In the second year of my PhD I was attending my first large conference in Sapporo – the largest city on the northmost island of Japan, Hokkaido. There were a large number of contributions addressing resistive memory technologies (i.e., memristors) and how they might be applied in machine learning. I attended a lot of these talks and, while each approached the problem from their own angle, I remember being surprised that everyone ended up running into the same brick wall – the random, ‘non-ideal’ properties of resistive memory devices! While many papers proposed techniques to mitigate this randomness, others would stress the importance of better engineering these devices in order to eliminate it altogether and render them deterministic. Again I was surprised, since I had heard from my colleagues in CEA-Leti, a technology research institute nestled in amongst the French Alps, that randomness was intrinsic to these nanoscales devices that operated on the basis of displacing a handful of atoms.

There’s something about mountains. (left) A photo I took of myself on Mt. Asahidake, Japan, after the conference. It was during this time I began the initial work on the idea. (right) The CEA-Leti campus in Grenoble, in front of the Belledonne mountain range.
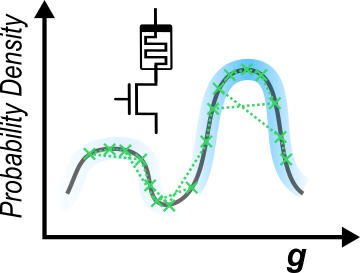
One evening after the conference, I was thinking a lot about this. Specifically, rather than the device, might it be the algorithm that could be improved? I had taken (what turned out to be a career altering) a machine-learning course during my undergraduate degree at the University of Glasgow, given by Professor Simon Rodgers, that focussed heavily on Bayesian techniques. One of the special things about Bayesian machine learning is that everything is described using random variables – just like resistive memories. Could Bayesian machine learning be the solution to this device-algorithm dichotomy? During some of the spare time I had during the rest of my stay in Japan, where I toured the beautiful, volcanic island of Hokkaido, I put together a first computer simulation of “memristor-based Markov chain Monte Carlo” using some data sent over to me by my PhD supervisor Elisa Vianello. After arriving back in France, based on the promise of these simulations, another colleague in CEA-Leti, Niccolo Castellani, set about building a ‘computer-in-the-loop’ setup where the algorithm could be realised experimentally. This ‘in-situ’ implementation made use of real, fabricated hybrid CMOS-memristor wafers that had been fully manufactured in Grenoble, between ST microelectronics and CEA-Leti.

We also contacted the research group of Damien Querlioz at Université Paris-Saclay, well known for their non-conventional use of resistive memory devices for the calculation of joint probabilities by Bayes rule, and proposed that we collaborate on this topic. Happily Damien accepted and, over the next year, we spent a great deal of our time working together; discussing, head-scratching and planning experiments. One such experiment, the device endurance study that become a highlight of our paper, very nearly never was - due to the onset of the Covid-19 pandemic. As the initial wave of the pandemic swept across Europe, CEA-Leti announced the closure of the facility the night before our experiment, started two weeks earlier, was due to finish. Myself and Niccolo arrived to the laboratory (at an unholy hour) the next day and, against the backdrop of our colleagues scrambling to get their own work in order, we managed to conclude the experiment and get our data with seconds to spare. The cherry on top of the cake were the results of a design project undertaken by two of Damien’s PhD students, Clement Turck and Kamel-Eddin Harabi, during the subsequent lockdown. Ironically, this may not have been possible if their own work plans had not also been complicated by the pandemic. Kamel and Clement found that, to train a full Bayesian neural network, a memristor-based Markov chain Monte Carlo sampling chip would require only a few micro Joules of energy – about as much as a single biological neuron firing fewer than ten times. Most importantly, this amounted to a five order of magnitude reduction with respect to an implementation of the same algorithm using a state of the art microprocessor - the difference in height between the tallest building in the world, the Burj Kalifa in Dubai, and a five-cent piece lying on the ground next to it.
The current application of machine learning is tied up in the cloud. Learning takes place centrally, where energy is abundant, and the model is then either queried by, or shipped out to, the edge (where energy is scarce) to perform inference only. Our work, now published in Nature electronics (https://www.nature.com/articles/s41928-020-00523-3), offers a means of bringing learning to the edge for the first time. Edge learning not only provides an opportunity to challenge the centralised, cloud-based, paradigm that currently dominates thinking in machine learning, but can also open the door onto new applications, based on locally-adaptive machine intelligence, that are currently out of reach with existing approaches.
Follow the Topic
-
Nature Electronics

This journal publishes both fundamental and applied research across all areas of electronics, from the study of novel phenomena and devices, to the design, construction and wider application of electronic circuits.



Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in