Opioid Death Projections with AI-based Forecasts using Social Media Language
Published in Healthcare & Nursing


The United States has been attempting to tackle an opioid epidemic for over 20 years. At the same time, age-adjusted opioid-related deaths have increased by 350% from 1999 to 2020 [1]. One of the key challenges to the epidemic is that its driving force seemingly changes across time and communities. For example, at some points in time increases are thought largely due to prescription drug abuse and at other times it is cheap and readily available opioids (e.g. fentanyl) [2]. Ultimately, this leads to difficulties in predicting where and when the epidemic will next rise which makes implementing location-specific responses difficult.
AI-based language analyses, which have shown promise in cross-sectional (between-community) well-being assessments, may offer a new way to more accurately predict future (i.e. forecast) community-level overdose mortality. To investigate this, we develop and evaluate TrOP (Transformer for Opioid Prediction), a model for estimating future changes in opioid-related deaths of communities that uses community-specific social media language along with past opioid-related mortality data.
We find our proposed model was able to forecast yearly death rates with: 3% mean absolute percent error and within 1.15 deaths per 100,000 people. TrOP builds on recent advances in sequence modeling, namely transformer networks, to use changes in yearly language on Twitter and past opioid mortality to forecast the following year's mortality rates by county.
Dataset & Approach
We used language data derived from the County Tweet Lexical Bank (CTLB) [3]. This dataset contains word usage on Twitter collected from approximately 2,041 U.S. counties starting from 2011. We then build yearly topics (groupings of words that often appear together) for each county using data from 2011 - 2017.
Using this language data as a starting point, we then combined it with data queried from CDC Wonder [4] to gather the yearly opioid related deaths per county. After limiting our dataset to those counties that reported deaths to the CDC for every year from 2011 to 2017, we ended up with 357 counties. These 357 counties had a total population of 212 million people, covering 65% of the total US population as of 2017.
We build sequential (autoregressive) models with a focus on the transformer [5] architecture. Transformer based models have shown state-of-the-art performance in many NLP based tasks. Here, our sequence is the yearly language topics and opioid deaths per 100,000 configured to forecast future change in opioid death rates. This rate of change is then added into the previously observed value to finalize the predicted death rates per 100,000. We use the years 2011 - 2015 as training and evaluate our model’s ability to forecast years 2016 and 2017. Thus the model never sees the years it is tested on, simulating its application to new future years.
Results
Figure 1 shows the primary results of our evaluation of TrOP versus models based on historical rates for the communities and models utilizing community specific socio-economic indicators. We see that TrOP (Transformer for Opioid Prediction) with social media language input is able to achieve the lowest error of nearly 1 death per 100,000 on average when using language data.

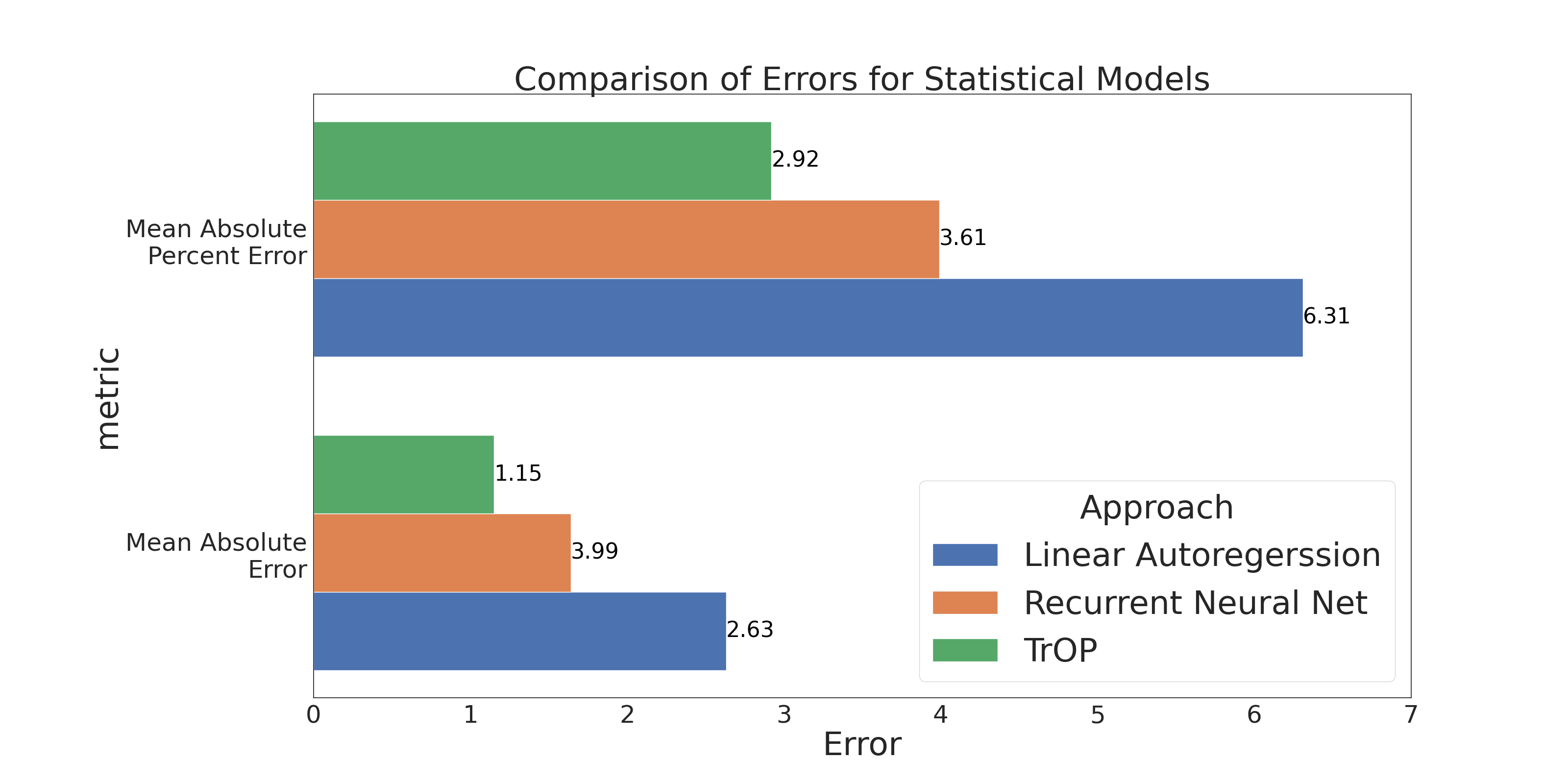
Figure 2 provides a greater breakdown of models and error metrics, including Mean Absolute Percent Error (MAPE) and Mean Absolute Error (MAE). Here, MAE is in deaths per 100,000. All models leverage 3 years of past history, which was found to be ideal. We compare TrOP to alternative time-series models, specifically a linear autoregressive (ridge) model and a deep learning recurrent neural network. TrOP continued to outperform other approaches, showing less than half the mean absolute error than even the recurrent model.
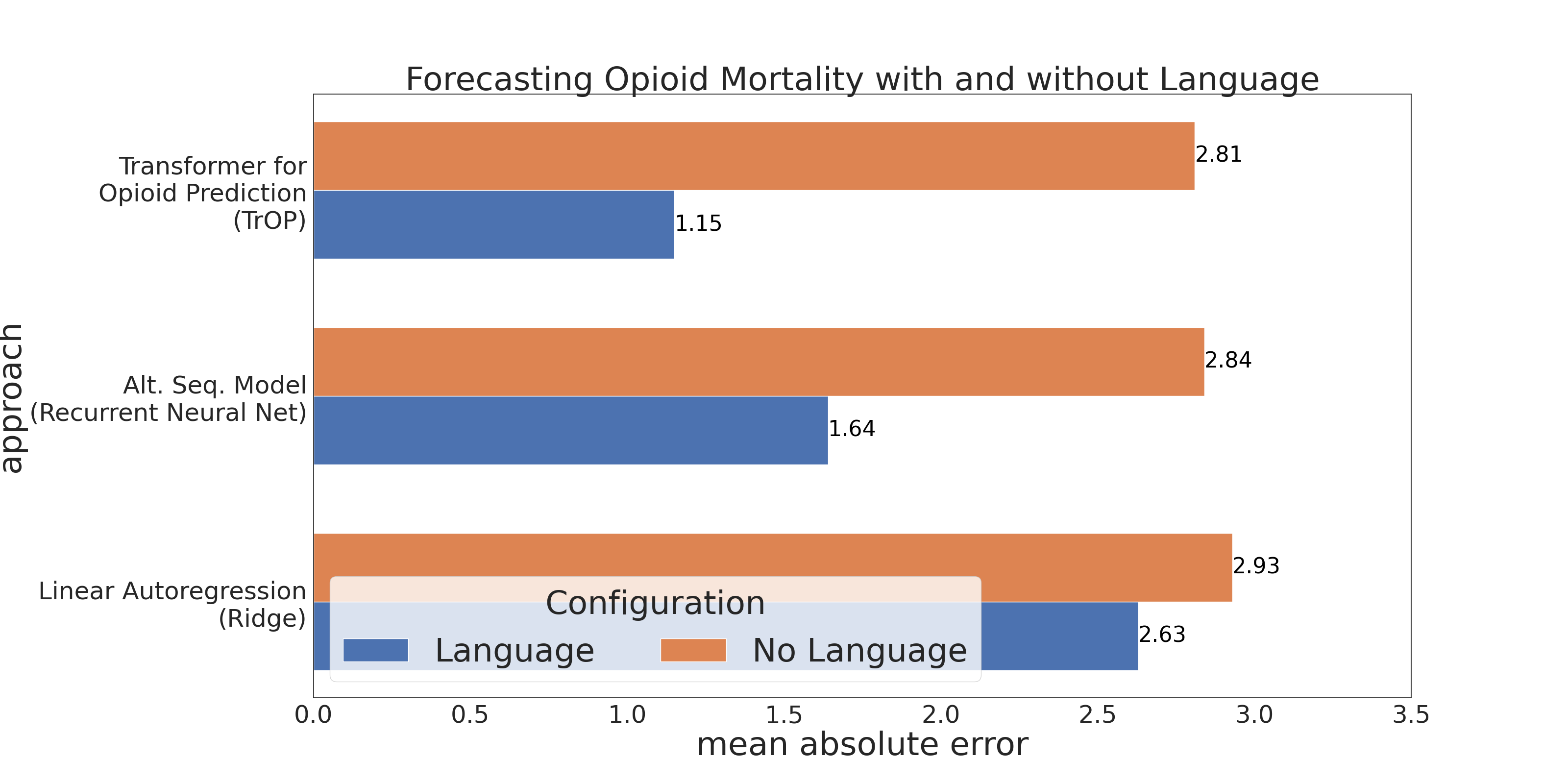
In figure 3, we compare the performance of TrOP and other proposed models when using knowledge of just past mortality rate (without language) as well as the inclusion of our yearly county topic features (with language). We found the language features to be informative for all sequential models, highlighting that changes in community language over time contain relevant signals for opioid abuse. Both deep learning (non-linear) models saw much bigger impact in predictive accuracy when language was included, ultimately suggesting that predictors of these yearly changes are complex, requiring community-level measures that capture more than just past rates and socio-economic indicators.
To visualize what changes in language are predictive of future opioid mortality we investigated the relationship between change in each of the topics that reliably predicted death rates. Figures 4 and 5 highlights topics that either decrease or increase, respectively, prior to increases in opioid death rates for 2016 and 2017. The displayed clusters were grouped by first examining the individual topics that have significance (p < .05) and then manually paired among other topic clouds that showed similarities. Each cluster of individual topics represents semantically similar language associated with opioid deaths.

As indicators of future decreases in mortality rates, we found discussions focused around positive events with a focus on holidays and travel. Use of positive language implies a sense of ``anti-despair`` and optimism. However, language indicative of future increases focused on more worldly events such as politics. While some topics may be perceived as empathetic they are often towards ideas that lean more toward community challenges (e.g. homelessness).

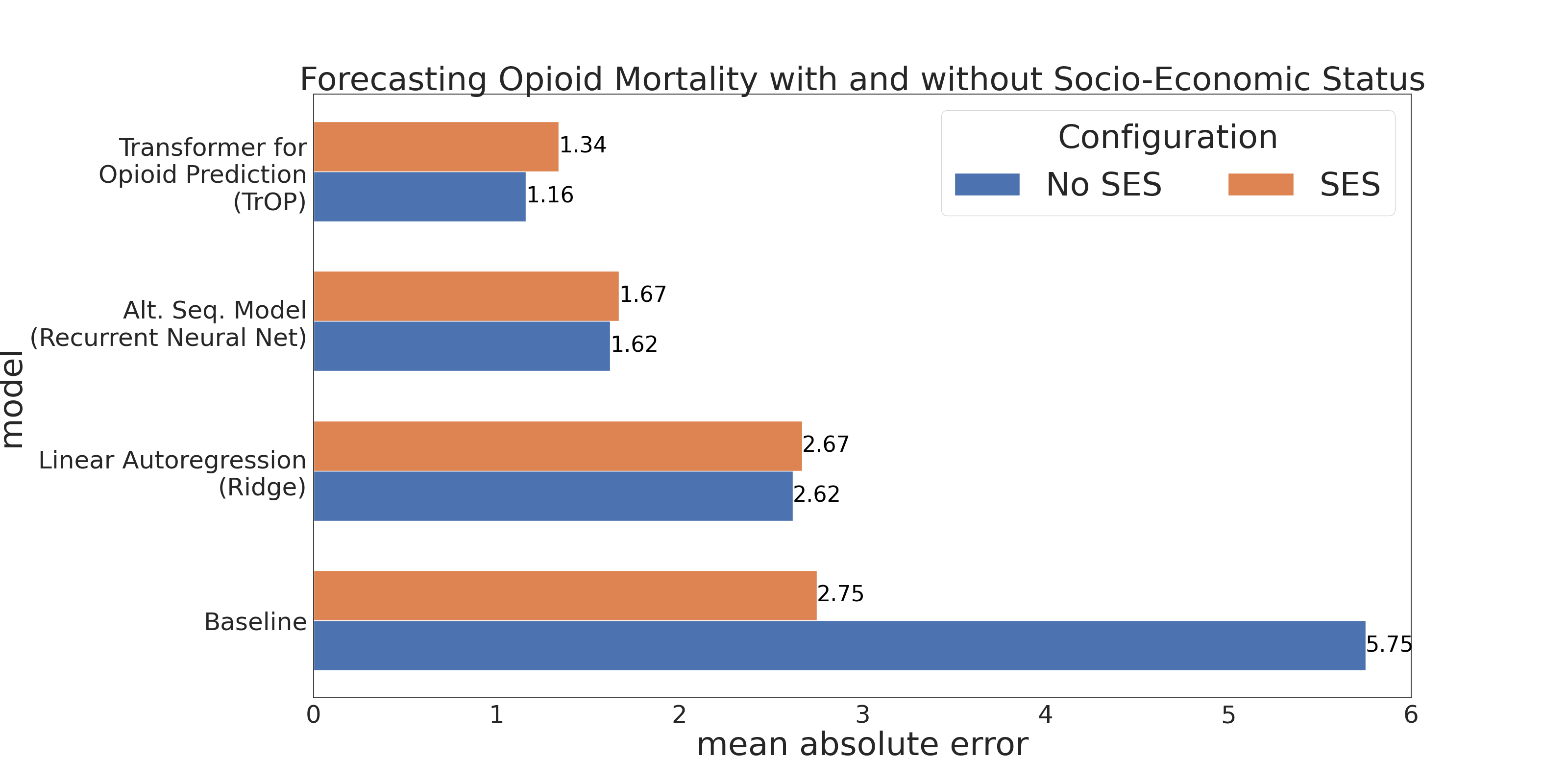
Traditionally, measures of socio-economic status (SES) are some of the strongest predictors of community-specific health outcomes. However, these variables are roughly static over short periods of time which we suspected makes them less powerful for tracking the dynamic and community-specific nature of the opioid epidemic. We include past knowledge of 7 socio-economic variables; log median household income, median age, percentage over 65, percent female, percent African American, percent high school graduate, and percent bachelors graduate. We show the results of our models compared to and combined with SES in Figure 6. Notably, the SES variables on their own were predictive beyond the non-SES baselines but in no situations were they able to contribute to any of the language based autoregressive models toward an improvement. Ultimately highlighting the utility of social media based features in terms of capturing covariance accounted for by SES.
Key Takeaways
- TrOP (Transformer for Opioid Prediction), trained over five years and evaluated over the next two, demonstrated state-of-the-art accuracy at predicting future county-specific opioid-related mortality.
- TrOP achieved a mean absolute error within 1.15 deaths per 100,000 people.
- We found that modeling changes in language on social media over time captures information above and beyond what one would traditionally expect from socio-economic variables.
-
Specific topics in language were predictive of community-specific changes:
- Discussion focused around anti-despair was predictive of future decreased rates
- Discussion of negative events was predictive of future increased rates
References
[1] Hedegaard, H., Miniño, A. M., Spencer, M. R. & Warner, M. Drug Overdose Deaths in the United States, 1999–2020. NCHS Data Brief, no. 394 (National Center for Health Statistics, Hyattsville, MD, 2020).
[2] Ciccarone, D. The rise of illicit fentanyls, stimulants and the fourth wave of the opioid overdose crisis. Curr. Opin. Psychiatry 34, 344–350 (2021).
[3] Giorgi, S. et al. The remarkable benefit of user-level aggregation for lexical-based population-level predictions. In Proc. 2018 Conference on Empirical Methods in Natural Language Processing 1167–1172 (Association for Computational Linguistics, Brussels, Belgium, 2018).
[4] Center for Disease Control (CDC). Underlying Cause of Death, 1999–2020 Request. https://wonder.cdc.gov/ucd-icd10.html (2022).
[5] Vaswani, A. et al. Attention is all you need. In Guyon, I., Luxburg, U. V., Bengio, S., Wallach, H., Fergus, R., Vishwanathanand, S., & Garnett, R. Advances in Neural Information Processing Systems 5998–6008 (Curran Associates, Inc., 2017)
Follow the Topic
-
npj Digital Medicine

An online open-access journal dedicated to publishing research in all aspects of digital medicine, including the clinical application and implementation of digital and mobile technologies, virtual healthcare, and novel applications of artificial intelligence and informatics.
Related Collections
With Collections, you can get published faster and increase your visibility.
Evaluating the Real-World Clinical Performance of AI
Publishing Model: Open Access
Deadline: Jun 03, 2026
Impact of Agentic AI on Care Delivery
Publishing Model: Open Access
Deadline: Jul 12, 2026



Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in