Speech separation and 2D localization with self-distributing microphone arrays
Published in Computational Sciences


Imagine being in a crowded room with a cacophony of speakers and having the ability to focus on or remove speech from a specific 2D region. This would require understanding and manipulating an acoustic scene, isolating each speaker, and associating a 2D spatial context with each constituent speech. However, separating speech from a large number of concurrent
speakers in a room into individual streams and identifying their precise 2D locations is challenging, even for the human brain.
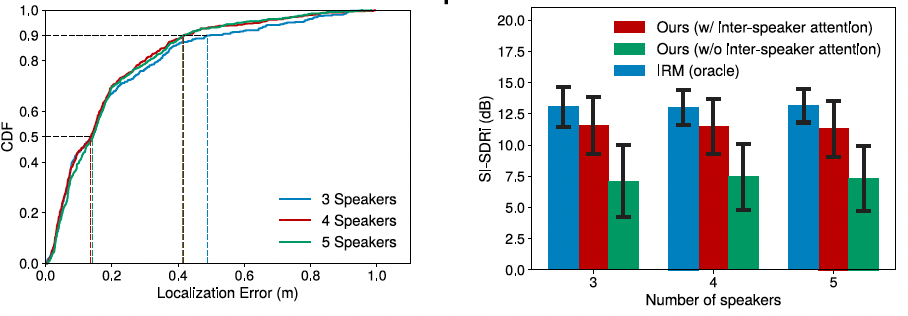
But if we can achieve this capability it can enable new acoustic applications. For example, we can separate speech and map co-located speakers to different conversation zones; thus, addressing the problem of group-level multi-conversation separation and transcription where in a large room with close to 4-5 people talking concurrently, we can separate the individual speakers into conversations and provide transcriptions. We can also use this to create mute/active zones where we suppress/capture speech from specific 2D regions in a room. For example, a user may say: “Mute all conversations in a 1 m bubble around me” or “Transcribe only speech at the work desk but not at the dining table”. Finally, this can also enable location-based speech interaction for smart home applications, where a speech command could be interpreted differently depending on the speaker’s 2D location. In our latest Nature Communications paper we show how we can achieve speech separation and 2D localization using distributed microphone arrays to create speech zones. Our neural networks can estimate the number of speakers and separate them from a mixture of 3-5 sources as well as localize them to 15 cm accuracy in real-world unseen reverberant environments.

Self-distributing microphone arrays
Creating an on-demand distributed infrastructure with a large number of wireless acoustic sensors across a room has been a long-standing vision in the acoustic and speech communities, since it can enable a range of acoustic capabilities and applications. Specifically, distributing a large number of acoustic sensors across a larger area is attractive for multiple reasons.
In contrast to commercial smart speakers and conferencing systems where the microphones are
co-located, distributing the microphones across a larger area provides the ability to localize sounds in the 2D space. This is because a distributed array has a larger aperture size and hence can achieve better spatial coverage or resolution.
To fully leverage the capabilities of distributed wireless microphone array, the microphones should be able to disperse themselves across a surface, adapt to different environments and tasks to efficiently use the available space. For example, when there is sufficient space, the devices should be dispersed widely to increase the effective aperture size. Or if there are two speakers in the same direction, it should be able to reposition the locations of the acoustic devices to better perform speech separation and localization or reconfigure the shape for
better acoustic resolution in specific target directions.
In this work, we present the first self-distributing wireless microphone array system. We designed self-distributing acoustic swarms where tiny robots cooperate with each other using acoustic signals to navigate on a 2D surface (e.g., table) with centimeter-level accuracy. We developed navigation techniques for the swarm devices to spread out across a surface as well as navigate back to the charging station where they can be automatically recharged. Our on-device sensor fusion algorithms combine acoustic chirps and IMU data at the swarm devices
to achieve 2D navigation as well as automatic docking at the charging station, without using cameras or external infrastructure. Further, we designed algorithms to ensure that the swarm devices do not fall off the surface and can recover from collisions with other objects.

Neural networks for speech separation and 2D localization
We present a new distributed microphone array processing algorithm using our acoustic swarm that performs the following two tasks: 1) localize all speakers in a room without prior knowledge about the number of speakers, 2) separate the individual acoustic signal of each speaker. Our algorithm is based on a joint 2D localization and speech separation framework where we use speech separation to achieve multi-source 2D localization of an unknown number of speakers. The computed 2D locations are used to further improve the speech separation performance. Our architecture has two key components. First, to reduce the search space for 2D localization using neural networks, we run a low-computational complexity signal processing algorithm to prune the search space and then use a speech separation neural network to find the speakers' 2D locations only in the remaining space. Second, in real-world reverberant environments, the speech separation quality can be poor due to residual cross-talk components between speakers. To address this, we incorporated an attention mechanism between speakers by leveraging their estimated 2D locations to jointly compute a much cleaner signal for each speaker and reduce the cross-talk.
. It then applies self-attention across speakers using a transformer encoder (TFE) to compute attention weights across different speakers. It repeats this multiple times to address cross-talk between speakers.")
The above figure shows the neural network for speech separation. The encoder and decoder blocks are applied separately to the aligned microphone data for each of the speakers. The
bottleneck block first applies temporal self-attention to each speaker individually
using a conformer encoder (CE). It then applies self-attention across speakers using
a transformer encoder (TFE) to compute attention weights across different
speakers. It repeats this multiple times to address cross-talk between speakers.
Real-world evaluation

We assess our system’s performance when the microphone arrays are deployed in previously unseen cluttered environments. Our evaluation used the environments that were unseen during training and included offices, living rooms, laboratories. To obtain the ground-truth signals, we used loudspeakers to play back speech signals from different locations in the room at heights ranging from 90 to 160 cm. Our evaluate shows that the median localization error across all the tested scenarios was 15 cm and that the 90 percentile error was 49–50cm for 3–5 concurrent speakers. Further the signal quality improvement is noticeable demonstrating successful speech separation in real-world reverberant environments.
Conclusion
Our proposed system is an important step in the direction of achieving capabilities that have long only existed in the realm of science fiction. Our self-distributing microphone arrays present vast opportunities for novel audio applications as they can physically adapt their structures to the environment unlike the conventional centralized microphone arrays
while automatically recharging on their own. Our system also can address the long-standing cocktail party problem by allowing the user to focus on a conversation at specific regions in the room. Additionally, the system can be a part of future smart homes, permitting speech interaction with devices based on the speakers’ locations. Finally, since our arrays are also equipped with loudspeakers, future work may create distributed self-organizing speaker arrays that can program sound zones, where people in different zones of the room can perceive different sounds.
Follow the Topic
-
Nature Communications
An open access, multidisciplinary journal dedicated to publishing high-quality research in all areas of the biological, health, physical, chemical and Earth sciences.

Related Collections
With Collections, you can get published faster and increase your visibility.
Women's Health
Publishing Model: Hybrid
Deadline: Ongoing
Healthy Aging
Publishing Model: Open Access
Deadline: Dec 31, 2026




Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in