Deep learning for diagnosis of Acute Promyelocytic Leukemia via recognition of genomically imprinted morphologic features
Published in Cancer


It was the summer of 2017 when I was attending the annual Bloomberg~Kimmel Institute for Immunotherapy meeting at Johns Hopkins when I met Eugene Shenderov (the senior author of this manuscript), at the time, an oncology fellow at Hopkins. We met at the poster session and after the day was over, we stood outside in the parking lot and talked for over an hour about interesting scientific opportunities. He realized I had an interest in machine learning and proposed a project he had been thinking about to leverage machine learning/artificial intelligence to diagnose Acute Promyelocytic Leukemia (APL). He presented APL as a rare but quickly fatal subtype of Acute Myeloid Leukemia (AML) that clinicians had a difficult time diagnosing in a clinically timely fashion as the definitive genetic testing could take days to result while APL’s, a true oncologic emergency, morbidity increases by the hour. The thought/hypothesis was that the genetic alteration of the cells, the t(15;17) translocation, would have effects on the morphological features of those cells that a deep learning model could learn. I thought the idea was fascinating and had recently been acclimating myself to deep learning techniques, and thought, this could be an excellent project to continue to refine those skills. We then began working together with a team of medical students and experts in leukemia at Johns Hopkins to develop a deep learning algorithm that could quickly and accurately diagnose APL from peripheral smear at the time of clinical presentation.
While our manuscript touches upon multiple deep learning models trained with different cell types from the peripheral smear, we found the optimal model was a multiple-instance deep learning model that could ingest all the cells from the peripheral smear and output the probability of the patient having APL (Fig. 1). One can imagine this model as being able to look at all the cells from a peripheral smear and learn to focus its attention on the cells that carry the predictive signature of APL. The model can not only tell you whether the given patient has APL but it can also highlight for the physician the most predictive cells, the ones that carry the strongest APL morphological signature.
Figure 1. Multiple Instance Deep Learning Model. In order to classify whether a given patient/sample has APL, our model takes a collection of cells from the patient, extracts the diagnostic morphological features from the cells via convolutional neural network layers, and then uses an average-pooling multiple instance learning approach to assign the probability of the entire sample of having APL.
We trained this model on a cohort of patients seen at Johns Hopkins Hospital before 2019 and then tested our model on a prospective cohort of patients seen after 2019. When benchmarking our model against 10 practicing academic leukemia-treating hematologists, oncologists, and hematopathologists, the deep learning model demonstrated equivalent or better classification performance to 9/10 clinicians (Fig. 2). These results were especially exciting because of the generally small nature of our training cohort. We think as our model is able to train on more and more data, it should be able to provide "super-human" performance. Another interesting observation we made was in regards to the high level of variability in the performance of highly trained clinical faculty. Besides having a model that can likely eventually outperform human beings with enough data, a machine learning model, such as the one described in this work, provides the benefits of consistency and reproducibility across physicians and institutions; removing human factors that are difficult to account for in this already difficult diagnosis.
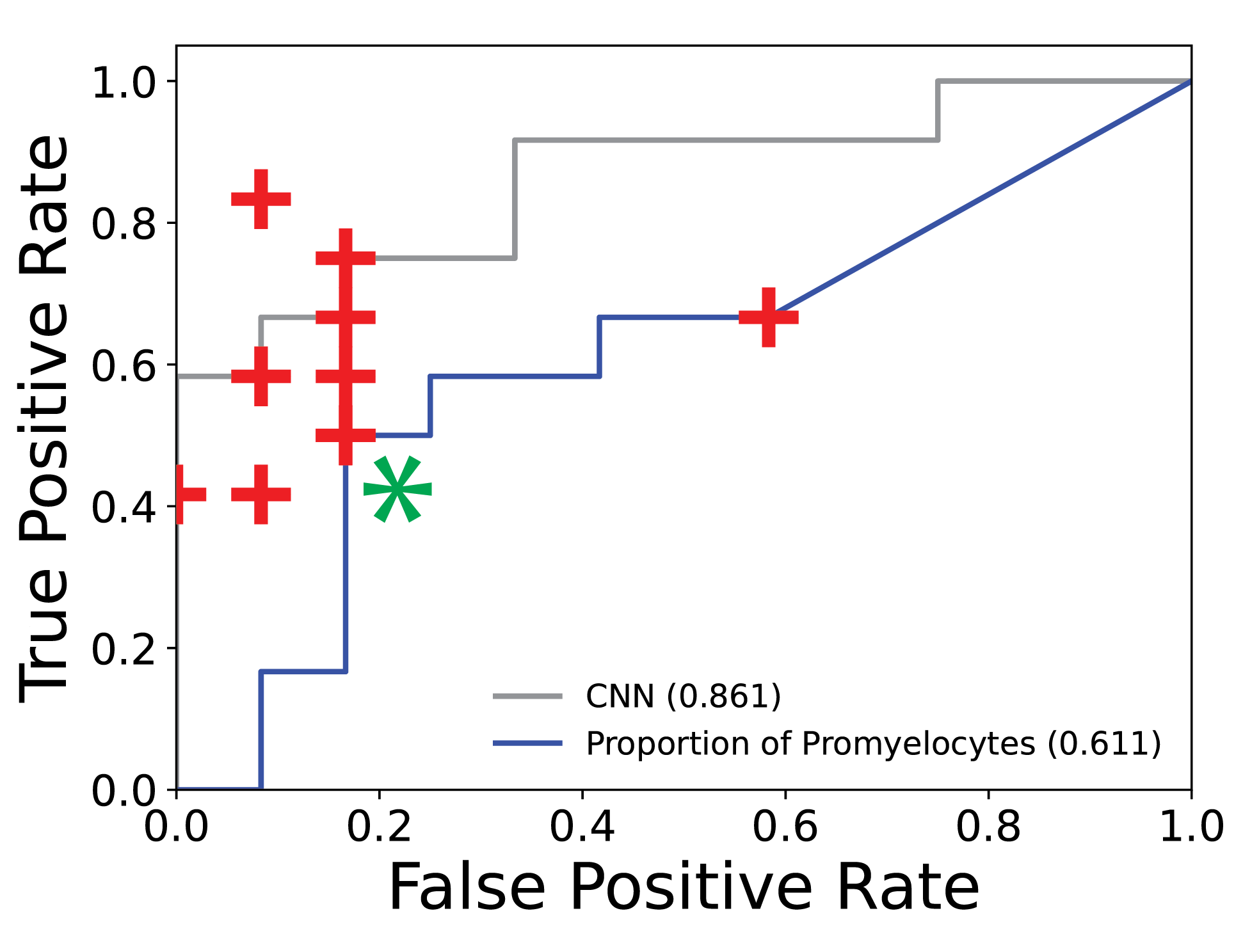
Figure 2. Classification performance of deep learning model against clinicians. CellaVision cells from patients in the prospective validation cohort were provided to 10 clinicians to assess clinician diagnostic specificity/sensitivity against deep learning model (+ denotes an individual clinician. * denotes two individuals with same performance, grey line denotes deep learning model).
While the model's ability to correctly diagnose APL from the peripheral smear is arguably the highlight of our work because of its clinical implications, we also wanted to create an"explainable AI." While we want our models to perform well, we also would like to understand some of the "reasoning" behind the model's decision-making. First, this gives us some transparency into what the model may be doing when it makes a diagnosis, which can help catch problematic biases in the data that could confound the true biological signal with artifact. Being able to catch these problems can help us design better models and training strategies to encourage a logic within the model that is robust and would be expected to generalize in a broad set of clinical circumstances. The second reason we would want an "explainable AI" is so we can use the model to teach us, humans, diagnostic features of disease that we may have not known to look for or would have been very difficult to notice in the large amount of data.
To implement a form of explainable AI, we demonstrated in the manuscript that the model could identify the most predictive cells or the cells carrying the strongest predictive signature and then show us where in the cell the model was focusing its attention (Figure 3). This allowed us to first verify the model was indeed using differences in the cell's morphological features to make its diagnosis, as well as highlight to us features that had not been previously described or appreciated in the literature for APL. While the dogma that is often taught in medical schools is that Auer rods are pathognomonic for APL (often tested on medical board exams) we found that these were not features the model had learned as being most predictive. What we noticed when looking at the most predictive cells and their corresponding attention maps, was that the model had learned how to correctly identify arrested myeloid blasts and could accurately quantify them in a given sample, leading to very accurate ability to diagnose APL: the more arrested cells in the promyelocyte stage in a given sample, the more likely that given individual had APL.
Figure 3. Most predictive cells and their predictive features. Since the model assigns a probability of each cell carrying the predictive morphological signature of either APL or non-APL, the user/physician can look at the most predictive cells for each type of leukemia. When using an explainable AI method called integrated gradients, we can show where the model is focusing its attention when making its diagnosis for any given cell.
Finally, a part of the work that is not fully explored in the manuscript was a problem we had with samples being collected from very different time points and the corresponding batch effects that were introduced by different staining protocols and aging of the slides. Since APL is quite rare, when we collected samples for our training cohort, we had to go back over 20 years to collect more patients who had APL. What we did not realize when doing this is that since now there was an association of APL with age of the slide, we had unknowingly introduced an age-related association that the deep learning model could learn. Thankfully, to the use of our explainable AI method, we caught that the model was learning this age-confounded bias. We either had to remove almost a third of our APL's from our training cohort (already a small number) or figure out a way to encourage the model to ignore these age-associated features. With some time, we came up with a method (inspired by integrated gradients) that could encourage the model to "ignore" these batch staining artifacts. We took all the cells from APL/non-APL patients and applied a blurring operation and used these as a third group of samples (Fig. 4). Now, the model was trained to not only differentiate between APL/non-APL, but also to differentiate those two classes from our blurred out-group. In creating this out-group, the model was forced to learn the relevant morphological features of the cell as opposed to any staining associations within the data. This problem and how it was solved proved to be an excellent example of how explainable AI can improve the robustness of predictive models.

Figure 4. Training strategy to remove batch effects from staining. In order to encourage the model to learn morphological features (over confounders from staining artifacts) from the imaging data, we created a third out-group for training where the original APL/AML images were blurred. The model is then trained to distinguish samples from these three groups (APL, non-APL, and the blurred out-group).
We think the future of this work is very exciting as we believe the applications of this approach can be applied broadly to any clinical scenario where a peripheral smear may be used for a diagnosis, especially in the area of liquid malignancies and in resource-poor settings where a virtual oncology physician-aid would be invaluable. We hope to expand these models to identify a broad variety of translocations to provide another tool for clinicians managing these patients as well as expand our understanding of the morphological changes of cells with these genetic alterations.
Follow the Topic
-
npj Precision Oncology
An international, peer-reviewed journal committed to publishing cutting-edge scientific research in all aspects of precision oncology from basic science to translational applications to clinical medicine.

Related Collections
With Collections, you can get published faster and increase your visibility.
Minimal Residual Disease and Circulating Tumor DNA Dynamics in Personalized Cancer Treatment
Publishing Model: Open Access
Deadline: Mar 12, 2027
Next-Generation AI in Drug Design for Precision Oncology
Publishing Model: Open Access
Deadline: Apr 01, 2027




Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in