Reinforcement learning shapes economic preferences in 11 [very different] countries
Published in Neuroscience, Behavioural Sciences & Psychology, and Economics
In this study, we decided to use a series of value-based decision-making tasks to figure out the economic preferences of people from 11 distinct countries, representing a wide range of socioeconomic and cultural backgrounds. The kicker was that we asked participants to choose between the same options twice: once while having overt information on the actual value of each option (i.e., as in classic descriptive economics experiments), and once while having to figure out option values by themselves through trial and error (i.e., Reinforcement Learning). This gave us the opportunity to observe (1) how the value-scaling mechanisms that are key in determining economic preferences varied across cultures, and (2) how these fluctuations differed in description vs. experience-based choices. But why should psychologists, economists and policy-makers be concerned by this at all? Well, as it turns out, we do not make decisions the same way when we act based on information being fed to us vs. when we act based on our own experiences. Furthermore, our cultural background may play a huge role in determining our behavior, or absolutely none at all, depending on whether information on value is being acquired by description or by experience.
Reinforcement Learning & the Ubiquity of Value Scaling
Human reinforcement learning (RL) encompasses the sum of cognitive mechanisms and behaviors that allow us to learn through trial and error and act upon our acquired experience. The study of RL is often conducted by constituting computational models that break down complex decision-making problems, like foraging, navigation, and economic choices, into basic elements such as actions, states, and rewards. Despite its wide-reaching implications for areas like mental health, education, and economics, there has been little cross-cultural research on how RL processes operate in different cultural contexts. RL inherently aims to maximize rewards and minimize penalties, yet research shows that RL decision-making often strays from ideal statistical models. Exploring whether these deviations are cultural or universal can shed light on the limits of human decision-making and the rationality of human agents altogether.
In particular, the concept of outcome context-dependence has become a significant focus in the study of human reinforcement learning. Recent research has repeatedly shown that the subjective value of options results from the re-scaling of their absolute value within the range of the values of all other available options, through a process akin to range normalization.
This tendency to adjust the perceived value of outcomes based on surrounding information is thought to be a byproduct of the brain's efficient information processing strategies. This approach to coding information is similar to mechanisms observed in perceptual decision-making, suggesting it might be a fundamental aspect of neural computation. Studies across different species have shown consistent patterns of range value adaptation, supporting this idea and pointing to a potentially universal principle of brain function.
Value Scaling & the Problem of Rational Choice
But why should we care about this value-scaling mechanism in the first place? One practical impact of outcome context-dependence in RL is its potential to lead to suboptimal decisions. In certain learning scenarios, individuals may assign higher subjective values to objectively inferior options because of how these options are framed within the local reward context. This can result in choices that do not maximize potential rewards, and sometimes actively diminish them. Think for example of someone choosing to eat at a questionable seafood restaurant, just because it is better than the dreadful taco place around the corner, instead of just going to an average joint two blocks away that doesn’t really stand out at all (but is objectively better). If this form of context dependence is indeed a fundamental computational feature of the human brain, its influence on decision-making should be consistent across diverse populations and cultures. One of the main goals of our present work was to determine if this was indeed the case, as understanding (and planning ahead for) the contingencies that stem from this form of reasoning could prove essential to understand how we make decisions in ecological environments where learning is mainly experiential.
WEIRD Problems Call for Risky Solutions
The two other main goals of our study were deeply intertwined. On the one hand, the vast majority of efforts to uncover the cognitive underpinnings of range-value adaptation to date had been conducted in samples from Western (should we just change that to “White” already?), Educated, Industrialized, Rich and Democratic countries (i.e. WEIRD countries). This is a big problem, not just in RL but in cognitive science in general, because it compromises the representativity and reproducibility of results across the board, biasing research and public opinion to take this fairly weird human [lowercase intended] as the default human. We considered that it was about time we had an actual representative benchmark for range-value adaptation in RL that transcended the WEIRD sphere.
On the other hand, a key step in figuring out whether range-value adaptation in RL is a hard-coded decision mechanism is to check whether we can elicit this value-scaling effect across distinct groups of people, with consistently different cultural and socioeconomic profiles. Incidentally, in classic economic value-based decision-making paradigms, choice values are explicitly and overtly disclosed to people rather than learned through reinforcement. As a result, we have found that participants use this information to reshape option values as a function of their utility, which is a somewhat deeper, multidimensional, subjective form of value. Evidence shows that one of the main drivers of utility, and thus a main mechanism for value-scaling, are individual stances with regard to risk. For example, a 1% chance of winning 100 million dollars is objectively better than a 50% chance of winning 50 thousand dollars in terms of expected value (i.e. 1 million vs 25k). Yet, if your tolerance to not getting any rewards is low enough (e.g. you have a lot of bills to pay, like right now), the second option will seem as the better choice and have a higher utility in your book. It is not surprising then for evidence to show time and time again that risk preferences change dramatically with cultural and socioeconomic variables![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]() .
.
If value scaling mechanisms in descriptive paradigms (i.e. classic disclosure economic experiment) are known to change with culture, this is all the more reason to evaluate if value-scaling mechanisms in experiential settings (i.e. reinforcement learning) won't fluctuate with culture and societal varables as well. Therefore, by testing the same value-based decision problems in both descriptive and experiential settings across different countries, we determined not only if RL own’s value-scaling mechanisms were universal, but also if it was moderated at all by cultural differences, and if risk aversion was at all related to it. This last bit was quite important, because an independence of the scaling mechanisms corresponding to description and experience would constitute a clear instance of the experience-description gap![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]() , and evidence in favor of the existence of separate mechanisms arbitrating these processes.
, and evidence in favor of the existence of separate mechanisms arbitrating these processes.
Range-Value Adaptation Processes (and the Experience-description Gap) Are Not WEIRD
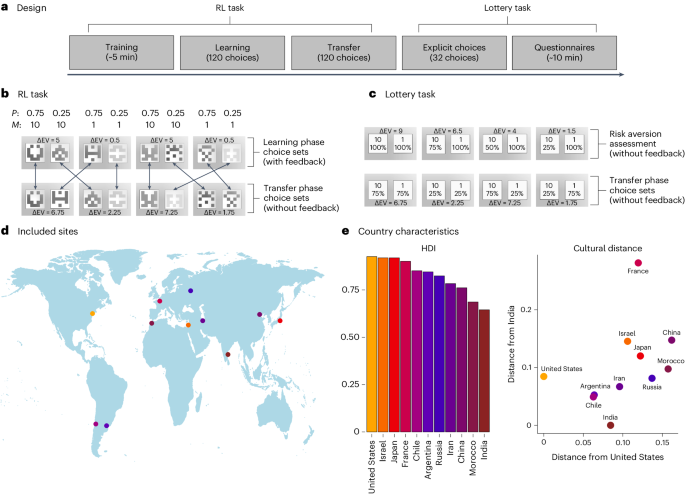
The figure below outlines our paradigm and our results. We selected samples from 11 countries spread along the Human Development Index (Argentina, Iran, Russia, Japan, China, India, Israel, Chile, Morocco, France and the United States). We asked participants to solve value-based decision making tasks sporting the same decision contexts, but in two different modalities, where option value had to be learned by experience or was acquired by description. Our results showed a clear impact of culture on risk aversion for the descriptive task. We also found clean-cut evidence of range-value adaptation in RL for all countries, manifested here as identical performances for choices in big and small reward decision contexts. Further, our computational model successfully captured value-scaling processes in both modalities (as seen by the quality of fit and simulations), and clearly expressed their independence (as seen by the bounds of the ⍵ reward-scaling parameter). Namely, value reshaping due to risk aversion varied significantly across countries, while value scaling due to range adaptation remained nearly monotonic. Interestingly, the intervals of ⍵ for each of these process were markedly different in terms of magnitude. Overall, these results confirmed the cross-cultural stability and reliability of range-value adaptation in RL, its independence from risk aversion mechanisms, and ultimately revealed yet another instance of the experience-description gap.
Outline of our paradigm and findings. 1. Samples from 11 markedly different countries. 2 Participants had to complete description-based and RL-based value-based decision-making tasks. 3. We found marked evidence of both risk-aversion value-scaling (akin to utility) and range-adaptation. 4. The value-scaling dimension of our models (represented by the ⍵ free parameter in the model) adequately captured risk-aversion (variable across countries) and properly differentiated it from range-value adaptation (more stable; on a different space altogether).
Traditionally, policies and interventions in behavioral economics have relied heavily on description-based choice models. However, our research suggests that experience-based decision models are considerably more consistent across different cultures and may reflect deep-seated aspects of human cognition. If further research confirms and extends these patterns to other tasks and contexts, it could underline the importance of incorporating experience-based decision models more broadly in the design of public policies. This could lead to more effective and culturally sensitive policy frameworks that align better with how people naturally make decisions based on their experiences.
Follow the Topic
-
Nature Human Behaviour

Drawing from a broad spectrum of social, biological, health, and physical science disciplines, this journal publishes research of outstanding significance into any aspect of individual or collective human behaviour.
Related Collections
With Collections, you can get published faster and increase your visibility.
Digital Media and Mental Health
Publishing Model: Hybrid
Deadline: Apr 15, 2026
Basic Psychological Needs and Well-Being
Publishing Model: Hybrid
Deadline: Nov 27, 2026





Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in