Follow the Topic
-
Discover Computing
Previously Information Retrieval Journal. Discover Computing is an open access journal publishing research from all fields relevant to computer science.

Related Collections
With Collections, you can get published faster and increase your visibility.
5G-Enabled IoT for Smart Cities
This collection examines the pivotal role of 5G-enabled IoT technologies in transforming urban infrastructure and enhancing city management through advanced civil engineering practices. It highlights how these technologies contribute to smarter, more sustainable cities by improving connectivity, data management, and automation across various urban systems. Contributions will explore the integration of 5G and IoT to optimize resource management, increase the efficiency of public services, and enhance the sustainability and resilience of urban environments. The collection aims to provide a comprehensive analysis of the challenges and opportunities presented by these technologies in urban planning and civil engineering, offering insights into innovative solutions and future advancements.
This Collection supports and amplifies research related to SDG 9, SDG 11, and SDG 13.
Keywords: 5G Communications, Internet of Things, Smart Cities, Urban Infrastructure, Civil Engineering, Sustainable Development, Connectivity, Data Management, Urban Automation, Technological Integration
Publishing Model: Open Access
Deadline: Oct 31, 2026
Trustworthy and Explainable Intelligent Systems for Real-World Computing
This Collection focuses on trustworthy and explainable intelligent systems designed for real-world computing applications. As artificial intelligence and data-driven systems are increasingly deployed in critical domains such as healthcare, smart cities, industrial automation, and digital infrastructure, concerns related to transparency, robustness, fairness, and accountability have become central challenges.
The aim of this Collection is to bring together recent advances in explainable artificial intelligence (XAI), trustworthy machine learning, and responsible computing, with a strong emphasis on practical deployment and system-level perspectives rather than purely theoretical contributions. The Collection seeks to highlight methods, models, and frameworks that enhance human understanding, trust, and control over intelligent systems operating in real-world environments.
Specific areas of interest include, but are not limited to: interpretable and explainable models, robustness and reliability of intelligent systems, human-centered and human-in-the-loop computing, evaluation methodologies for trustworthy AI, ethical and responsible computing practices, and application-driven case studies demonstrating real-world impact. By providing a focused yet interdisciplinary forum, this Collection aims to foster high-quality contributions that bridge the gap between advanced computational methods and trustworthy deployment in practice.
This Collection supports and amplifies research related to SDG 9.
Keywords: Explainable Artificial Intelligence (XAI); Trustworthy Computing; Responsible AI; Interpretable Machine Learning; Human-Centered Computing; Robust Intelligent Systems; Ethical Computing; Real-World AI Applications
Publishing Model: Open Access
Deadline: Nov 20, 2026


Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in
I really liked this research. The CLAHE method helps show small details in the eye images that we can’t see easily. Also, letting the model choose its own structure is really cool.