UniKP: Decoding the Enzyme 'Velocity' Secrets
Published in Protocols & Methods, Cell & Molecular Biology, and Computational Sciences
🌟 Revealing the Secrets of Enzyme "Velocity": The UniKP Breakthrough
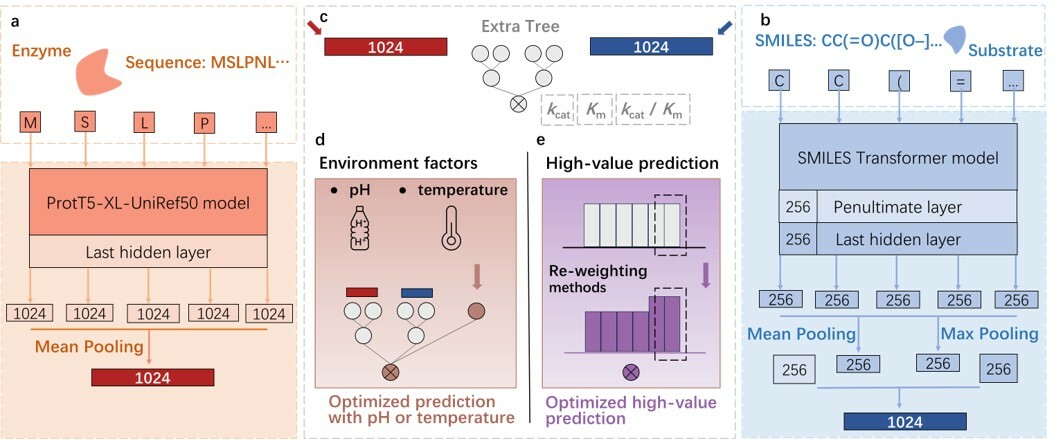
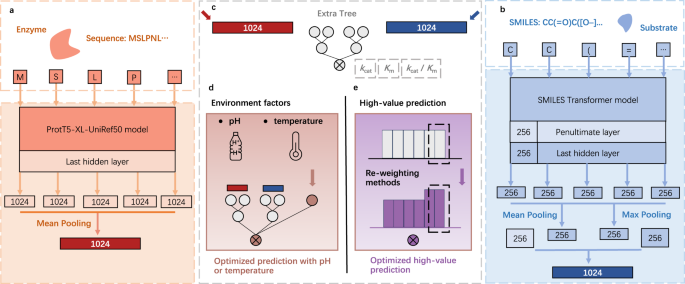
The study of enzyme catalysis efficiency to a specific substrate is a fundamental biological problem that has a profound impact on enzyme evolution, metabolic engineering, and synthetic biology. The key indicators of enzyme catalysis efficiency includes enzyme turnover number (kcat), Michaelis constant (Km), and catalytic efficiency (kcat / Km). While some researchers have provided diverse tools to predict these parameter values using information from diverse dimensions, the limited performance of current prediction tools on diverse tasks hinders their practical applications. Driven by a demand for understanding of enzyme catalysis efficiency on metabolic engineering and industrial applications, Dr. Xiaozhou Luo and his team embarked on an aspiration to reshape the prediction model for a precise prediction. Recent breakthroughs in deep learning, particularly in the area of unsupervised learning from natural language processing, have led to novel data representation approaches that have been applied to biological problems with great success. We recognized the powerful potential of big language model to expedite this process, leading to the birth of the UniKP framework.
🚀 Revolutionary Technology: Big Model Assisting Predictions
UniKP, leveraging large pretrained language models and machine learning algorithms, presented a powerful prediction ability as a novel approach to predict three diverse enzyme kinetic parameters. UniKP demonstrated remarkable performance compared to the previous state-of-the-art model, in the kcat prediction task with an average coefficient of determination of 0.68, which was 20% higher. This framework also has strong generalizability on Michaelis constant (Km) prediction and kcat / Km prediction. We speculated that pretrained models have greatly contributed to the performance of UniKP by creating an easily learnable representation of enzyme sequences and substrate structures using unsupervised information from the entire database. This confirms the powerful ability of big model.
🔍 More Realistic Predictions: A Two-layer Framework with Environmental Considerations
Bridging the gap between theoretical models and practical applications, we further considered the influence of environmental factors by introducing the EF-UniKP framework. We incorporate different diverse datasets enhances the accuracy of predictions. Based on two newly constructed datasets with pH and temperature information, respectively, EF-UniKP shows improved performance compared to the initial UniKP and revised UniKP. To our knowledge, this is an accurate, high-throughput, organism-independent, and environment-dependent kcat prediction. Additionally, this approach has the potential to be extended to include other factors, such as cosubstrate and NaCl concentration.
🌐 Reshaping Data for Targeted Predictions
Furthermore, an analysis of existing kcat datasets presented a highly imbalanced distribution, with the majority of samples concentrated in the middle and few at the extremes, resembling a normal distribution. This imbalance led to higher errors in predicting high kcat values. To address this issue, we employed four representative reweighting methods. These methods significantly reduced errors in the high-value range, with Class-Balanced re-Weighting methods (CBW) showing the best performance, reducing root mean square error by 6.5% for high kcat values. CBW argues that as the number of samples increases, the additional benefit of a newly added data point will diminish, indicating information overlap among the data. Therefore, it further optimizes the weight by taking into account this issue. In the kcat dataset, enzymes with high homology, substrates with similar structures, and enzyme mutants contain overlapping information, which could explain why CBW is effective in this particular case.
🧪 UniKP Empowers Enzyme Discovery and Evolution
To explore the practical application of UniKP and its derived framework in enzyme engineering, we focused on the key rate-limiting enzyme in flavonoid synthesis, Tyrosine Ammonia Lyase (TAL), collaborating with researchers in our wet-lab platform. UniKP effectively identified highly active TAL enzymes, resulting in significantly improved catalytic efficiency for both enzyme discovery and evolution. RgTAL-489T exhibited a 3.5-fold increase in kcat / Km compared to the wild-type TAL. For EF-UniKP, in considering environmental factors, accurately identified high-activity TAL enzymes, with five sequences showing superior kcat and kcat / Km values compared to the wild-type TAL, with the highest kcat / Km value being 2.6 times higher under specific pH condition. These results confirmed UniKP's effectiveness in enzyme discovery and evolution tasks, providing a valuable tool for biologists.
🔮 Conclusion and Outlook
A central objective in synthetic biology is the development of a digital cell, poised to revolutionize our methods of studying biology. A critical prerequisite for this endeavour is the meticulous determination of enzymatic parameters for all enzymes within the pathway. Tools assisted by artificial intelligence illuminate this challenge, offering a high-throughput approach to predicting enzymatic kinetics. UniKP's fusion of AI and biological experiments marks a breakthrough in predicting enzyme kinetics. This work also highlights AI's significant role in synthetic biology, providing valuable insights for interdisciplinary research and applications. We will also collaborate with Synceres Biotech corporation to explore the industrial applications and unlock the full potential of this technology.
Follow the Topic
-
Nature Communications

An open access, multidisciplinary journal dedicated to publishing high-quality research in all areas of the biological, health, physical, chemical and Earth sciences.
Related Collections
With Collections, you can get published faster and increase your visibility.
Women's Health
Publishing Model: Hybrid
Deadline: Ongoing
Advances in neurodegenerative diseases
Publishing Model: Hybrid
Deadline: Mar 24, 2026




Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in