When Data Goes Missing: How Genetics Shapes Who Gets Studied in Infant Brain Research
Published in Social Sciences, Research Data, and Behavioural Sciences & Psychology
Anyone who has tried to photograph a baby knows the challenge. The perfect moment passes in seconds: the baby looks away, gets fussy, decides naptime is now. Imagine trying to measure brain activity with sensitive equipment while babies sit still and pay attention. This is the daily reality of infant neuroscience research, where missing data isn't just common, it's practically inevitable.
That missing data might not be just random noise. Our new study suggests that whether a baby provides good quality data in a research study is partly written in their genes.

The Missing Data Problem
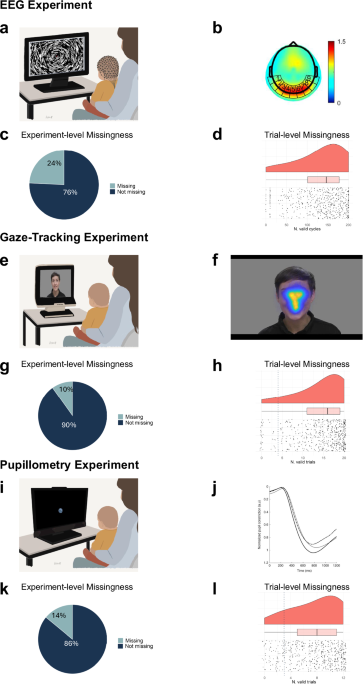
Studying brain and behavioral development in infants requires cutting-edge technologies like eye-tracking, pupillometry (measuring how pupils respond to light), and EEG (electroencephalography, which captures brain activity). These tools help us understand how babies perceive and interact with the world, particularly in those critical early months when neurodevelopmental trajectories are taking shape.
Yet there's a persistent challenge: not every baby completes every experiment. Some get tired or fussy. Sometimes equipment doesn't capture good data because a baby moved at the wrong moment. Sometimes, despite our best efforts, the data quality simply isn't usable.
Traditionally, researchers have treated missing data as random bad luck or noise in the system. We discard it, analyze what remains, move on. But what if missing data isn't random? What if the babies we successfully measure are systematically different from those we can't? Our conclusions might then apply only to a select subset of babies, not to all.
This question matters particularly in neurodevelopmental research. If we're trying to identify early markers of conditions like autism through subtle differences in how infants process sensory information or engage with social stimuli, we need to understand whether our measurements capture the full picture or just a systematically biased slice of it.
The Twin Study Advantage
To investigate what drives data loss in infant studies, we examined data from 594 five-month-old twins. Twin studies offer a unique analytical advantage for disentangling nature and nurture. Identical twins share 100% of their DNA, while non-identical twins share about 50%, like regular siblings. Both typically share the same home environment. By comparing similarity patterns between these groups, we can estimate how much genes versus environment contribute to a trait.
Previous research has used this approach to investigate variability in the babies' behaviors or brain responses. Here, we applied this logic to their missing data.
What We Discovered
Across three different experiments, familial factors (that is genetics and shared environment) played a substantial role in whether babies provided usable data. For some data types, more than half of the variation between babies stemmed from genetic factors.
EEG (Brain Activity): Whether a baby was excluded from the EEG experiment entirely showed moderate genetic influence (45%). Factors like tolerance for having a sensor net placed on one's head, ability to remain still, or sensitivity to the experimental setup might all have biological underpinnings, potentially relating to the same sensory processing differences we're trying to measure.
Eye-Tracking Experiments: For both gaze-tracking and pupillometry experiments, shared environment played a larger role than genetics in complete data loss. This likely reflects factors like which researcher conducted the test, testing conditions, or the baby's experiences that morning.
Data Quality: When examining how much usable data each baby provided, genetics mattered across all three experiments. Babies with similar DNA tended to provide similar amounts of good quality data. Particularly in the pupillometry experiment, 53% of variation in data quality was attributable to genetics.
Links to Autism: We found no significant association between missing data and genetic load for autism or later autistic traits in toddlerhood. This suggests that data quality in these experiments during early infancy might not directly reflect autism-related factors when studying babies from the general population samples. The picture might be different for babies who have older siblings with autism or other known risk factors.
Why This Matters for Neurodevelopmental Research
Rethinking Statistical Assumptions
Most statistical approaches assume missing data is completely random, meaning that whether you have data from a particular baby tells you nothing about that baby. Our findings challenge this assumption. If genetics influence both data quality and the neurodevelopmental processes we're studying, then babies included in analyses might systematically differ from those excluded.
This is particularly critical in autism research. Studies often examine whether infants who go on to develop autism show different patterns of eye gaze, pupil responses, or neural processing. But if genetic factors influence both autism risk and the likelihood of providing usable data, simply excluding babies with missing data could distort our understanding of these early markers.
Better Research Methods
Understanding what drives data loss enables better experimental design. We can develop testing procedures that work for a broader range of infants, including babies with different temperamental profiles, sensory sensitivities, and regulatory capacities.
Missing Data as Signal
Perhaps most intriguingly, missing data might contain information rather than just being a nuisance. If the same factors that influence early brain development also influence whether a baby can complete a particular test, then patterns of missing data might actually inform our understanding of development.
Different Tests, Different Challenges
Interestingly, babies who provided good data in one experiment weren't necessarily the same babies who provided good data in another. The correlation between data quality across our three experiments was surprisingly low.
Being a "good participant" isn't a general trait. A baby might sit perfectly still for EEG but refuse to look at the eye-tracking screen. This specificity suggests different experiments tap into different aspects of infant temperament, attention, and physiology, with important implications for multi-method studies increasingly common in neurodevelopmental research.
The Bigger Picture
Approximately 60% of babies in our study provided usable data for all three experiments. The other 40% were missing from at least one, typical for infant research and highlighting just how challenging it is to study early development.
These findings underscore the need for more inclusive methods that accommodate babies with different profiles, better statistical approaches that leverage partial data, and greater awareness that our samples might be systematically biased in ways that matter for the questions we're asking.
Moving Forward
When you encounter research on infant brain development, particularly studies identifying early markers of neurodevelopmental conditions, consider: which babies made it into that analysis? What about the ones who didn't?
Understanding patterns of missing data isn't just a technical concern for statisticians. It's fundamental to understanding development. The babies we struggle to measure might be just as important as those we can easily assess, and developing methods that work for all babies will give us a more complete picture of early neurodevelopment.
Every baby has something to teach us about early development, even the ones who don't sit still for the camera.
Follow the Topic
-
Communications Psychology
An open-access journal from Nature Portfolio publishing high-quality research, reviews and commentary. The scope of the journal includes all of the psychological sciences.

Your space to connect: The Psychedelics Hub
A new Communities’ space to connect, collaborate, and explore research on Psychotherapy, Clinical Psychology, and Neuroscience!
Continue reading announcementRelated Collections
With Collections, you can get published faster and increase your visibility.
Replication and generalization
Publishing Model: Open Access
Deadline: Dec 31, 2026
Comparative Psychology of Cognition, Affect, and Behaviour
Publishing Model: Open Access
Deadline: Jul 02, 2026


Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in