Data storage in DNA with fewer synthesis cycles using composite DNA letters
Published in Bioengineering & Biotechnology

Explore the Research

Data storage in DNA with fewer synthesis cycles using composite DNA letters - Nature Biotechnology
Toward more storage for less synthesis using a six-letter composite DNA alphabet.
The density and long-term stability of DNA make it an appealing storage medium, particularly for long-term data archiving. Recent proposed DNA based data storage systems1–4 have demonstrated physical information density of 10-200 PB/gram reflecting a six orders of magnitude superiority over current state of the art storage media3. In nature, DNA stores genetic information for billions of years and has evolved to be a robust and efficient mechanism for carrying and handling information. Storing digital information on DNA involves encoding the information into a sequence over the DNA alphabet (i.e. “A”, “C”, “G” and “T”), producing synthetic DNA molecules with the desired sequence(s), and storing the synthetic biological material. Reading the stored information is done by sequencing the stored DNA (possibly amplifying only part of the message) and decoding to obtain (possibly part of) the original digital information (Figure 1A).
One of the major performance characteristics of DNA based storage systems is the logical information density, defined as the number of synthesis cycles required to write a single unit of data. This factor is key to the overall system performance since DNA synthesis is the most expensive and delicate component in the process. In this work we developed methods that improve the logical density while keeping other performance characteristics, such as the overall scale, the physical density and the error rates, at levels comparable to previously reported systems. To do so, we leverage the inherent sequence multiplicity of current DNA synthesis and sequencing technologies, which leads to significant information redundancy in all current DNA based storage systems.
We introduce the use of composite DNA letters to increase the logical density of DNA storage above the strict, single molecule, theoretical limit of 2 bits per synthesis cycle. The idea behind composite DNA letters can be compared to the generation of different colors by mixing the 3 base colors: Red, Green and Blue. Similarly, a composite DNA letter is a representation of a position in a sequence that constitutes a mixture of all four standard DNA nucleotides in a specified pre-determined ratio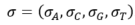 . For example,
. For example,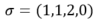 denotes a composite DNA letter that represents a 25%, 25%, 50% and 0% chance of seeing A, C, G and T respectively. Writing a composite DNA letter at a given position of a DNA sequence is equivalent to producing (synthesizing) multiple copies (oligonucleotides) of the sequence, so that in this given position the different DNA nucleotides are distributed across the synthesized copies according to the specifications of
denotes a composite DNA letter that represents a 25%, 25%, 50% and 0% chance of seeing A, C, G and T respectively. Writing a composite DNA letter at a given position of a DNA sequence is equivalent to producing (synthesizing) multiple copies (oligonucleotides) of the sequence, so that in this given position the different DNA nucleotides are distributed across the synthesized copies according to the specifications of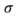 (Animation). Reading a composite letter requires the sequencing of multiple independent molecules representing the same composite sequence and inferring the original composition from the observed base frequencies.
(Animation). Reading a composite letter requires the sequencing of multiple independent molecules representing the same composite sequence and inferring the original composition from the observed base frequencies.

Animation 1:
Synthesis of composite DNA.
Using composite DNA letters effectively extends the available alphabet for encoding information and therefore allows higher data content per synthesis cycle (Figure 1B).
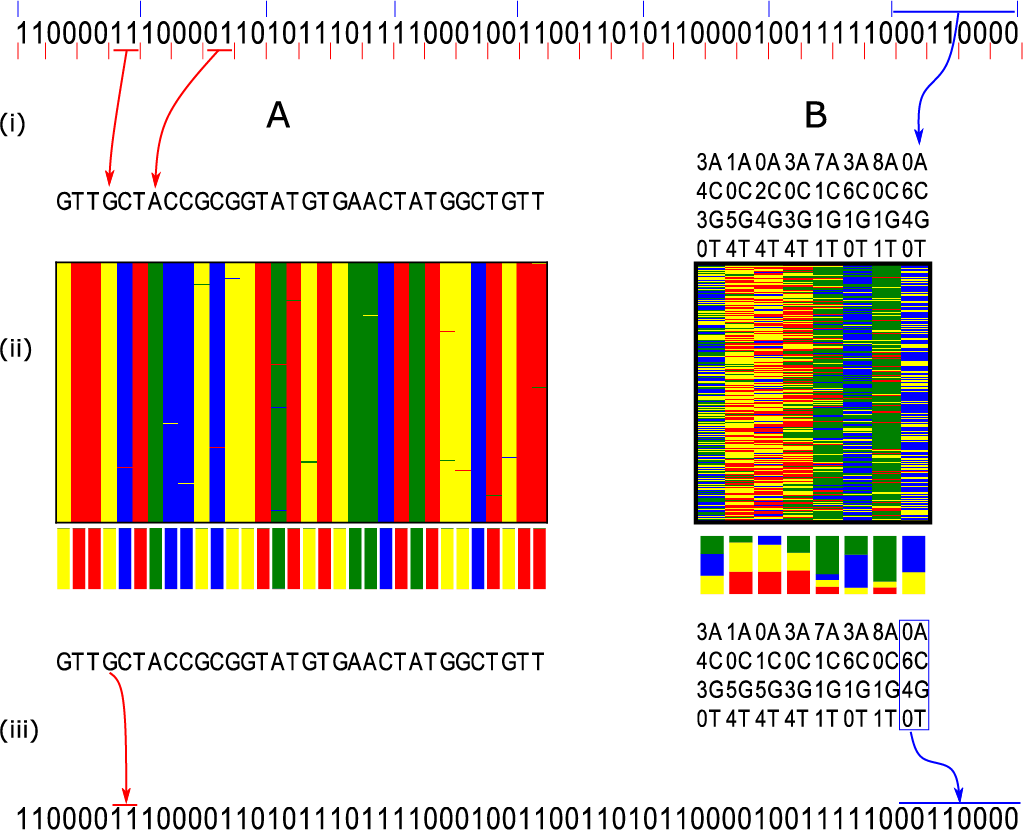
Figure 1:
Encoding a binary message using standard and composite DNA. A binary message, depicted on top, is encoded into DNA.
A) Standard DNA-based storage scheme. The binary message is encoded to DNA by mapping every 2 bits (represented by the short red separating lines) to a DNA letter or synthesis cycle (i), the designed DNA sequence will then be synthesized and sequenced with high multiplicity by a noisy procedure that introduces some errors (ii). The sequencing output is then used to infer the letter at every position (iii). Decoding of the original message, including the use of error correction code mechanisms.
B) The same message is encoded using a composite DNA alphabet by mapping every 8 bits (represented by the blue separating lines) of the binary message to a single composite DNA position (a single synthesis cycle). Sufficiently deep sequencing allows correct inference of the original composite letters.
In our paper we demonstrate an implementation of a complete large scale composite DNA based storage system in which we use a 6-letter composite DNA alphabet to repeat the encoding of the 2.12MB message from Erlich and Zielinski3 together with a 6.4MB file containing a bi-lingual version of the Bible (Figure 2). We code these files with several potential composite alphabets to understand differences and advantages. Overall we coded about 20MB of data in this work. This part of our implementation demonstrates a logical density of 1.96 bits per synthesis cycle, which is a 25% increase compared with previous reports at this scale. We simulate encoding of the same message using larger composite alphabets and show that a logical density of 6.4 bits per synthesis cycles can potentially be achieved (a 4-fold increase). We also demonstrate the coding into DNA of a very short message at 4.29 bits per synthesis cycle.
When working with a large scale encoding as implemented in this work, one runs into rare events that affect reconstruction accuracy. With a system based of millions of parts (that is: molecules, reads etc), one expects rare events to happen. An event that happens once in million, for example, is very likely to occur several times. In our implementation we use robust error correcting schemes as well as statistical inference schemes, both designed for our composite alphabet needs, to overcome these difficulties and enable the large scale composite encoding. This includes full recovery of the encoded 6.4MB bible message from an NGS reading with an average of 160 reads per observed sequence. Taking into account the cost reduction achieved by the increased logical density as well as the trade-off added sequencing costs, we show that using composite DNA can potentially cut the overall cost of DNA based archiving systems by half.
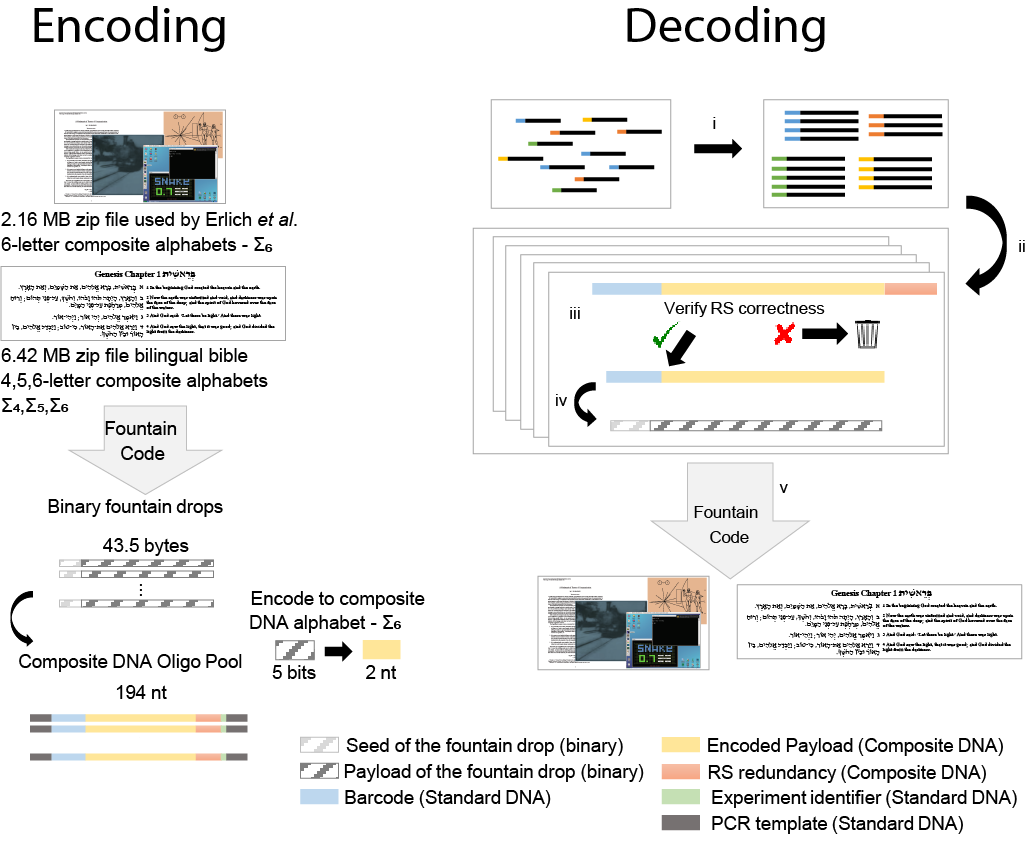
Figure 2:
Encoding and decoding pipelines for large-scale composite DNA-based data storage.
Left) Encoding: A compressed input file was processed by the fountain code to produce binary droplets. A composite DNA encoding workflow was then applied for each droplet including the translation of every 5 bits to a single composite letter (out of 6 possible letters) and the addition of Reed-Solomon error correction symbols (RS), all resulting in a composite DNA sequence. All composite DNA sequences where then synthesized by Twist Bioscience to produce a composite oligo pool and sequenced in the Technion Genome Center.
Right) Decoding: Sequencing reads are grouped by the unique identifier (standard DNA with RS) (i) and every group is used to infer a single composite DNA sequence (ii). Error correction codes are used to verify the correctness of the composite DNA sequence (iii) which is then translated back to a binary message (iv). The recovered binary messages are further decoded using the fountain decoder to obtain the original files (v).
The design and analysis of large libraries of DNA molecules lies in the heart of the intersection between statistics, computer science, molecular biology and synthetic biology. Working in this domain is therefore particularly exciting! It also requires familiarity with the properties and potential pitfalls of the system as well as with potential informatics solutions. The process of making ends meet and of creatively and rigorously modifying methods to address challenges has been a rewarding and intellectually fun process for us. We are grateful to have walked this path with great collaborators and to have received technical support from Twist Bioscience, the Technion Genome Center and others. Sharing our challenges with colleagues, in the Yakhini Research Group, the Amit Labs, and in other forums, lead to great conversations and in turn to creative and useful advice.
By Leon Anavy and Zohar Yakhini
Our paper: Anavy L., Vaknin I., Atar O., Amit R., Yakhini Z., Data storage in DNA with fewer synthesis cycles using composite DNA letters. Nature Biotechnology; 10.1038/s41587-019-0240-x (2019)
References:
1. Church, G. M., Gao, Y. & Kosuri, S. Next-generation digital information storage in DNA. Science 337, 1628 (2012).
2. Goldman, N. et al. Towards practical, high-capacity, low-maintenance information storage in synthesized DNA. Nature 494, 77–80 (2013).
3. Erlich, Y. & Zielinski, D. DNA Fountain enables a robust and efficient storage architecture. Science (80-. ). 355, 950–954 (2017).
4. Organick, L. et al. Random access in large-scale DNA data storage. Nat. Biotechnol. 36, 242–248 (2018).
Follow the Topic
-
Nature Biotechnology

A monthly journal covering the science and business of biotechnology, with new concepts in technology/methodology of relevance to the biological, biomedical, agricultural and environmental sciences.

Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in