Causality in predictive analytics
Published in Protocols & Methods


In the summer of 2018, the idea of applying causal reasoning to medical image analysis came to be a major focus for us, spurred on by Judea Pearl and Dana Mackenzie's 'The Book of Why' [1]. Pearl and Mackenzie make a compelling case for how causality should play a central role in modern data science and predictive analytics. We started to ask ourselves how a causal perspective could augment our own research, at the intersection of machine learning and medical imaging. The idea that causal reasoning could help us to better understand some of the key challenges we face when developing predictive models for clinical applications captured our imaginations.
At that time, deep learning had already taken the field of medical image analysis by storm. Impressive performance had been achieved for automated detection and classification of disease, and new state-of-the-art results were reported on a regular basis for challenging tasks like automatic segmentation of diverse pathological structures (such as brain tumours). The availability of well-curated and reasonably large, public datasets has contributed much to the success of these methods. Annual challenges, held to test and evaluate the latest algorithms for various tasks, have consistently been dominated by deep learning algorithms, often showing performance on par with human experts. However, only a few algorithms have successfully made the transition from the lab to the clinic. Two possible reasons for this failure have been discussed extensively in the literature and in our Perspective.
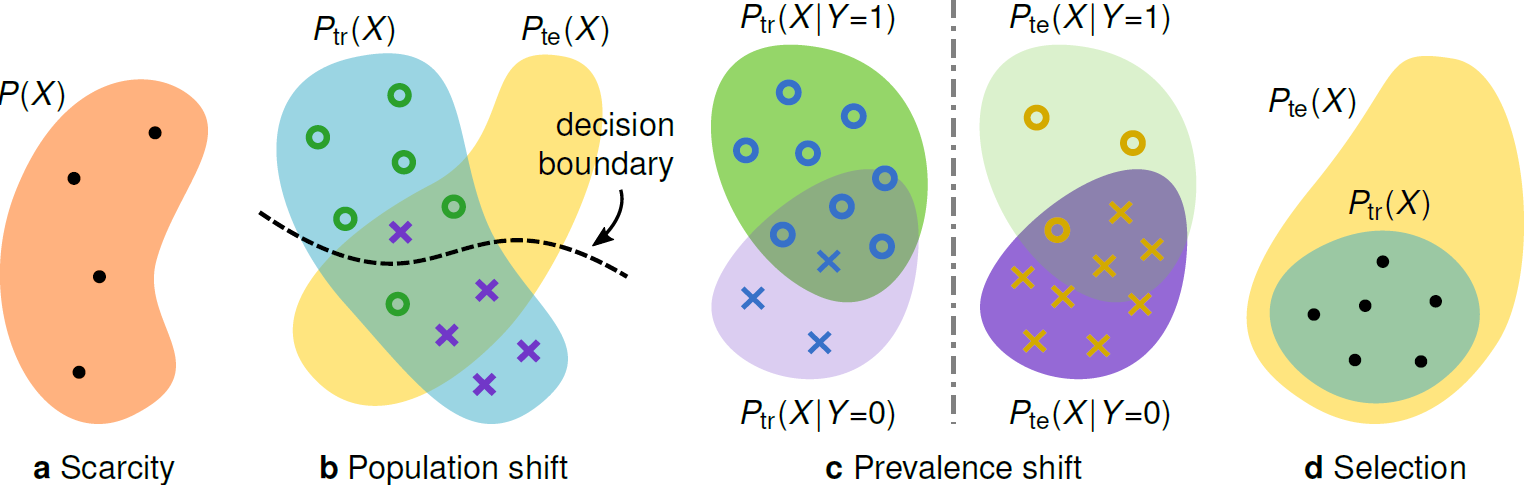
First, it quickly emerged that many algorithms are not sufficiently robust, meaning their performance may drop considerably when tested on data that differs from the datasets used during development. In medical imaging, this often occurs when data is acquired from different machines or clinical sites. This problem of generalisability is well studied in machine learning, and, while strategies exist to mitigate it when the cause of the dataset shift is known, there has been no systematic characterization of this issue in medical imaging.
Second, whenever a new clinical application is explored, one starts from scratch in terms of data collection and annotation. Therefore, researchers in medical image analysis are constantly faced with a shortage of high-quality annotated data to train deep-learning algorithms. To overcome this challenge, one may opt to use data augmentation techniques or even try to leverage entirely unlabelled images for improving predictive models. Yet, these techniques are not well understood and it often remains unclear in which cases they may prove beneficial.
Our Perspective reveals that the answers to some of those questions are hidden in the stories behind the data. Here, the language of causality allows us to meticulously describe the processes that generated the data we use to build predictive models. Causal reasoning both allows and requires us to clearly communicate our assumptions about the world, and can help identify potential pitfalls such as dataset shift and sample selection bias, or even whether certain learning strategies should be considered at all. But, this is really only the first step toward climbing the ladder of causation [2].
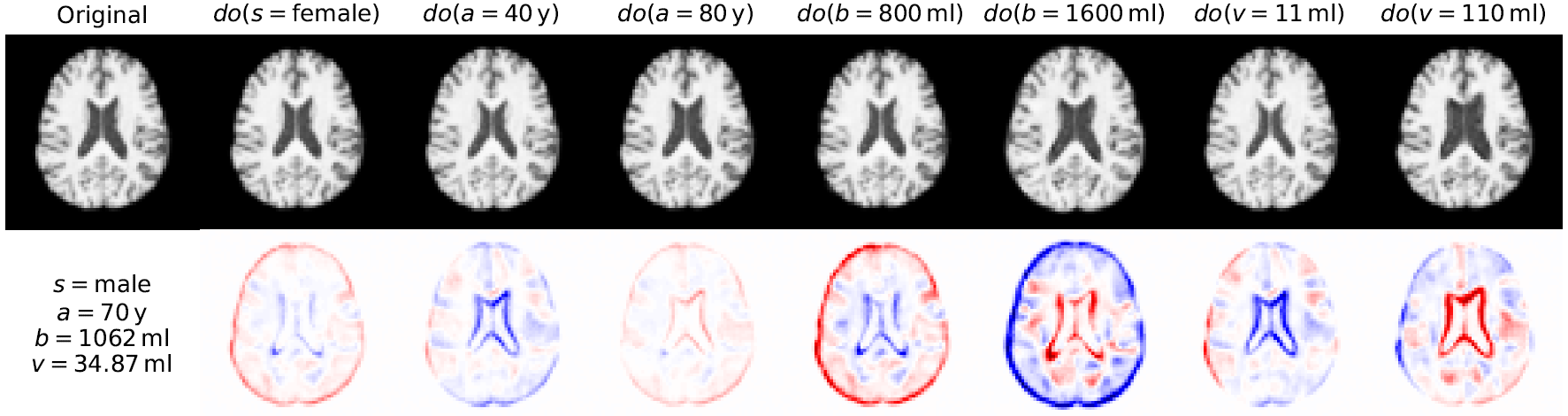
The next natural question is whether we can directly integrate causal assumptions about the world into our models, which gives rise to the field of causal representation learning [3]. Our own early attempts to integrate structural causal models into deep learning have led to some promising results, showing it is possible to generate plausible counterfactual images [4] for questions such as 'What would this patient's brain look like if they were 10 years older?' (see Fig. 2). Being able to answer counterfactual 'what if' questions may well hold the key to unlock the full potential of AI in predictive analytics and healthcare applications—an exciting area of research for the decades to come.
References
[1] Judea Pearl and Dana Mackenzie (2018). The Book Of Why: The New Science Of Cause And Effect. Basic Books, New York.
[2] Judea Pearl (2009). Causality: Models, Reasoning, and Inference (2nd ed.). Cambridge University Press.
[3] Bernhard Schölkopf (2019). Causality for Machine Learning. Preprint at https://arxiv.org/abs/1911.10500.
[4] Nick Pawlowski, Daniel C. Castro, and Ben Glocker (2020). Deep Structural Causal Models for Tractable Counterfactual Inference. Preprint at https://arxiv.org/abs/2006.06485. Demo and code at https://github.com/biomedia-mira/deepscm.
Follow the Topic
-
Nature Communications

An open access, multidisciplinary journal dedicated to publishing high-quality research in all areas of the biological, health, physical, chemical and Earth sciences.
Related Collections
With Collections, you can get published faster and increase your visibility.
Women's Health
Publishing Model: Hybrid
Deadline: Ongoing
Biosensing
Publishing Model: Hybrid
Deadline: Jun 30, 2026



Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in