Household Survey Data Matters: New Insights into the Geography of Data Quality across 35 African Countries
Published in Social Sciences, Research Data, and Public Health
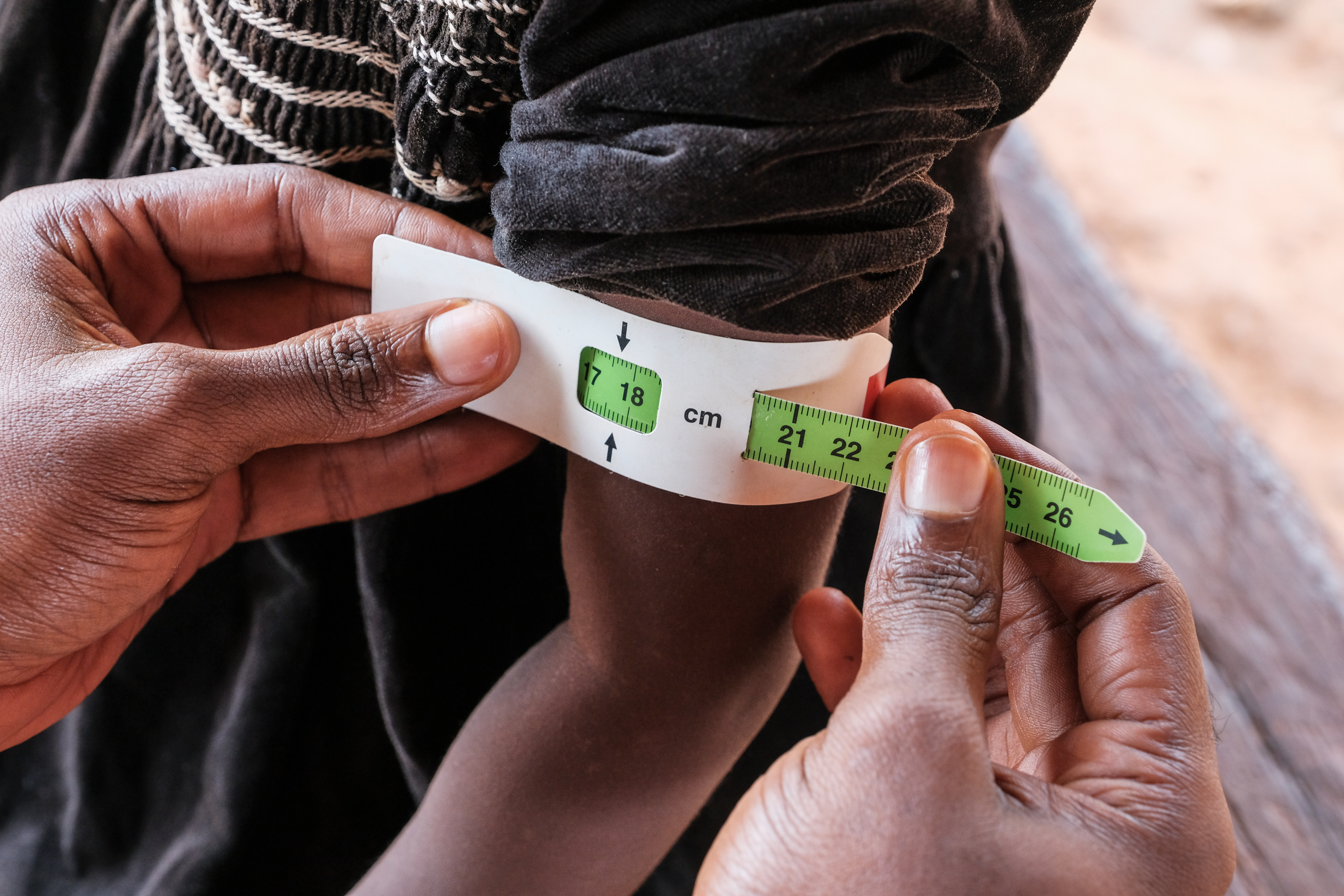
Household surveys like the Demographic and Health Surveys (DHS) have long been the foundation of global health and development research. They provide critical data on fertility, mortality, education, nutrition, and wealth — data that are widely used in research and directly shape policies, health interventions, and funding decisions at both national and local levels.
However, our new study, published in Nature Communications, reveals a cucial and yet overlooked issue: household survey data quality is not uniform within countries.
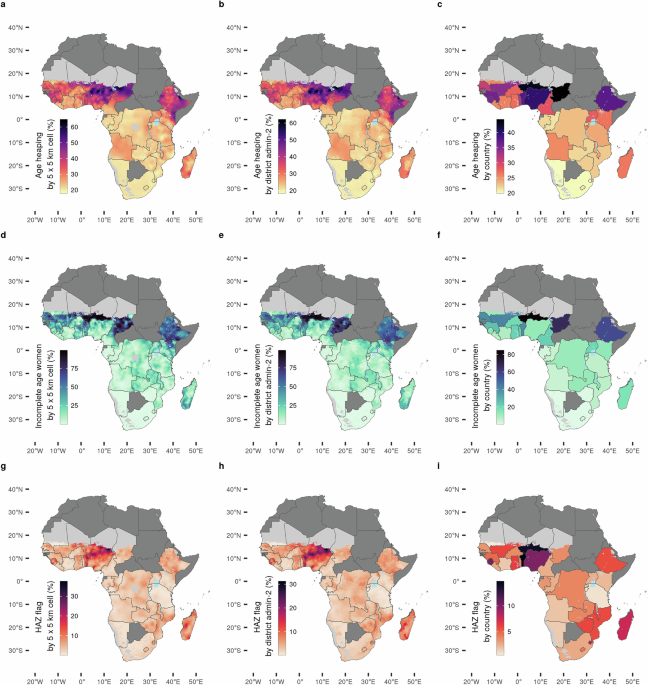
Using DHS data from 35 countries in sub-Saharan Africa (collected between 2006 and 2022), we combined geocoded survey data with Bayesian model-based geostatistics and spatial covariates such as nighttime light emissions and population density. This allowed us to predict and map three widely used indicators of data quality — incomplete reporting of women’s ages, age heaping, and flagged child anthropometric measurements — at a 5×5 km spatial resolution.
The findings are show substantial variation in the geographic distribution of data errors:
- Data quality systematically declines with increasing distance from major settlements.
- Remote and rural populations — often among the most vulnerable — are more affected by measurement errors and missing data.
- National averages conceal significant local and regional variation.
Importantly, we found only weak correlations between different types of data errors, and between systematic measurement error and statistical uncertainty. In other words, the spatial patterns of bias and missingness differ markedly from patterns of simple sampling imprecision. This means that researchers and practitioners cannot rely on measures like confidence intervals alone to assess the reliability of subnational data.
Why this matters
Policy, programming, and research increasingly require fine-scale, subnational estimates. Public health interventions, vaccination campaigns, nutrition programs, and education policies are now routinely designed and evaluated at district or community levels. Yet if the underlying survey data are systematically biased in certain regions, interventions can be misdirected, resources misallocated, and vulnerable populations left underserved.
For example, even seemingly minor inaccuracies — such as misreporting a child’s birth month or age — can significantly distort estimates of child stunting rates, which are sensitive to age reporting. This can mask true needs in certain areas or falsely suggest progress where challenges persist.
Moreover, missing or unreliable data may lead to faulty modeling of health risks, poverty estimates, or service coverage. In turn, this can reinforce inequalities by directing interventions towards areas that already have better data — a classic case of the “streetlight effect.”
Our results underscore the need for much greater attention to subnational data quality when interpreting household survey results and designing policies based on them.
What we did
To assess subnational variations in data quality, we focused on three indicators:
- Incomplete age reporting among women aged 15–49 (missing month or year of birth).
- Age heaping among adults aged 23–62 (ages ending in 0 or 5, suggesting inaccurate reporting).
- Flagged height-for-age (HAZ) scores among young children (indicating biologically implausible or missing anthropometric measurements).
We used Bayesian geostatistical models to predict these indicators across unsampled locations, leveraging auxiliary data on settlement patterns, terrain ruggedness, population density, and nighttime light emissions. This approach allowed us to produce high-resolution, spatially continuous maps of predicted data quality across 35 countries.
We also explored whether greater remoteness — operationalized as increasing distance from illuminated settlements — was associated with poorer data quality. Across nearly all countries and indicators, the answer was yes: data quality declines steadily with remoteness, and this pattern appears to be persistent over time.
Furthermore, we compared spatial patterns of systematic measurement errors with patterns of statistical uncertainty (e.g., wide confidence intervals due to small sample sizes) for related health indicators like contraceptive use and child stunting. We found that these two dimensions of data quality overlap only partially, meaning that high sampling uncertainty does not necessarily indicate high measurement error, and vice versa.
A finding at a pivotal moment
This work arrives at a critical moment. The DHS Program — the most comprehensive and trusted source of household survey data in low- and middle-income countries — is currently facing severe funding cuts. These cuts risk dismantling one of the most vital components of the global public health and development data infrastructure.
Rather than withdrawing support, our findings argue strongly for strengthening the DHS Program and similar initiatives. Targeted investments could help improve enumerator training, refine sampling strategies, and develop new tools to reduce measurement errors — especially in remote and marginalized areas where data quality challenges are most acute.
Without reliable, geographically representative data, global health and development efforts risk operating blind — precisely where evidence-based decision-making is needed most.
🔗 Read the full paper here: Nature Communications Link
This blog was written by Amelia B. Finaret of Allegheny College, Meadville, USA and Valentin Seidler of Central European University in Vienna, Austria.
Follow the Topic
-
Nature Communications
An open access, multidisciplinary journal dedicated to publishing high-quality research in all areas of the biological, health, physical, chemical and Earth sciences.

Related Collections
With Collections, you can get published faster and increase your visibility.
Women's Health
Publishing Model: Hybrid
Deadline: Ongoing
Biosensing
Publishing Model: Hybrid
Deadline: Sep 30, 2026


Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in