The Hidden Power of Interactive Parallelization: How AI and Humans Are Optimizing Scientific Computing
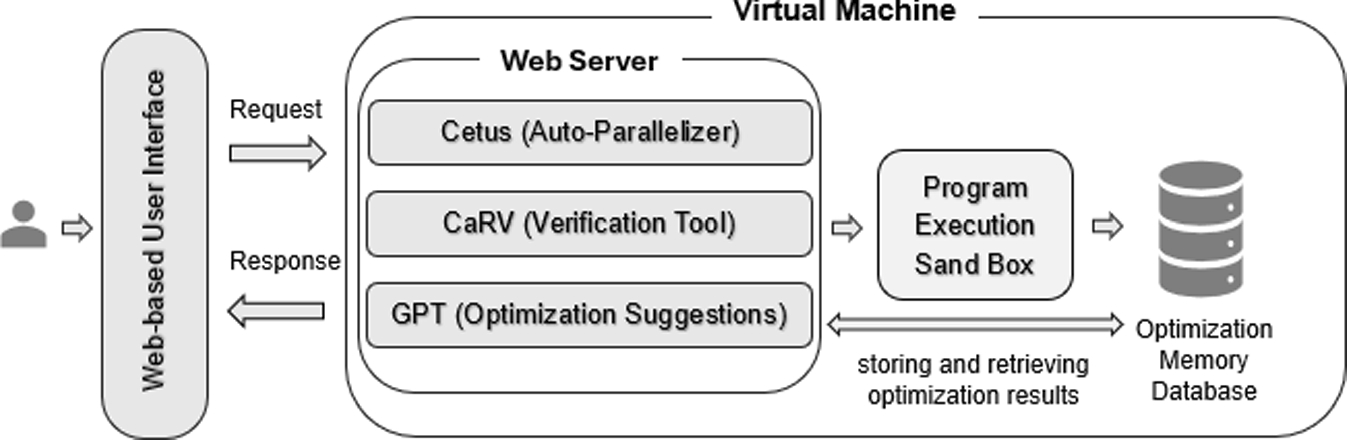

This research was not just about creating another tool—it was about empowering users in the optimization process, ensuring that automated parallelization aligns with real-world needs rather than rigid compiler assumptions.
The journey began with a frustrating reality: automatic parallelization tools often fail to deliver optimal results because they lack contextual knowledge of the application domain. Manual parallelization, on the other hand, is time-consuming and error-prone, making it an impractical solution at scale. Researchers and developers were left navigating a gray area—needing automation but also requiring control over the process.
This dilemma fueled the development of iCetus, an interactive parallelization environment that combines the strengths of both worlds—leveraging compiler analysis while keeping the user in the loop. Unlike traditional tools that passively apply optimizations, iCetus actively involves developers, enabling them to fine-tune, validate, and enhance code performance for greater efficiency.
Follow the Topic
Related Collections
With Collections, you can get published faster and increase your visibility.
High-Productivity Programming Systems for HPC Applications
In the ever-evolving world of computing, the line between software and hardware has become increasingly larger. As we push the boundaries of what is possible with technology, the need for high-productivity programming solutions that can harness the power of modern hardware has never been more critical.
This Special Issue (SI) aims to bring points of discussion into the High Performance Computing (HPC) and scientific community about key issues on finding a compromise between high levels of abstraction (programming productivity) and meeting the challenges of performance, power consumption, and fault tolerance. This SI addresses the recent experiences in programming languages/models design for exa-scale computing systems, which can contribute to the problem of programming complex HPC systems in a productive, efficient, and reliable way. This SI provides a great opportunity for the HPC community to present new approaches for exploiting the massive parallelism that is provided by the abundance of different kinds of parallelism in today’s and future HPC systems. Besides the conventional use for coarse or fine-grain parallelism in applications, our scope is to explore new approaches that enable future software systems to become more self-aware, reasoning about its internal state, and making decisions to prioritize changes in the execution of applications when necessary, putting the focus on areas such as performance tuning and power management.
Publishing Model: Hybrid
Deadline: Apr 30, 2026



Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in