Why we crowdsourced 5000 Amazon shoppers’ purchases: the value of open e-commerce research
Published in Social Sciences and Research Data
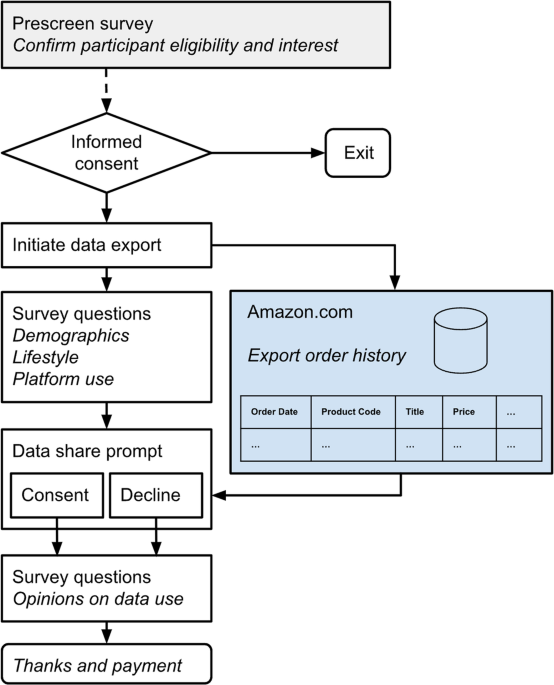
Digital platforms increasingly collect, leverage, and sell volumes of data that dwarf what is available to researchers and government agencies. This data could unlock new research avenues and provide policy makers with societal insights, however, this data is typically inaccessible to researchers. To address this challenge, we built a tool to ethically crowdsource consumer data, creating the open e-commerce 1.0 dataset. The dataset includes detailed information from over 5,000 U.S. Amazon customers, and covers more than 1.8 million purchases from 2018 through 2022. Each record is linked to demographic and lifestyle information, providing a rich source for analysis.
In addition to releasing a novel dataset, our initiative sheds light on how large-scale and responsible data crowdsourcing methods can help collect valuable data from online platforms.
Our initial analysis of this data reveals several insights and highlights areas for future research. Purchase data sheds light on consumer behavior and can be used to estimate economic indicators. Details about consumers also provide more nuanced economic insights than many existing datasets and metrics.
Opportunities for future work
The dataset can help answer many research questions related to consumer behavior. For example, face mask purchases in our dataset track the number of reported COVID-19 deaths, indicating that consumers quickly adjust their spending patterns in response to external shocks.
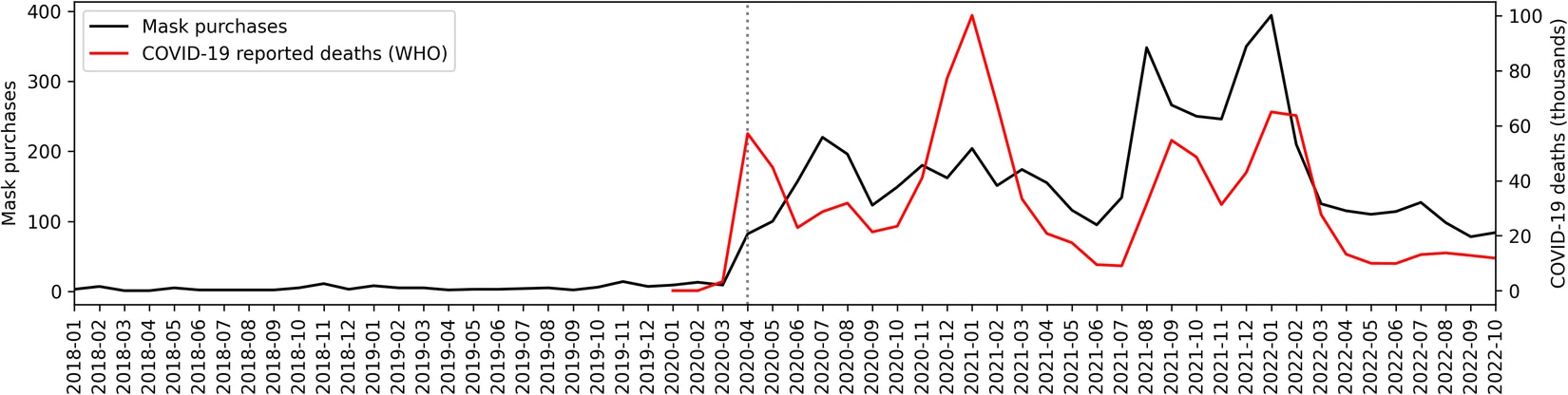
Figure. Monthly COVID-19 reported deaths (U.S. data reported by WHO) compared to face mask purchases.
We also find that the data aligns with economic indicators. Spending on books is correlated with US Census data on retail book sales. Making this data publicly accessible can allow researchers to trace demand across a wide range of product categories or compare behavior on Amazon to other marketplaces.
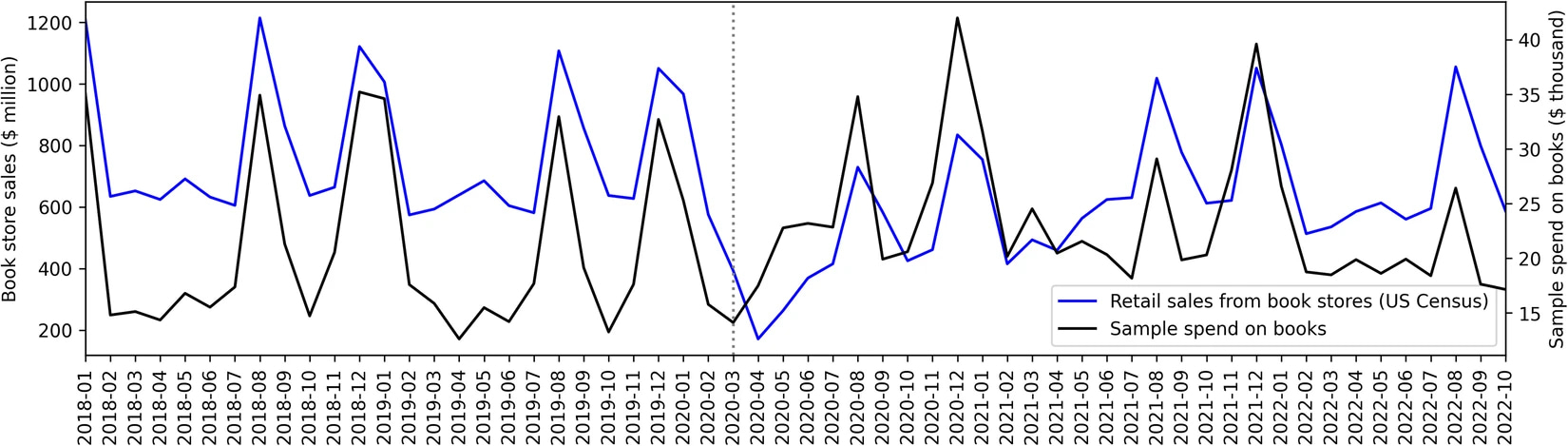
Figure. Monthly book store retail sales (from the U.S. Census Bureau) compared to monthly spend on books in the Amazon dataset.
In contrast to many existing datasets, our dataset connects itemized purchases with consumer demographics. This allows future work to explore how consumer behavior is linked to factors like race, education, income and geography.
For example, crowdsourced purchase data could facilitate developments in major economic indicators like price indices, which are currently pegged to baskets of products and used to estimate inflation. Price indices could be extended beyond product categories to segment consumer groups by variables like education, income, or geography. Understanding how price changes and inflation impact these different groups could yield important economic insights.
Crowdsourcing as a Method and Experiment
In the process of building this dataset, we also tested different ways of designing crowdsourcing tools. We found that communicating transparently about the reasons for crowdsourcing and the data being collected effectively increases participation, in some cases out-performing small monetary rewards. We explore these survey design questions in our paper Insights from an experiment crowdsourcing data from thousands of US Amazon users: The importance of transparency, money, and data use in the Proceedings of the ACM on Human-Computer Interaction (CSCW).
Challenges and Broader Impacts
The proprietary nature of data collected by corporations often shields commercial surveillance practices from greater public scrutiny, limiting transparency and research opportunities. Midway through our project, Amazon discontinued a feature that our data collection tool depended on, significantly impacting our data collection efforts. Relying on corporate platforms’ beneficence for research data can be risky—and highlights the need for policies that enable individuals to share their data with researchers.
Policy Implications and the Path Forward
One promising avenue to empower this sort of work is legislation that allows consumers to take ownership of their data. Laws like the California Consumer Privacy Act (CCPA) give consumers the right to access their data—and then share it with researchers if they choose. Some privacy regulations, like the EU’s GDPR, make data rights non-delegable, which can make it hard for consumers to give researchers access. Initiatives like Consumer Report’s Data Rights Protocol are seeking to streamline this process to make it easier for US consumers to obtain their data and standardize data formats across companies.
To truly democratize data access, we need policies that support consumer rights to data access and facilitate the sharing of this data with the research community. We highlight these points in a comment to the FTC on consumer surveillance, advocating for regulatory changes that increase corporate transparency while reducing power asymmetries. We hope that the open e-commerce 1.0 dataset will be just the beginning. We envision a future where more datasets are crowdsourced from different platforms, creating a more comprehensive view of consumer behavior across various sectors. We invite the research community to join us in this effort, and contribute to a more open data culture.
Follow the Topic
-
Scientific Data
A peer-reviewed, open-access journal for descriptions of datasets, and research that advances the sharing and reuse of scientific data.

Introducing: Social Science Matters
Social Science Matters is a campaign from the team at Palgrave Macmillan that aims to increase the visibility and impact of the social sciences
Continue reading announcementRelated Collections
With Collections, you can get published faster and increase your visibility.
Genomics in freshwater and marine science
Publishing Model: Open Access
Deadline: Jul 23, 2026
Genomes of endangered species
Publishing Model: Open Access
Deadline: Jul 01, 2026




Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in