We Taught an AI to Bridge the Genomic and Chemical Worlds of Microbes
Published in Chemistry
We spent a lot of time thinking about microbes as cellular factories.
Most people think of bacteria as pathogens. But if you look at them the way we do, through the lens of their genomes, you see something remarkable. Microbes have been engineering molecules for billions of years. The antibiotics we rely on, the immunosuppressants that make organ transplants possible, many of the most powerful drugs in existence are all originally products of microbial chemistry.
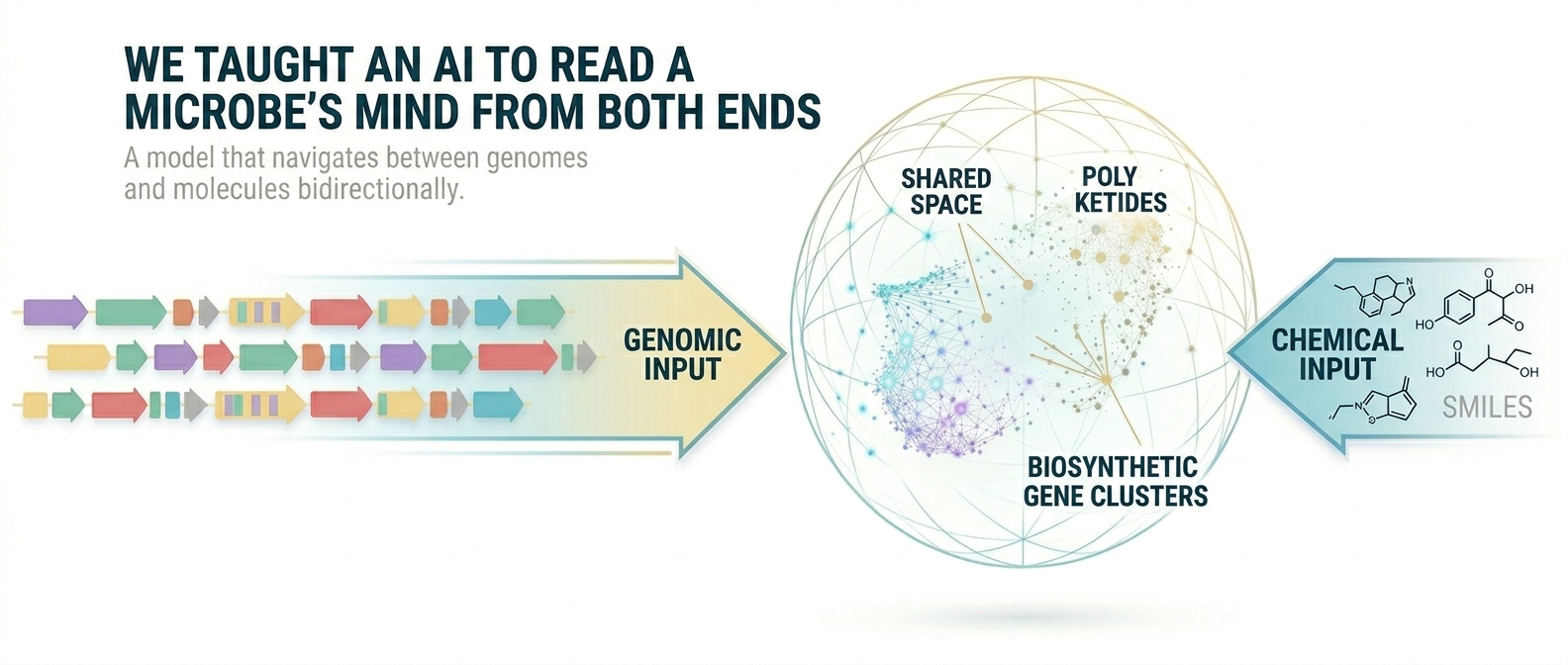
Inside every microbial genome are dedicated gene clusters that function like molecular factories. We call them biosynthetic gene clusters, or BGCs. Each one encodes the machinery to build a specific chemical compound. The problem we kept running into: we had gotten very good at finding these factories in genomic data, but if we have a molecule of interest to make, we still cannot easily find the factory for it.
That retrobiosynthesis gap bothered us.
Two Languages, One Organism
Here is the tension we were sitting with. You can describe a microbe in two fundamentally different ways.
The genomic view treats it as an information system, a sequence of instructions. Tools like antiSMASH do this well. Take a novel BGC and you can confidently classify it as probably a polyketide or a terpene.
The chemical view treats the cell as a bag of molecules, the actual compounds it produces and releases. This is the language of chemistry: molecular structures, SMILES strings, bioactivity.
These two languages had never been properly unified. A genomicist and a chemist looking at the same organism were, in some sense, reading different books about the same thing. We wanted to build the translation layer between them.
A Database the Community Built Over Decades
Once we framed it as a translation problem, we realised we needed a bilingual dictionary. And it turned out the research community had already built one, painstakingly, over many years.
MIBiG, the Minimum Information about a Biosynthetic Gene cluster database, is a curated collection of BGCs paired with the exact chemical structures of their products. Not predicted structures, not inferred ones. Experimentally confirmed, by generations of wet lab scientists around the world who grew organisms, extracted metabolites, and validated the links one by one. It represents an enormous collective investment from a global community of natural product researchers who understood, long before machine learning arrived, that this kind of paired ground truth would one day be invaluable. Version 4.0 contains over 3,400 such matched pairs.
In machine learning terms, this is vanishingly rare: a high-quality, experimentally grounded dataset linking two completely different modalities of biological information. When we looked at MIBiG through the lens of cross-modal alignment, its potential became immediately clear. This dataset was precisely the foundation we needed, and the community that built it had given us an extraordinary gift.
One Shared Mathematical Space
The core idea we borrowed from was CLIP, OpenAI's 2021 model that maps images and text into the same vector space. Give it a photo of a dog and the word "dog," and both produce nearby vectors. We asked: could you do this for BGCs and molecules?
Our framework, BCCoE (BGC-Chemical Co-Embedding), does exactly that. We project both a gene cluster and a chemical structure into a shared 64-dimensional mathematical space, trained so that known BGC-compound pairs end up close together and unrelated pairs end up far apart.
For the genomic side, we used BiGCARP, a foundation model that represents BGCs as chains of functional protein domains. For the chemical side, MoLFormer, a transformer trained on over a billion SMILES strings. Both produce rich embeddings, but they initially live in completely separate mathematical universes with no shared coordinates.
The alignment step is where the real work happens. We trained two lightweight encoder networks on MIBiG pairs using N-pair loss, simultaneously pulling matching pairs together while pushing non-matches apart. After training, something satisfying emerged: the biology started showing through in the geometry. Polyketide clusters migrated toward polyketide compounds. NRPS clusters settled near their peptide products. The co-embedding space had developed a structure that mirrored the underlying biochemistry.
The Direction Nobody Had Tried
What excited us most was not the forward direction, genome to molecule, though BCCoE does that well. It was the reverse.
Feed BCCoE a target molecule and ask: which gene cluster in nature is most likely responsible for making something like this? The model embeds the compound and retrieves the nearest BGCs from a genomic database, ranked, in seconds, before a single experiment. This inverse direction reframes drug discovery in a way that feels genuinely new. Instead of "what does this genome make?", you can ask "what makes this?", starting from a bioactive molecule and working backwards to the biology.
What the Results Told Us
We tested BCCoE across three settings of increasing difficulty. In standard cross-validation, we retrieved the correct compound in the top-10 results 32.9% of the time, versus 21.9% for the best non-alignment baseline. When we held out entire product classes the model had never seen during training, it still outperformed all baselines by 17 to 20 times over random.
What We Think It Means
The fact that our model generalises, finding correct relationships in chemistry it was never trained on, tells us something we find genuinely exciting. The connection between a gene cluster's architecture and its chemical output is not arbitrary. There is a learnable structure to how evolution encoded molecular function into DNA, and it is coherent enough that a model trained on a few thousand pairs can extrapolate well beyond them.
The co-embedding space is, in some sense, a map of that hidden logic. A way of reading life from both ends of the same story, simultaneously. We think that is just the beginning of what it can do.
Follow the Topic
-
Scientific Reports
An open access journal publishing original research from across all areas of the natural sciences, psychology, medicine and engineering.

Related Collections
With Collections, you can get published faster and increase your visibility.
Infectious disease diagnostics
Publishing Model: Open Access
Deadline: Sep 23, 2026
Healthy Aging
Publishing Model: Open Access
Deadline: Dec 31, 2026




Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in