The best of both worlds: Deep learning meets vector-symbolic architectures
Published in Bioengineering & Biotechnology
Machines have been trying to mimic the human brain for decades. But neither the classical symbolic AI that dominated machine learning research until the late 1980s nor its younger cousin, deep learning, have been able to fully simulate the intelligence it’s capable of. One promising approach towards this more general AI is in combining neural networks with symbolic AI. Linked to such neuro-symbolic AI, we present a new idea based on vector-symbolic architectures in our paper “Robust High-dimensional Memory-augmented Neural Networks”.
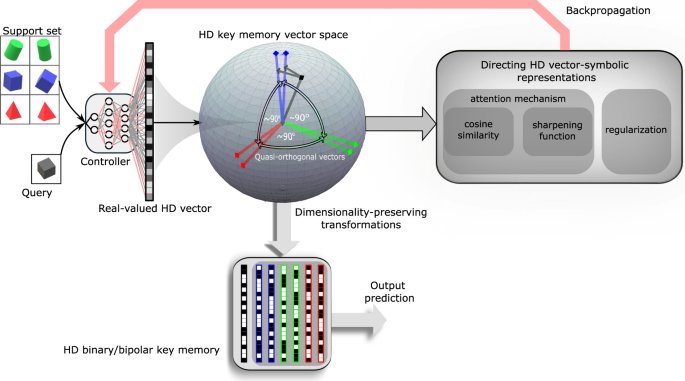
We’ve relied on the vector-symbolic architectures that take inspiration from the very size of the brain’s circuits to compute with points of a high-dimensional space. Specifically, we wanted to combine the learning representations that neural networks create with the compositionality of symbol-like entities represented by distributed high-dimensional vectors. The idea is to guide a neural network to represent unrelated objects with dissimilar high-dimensional vectors in a fully differentiable manner.
In the paper, we show that a deep convolutional neural network used for image classification can learn from its own mistakes to operate with the high-dimensional vectors in the vector-symbolic architectures. It does so by gradually learning to assign dissimilar, such as quasi-orthogonal, vectors to different image classes, mapping them far away from each other in the high-dimensional space. More importantly, it never runs out of such dissimilar vectors.

This directed mapping helps the system to use high-dimensional algebraic operations for richer object manipulations, such as variable binding—an open problem in neural networks. When these “structured” mappings are stored in the AI’s memory (referred to as explicit memory), they help the system learn—and learn not only fast but also all the time. The ability to rapidly learn new objects from a few training examples of never-before-seen data is known as few-shot learning.
High-dimensional explicit memory as computational memory
During training and inference using such an AI system, the neural network accesses the explicit memory using expensive soft read and write operations. They involve every individual memory entry instead of a single discrete entry. These soft reads and writes form a bottleneck when implemented in the conventional von Neumann architectures (e.g., CPUs and GPUs), especially for AI models demanding over millions of memory entries. Thanks to the high-dimensional geometry of our resulting vectors, their real-valued components can be approximated by binary, or bipolar components, taking up less storage. More importantly, this opens the door for efficient realization using analog in-memory computing hardware.
Such transformed binary high-dimensional vectors are stored in a computational memory unit, comprising a crossbar array of memristive devices. A single nanoscale memristive device is used to represent each component of the high-dimensional vector that leads to a very high-density memory. The similarity search on these wide vectors can be efficiently computed by exploiting physical laws such as Ohm’s law and Kirchhoff’s current summation law.
This approach was experimentally verified for a few-shot image classification task involving a dataset of 100 classes of images with just five training examples per class. Although operating with 256,000 noisy nanoscale phase-change memristive devices, there was just a 2.7 percent accuracy drop compared to the conventional software realizations in high precision.
We believe that our results are the first step to direct learning representations in the neural networks towards symbol-like entities that can be manipulated by primitives in high-dimensional computing paradigm. Such an approach facilitates fast and lifelong learning and paves the way for high-level reasoning and manipulation of objects.
The ultimate goal, though, is to create intelligent machines able to solve a wide range of problems by reusing knowledge and being able to generalize in predictable and systematic ways. Such machine intelligence would be far superior to the current machine learning algorithms, typically aimed at specific narrow domains.
The research has been carried out by Geethan Karunaratne, Manuel Schmuck, Manuel Le Gallo, Giovanni Cherubini, Luca Benini, Abu Sebastian, and myself as part of a collaboration between IBM Research-Zurich and ETH Zurich. Images courtesy of Geethan Karunaratne.
Follow the Topic
-
Nature Communications
An open access, multidisciplinary journal dedicated to publishing high-quality research in all areas of the biological, health, physical, chemical and Earth sciences.

Related Collections
With Collections, you can get published faster and increase your visibility.
Women's Health
Publishing Model: Hybrid
Deadline: Ongoing
Tumor Microenvironment Crosstalk and Therapeutic Implications
Publishing Model: Hybrid
Deadline: Nov 02, 2026

Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in