Uncovering unpublished radiocarbon data from Late Quaternary megafauna fossils
Published in Chemistry, Ecology & Evolution, and Arts & Humanities
Many blog posts on biodiversity published in Behind the Paper explore the mesmerizing facets of the natural world. This one ventures into the trenches, jungles and depths of chronological data on mammal fossils—vast amounts of information amassed to document and date the existence of extraordinary creatures, like woolly mammoths, cave lions and Siberian unicorns.
THE CHALLENGE
Reconstructing the environments, climates and human contexts that shaped biodiversity in past ecosystems depends fundamentally on reliable fossil chronologies. Radiocarbon dating is the primary technique for building those chronologies for fossils up to ~ 50,000 years old, spanning the Late Pleistocene and the Holocene.
I have just published a new dataset, MEGA14C, in Scientific Data and figshare. MEGA stands for megafauna (large-bodied animals, often >44 kg) and 14C denotes radiocarbon (carbon-14), a radioactive isotope of carbon. The dataset includes 11,715 radiocarbon ages derived from collagen extracted from fossil skeletal materials (antler, bone, horn, ivory, teeth) of mammalian megafauna—all obtained by counting radiocarbon atoms in a particle accelerator. Taxonomically, the dataset spans 8 orders, 23 families, 78 genera, 133 species and 18 subspecies across Eurasia and North America (The Holarctic region).
Radiocarbon dating estimates an organism’s time of death based on the fact that, as dead biological tissues degrade and fossilize, half of their radiocarbon content decays approximately every 5,730 years. For dating skeletal materials, collagen must first be extracted and purified to remove carbon contaminants, a process known as pretreatment. The remaining carbon isotopes are then measured to estimate age. Pretreatment is the dominant factor controlling dating accuracy, defined as the difference between a measured age and a fossil’s true age. As contamination increases, radiocarbon ages become progressively biased, with errors ranging from decades to millennia. Such errors can fundamentally distort paleoecological and archaeological interpretations that rely on accurate timing.
MEGA14C focuses on three collagen pretreatment methods, as justified in a previous study. From a chemical perspective, XAD purification and hydroxyproline isolation are the most accurate, but also the most complex and expensive methods, whereas ultrafiltration is the most popular, simpler and cheaper approach.
- ultrafiltration: gelatinized bone filtered through a 30 kDa membrane to retain high-molecular-weight material assumed to contain uncontaminated collagen.
- XAD purification: collagen-derived amino acids passed through a non-polar resin to remove contaminants prior to dating the total amino-acid fraction.
- hydroxyproline isolation: collagen-derived amino acids isolated chromatographically prior to dating hydroxyproline, the most bone-specific amino acid.
|
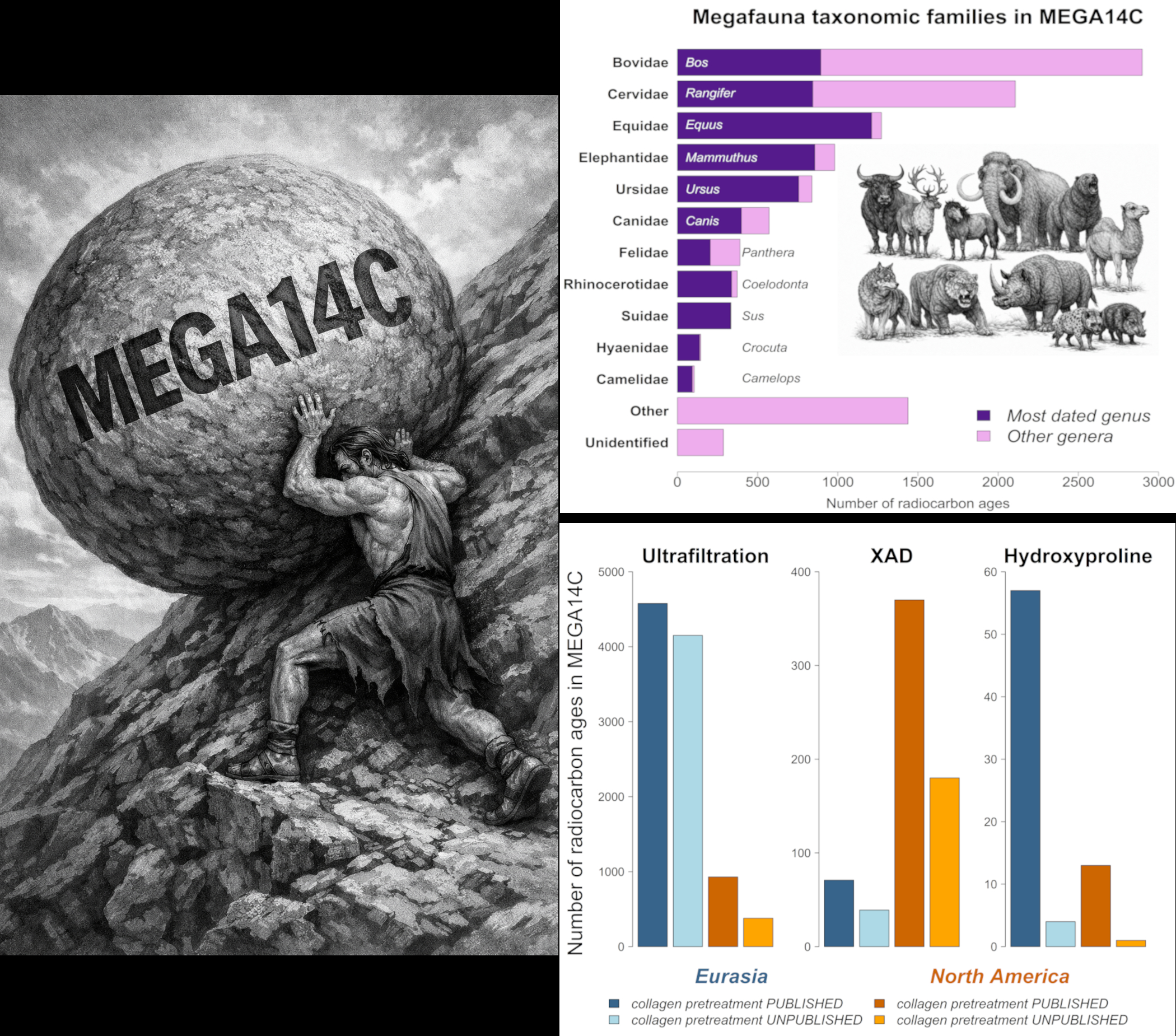
MEGA14C is a dataset of radiocarbon ages for Holarctic megafaunal mammals, curated by collagen pretreatment method, and compiled over 7 years of heavy-lifting work - as symbolized by the myth of Sisyphus (image on the left). To the right, the top barplot ranks mammal families according to the number of radiocarbon ages in the dataset, with the dominant genus indicated for each family. The lower barplot shows the number of radiocarbon ages collated by pretreatment, revealing that approximately 50% lack published pretreatment information. Regional differences in pretreatment use reflect historical and geographic practices rather than methodological accuracy: ultrafiltration and hydroxyproline are more common in Eurasia, whereas XAD purification was developed and has been primarily applied in North America. |
 |
THE EFFORT
Unlike existing radiocarbon datasets, MEGA14C systematically documents the chemical pretreatment applied to each dated fossil sample. Such information is rarely compiled because it is extremely time-consuming to retrieve from the scientific literature. I had previously assembled the FosSahul dataset 1.0 (see version 2.0) for Australian megafauna in approximately 1 year. The decisive difference with MEGA14C was the need to recover not only published but also unpublished pretreatment information for every sample. Although this distinction might appear subtle, it ultimately extended the project to 7 years.
Almost 50% of published radiocarbon ages lacked reported pretreatment information, falling short of the core principle of research reproducibility. Recovering these missing data required >10,000 personal communications, drawn from >100,000 emails exchanged with thousands of researchers, laboratories, museums, and public and private agencies. I invested >30,000 person-hours (>1,200 days), primarily tracing radiocarbon chemistry. Communication followed a fractal pattern: a single inquiry often opened multiple new lines of investigation, each requiring independent follow-up. The curatorial effort per radiocarbon age ranged from 1 email exchange completed in 1 day to >50 exchanges spanning over 5 years.
My strategy prioritized direct requests to data custodians and, where necessary, follow-up requests to radiocarbon laboratories. Most exchanges were professional and constructive, as documented in a companion study, although reactions ranged from openly supportive to unexpectedly nasty, illustrating the complexity of this work.
| Examples of contrasting interactions with two prominent scientists during the compilation of the MEGA14C dataset, following multiple requests for unpublished information over extended periods. MEGA14C included only personal communications regarding the technical aspects of radiocarbon ages (mostly pretreatment, dated material, and fossil geolocation and taxonomy) and therefore excluded interactions of the type illustrated below. The identities of the two scientists have been anonymized. |
|
“... The job you have done in tracking down pre-treatment methods is fantastic. I didn’t do it, not because I didn’t realise the value of it but because I didn’t think it was feasible! I had to smile at your comment that all radiocarbon dates are wrong unless proven otherwise because I had many discussions on this point with two archaeologists from here [colleagues’ names], who say exactly the same thing! More precisely, they told me that “90% of radiocarbon dates are wrong”… I agree to caution and digging into it as deeply as possible, as you have done. I look forward very much to your papers!” (pers. comm., 21/05/2020) |
|
“... I had to slightly laugh when I saw the date listed for my quote (2021) [in an email request for unpublished pretreatment data]. One loses track of time, but I have to say that the volume of work, in terms of checking, verifying, emailing, commenting on previous dates and methods on my part and others in the [lab name], has been quite high in terms of your project. Ordinarily one would expect this effort to be reflected more than a simple acknowledgement, but anyway it is what it is. Let’s just say that I wish you the best of luck with the papers and so on, but it might be best from now on to find someone else to do the donkey work of checking and verifying the many radiocarbon dates and methods used to generate them” (pers. comm., 21/07/2025) |


The companion study explains that unpublished pretreatment information is often buried in research notes, laboratory reports or legacy digital files, and that pathways for accessing such data are frequently fragmented and difficult to reconstruct. This is further complicated because researchers who act as custodians of radiocarbon records might have died, retired, left academia, or have limited time or interest in contributing to data-compilation efforts.
Accessing pretreatment information directly from radiocarbon laboratories presents additional obstacles: some laboratories have been dismantled, and those that remain operate under varying confidentiality policies regarding the release of radiocarbon chemistry data for their clients’ samples to third parties such as data curators. Consequently, substantial amounts of valid radiocarbon data likely remain inaccessible, stored on outdated computers, hard drives and printed reports.
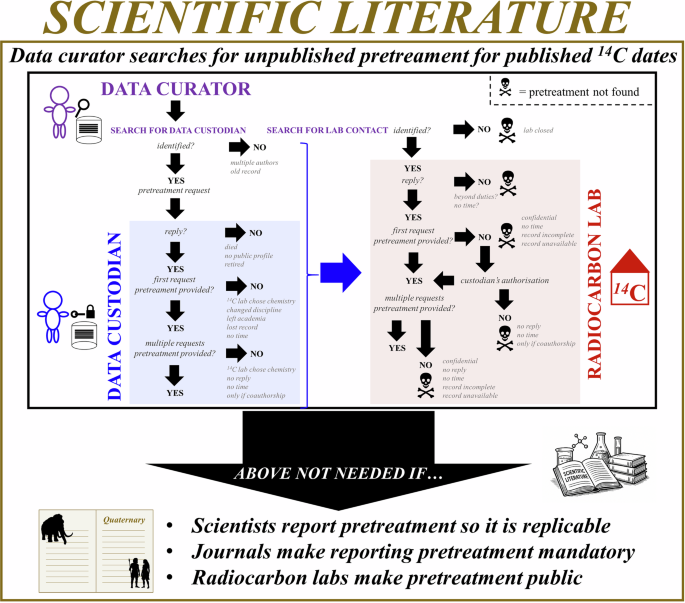
| Tracking down unpublished pretreatment information for MEGA14C. The process usually involves three parties: the data curator (that’s me, compiling the dataset), the data custodian (the person who owns the data, usually the one who funded the dating or submitted the samples), and the radiocarbon lab. The curator starts by contacting the custodian, and if that fails, reaches out to the lab. A black-skull symbol marks a “dead end”, where the trail goes cold and the pretreatment information cannot be recovered. This figure, published in Scientific Data, summarizes arguments from the companion paper published in the Journal of Quaternary Science. |
|
SURPRISES ALONG THE WAY
I began this project in April 2018 as a postdoctoral researcher at the Australian Centre for Ancient DNA. I was tasked with assembling a comprehensive dataset of collagen radiocarbon ages for extinct Holarctic megafauna, with the aim of reassessing earlier work published in Science on Late Pleistocene megafauna extinctions. The initial task focused on ages derived from collagen ultrafiltration, and later expanded to include additional ages from (1) hydroxyproline and XAD-purified amino acids, and (2) extant and extinct megafuna, both domesticated and wild. This expansion led to the involvement of geochronologist Tom Stafford from April 2019 onward.
In December 2019, the dismissal of my supervisor triggered widespread institutional disruption and effectively dissolved the project’s original objective. I continued working without in-house supervision, first full-time until my contract ended in April 2020, and then part-time through a series of short-term contracts until December 2020. This period coincided with the onset of the COVID-19 pandemic, during which researchers were advised to work in isolation. The death of my father during the pandemic prompted my return to Spain, where I subsequently held three consecutive full-time postdoctoral positions between 2021 and 2024, followed by a fourth position ongoing by the time this blog post has been published.
As MEGA14C progressed across my appointments in Australia and Spain, the effort required to curate unpublished information grew increasingly demanding. Balancing this work alongside my formal academic appointments proved challenging and required significant adjustments, including withdrawing from collaborative projects and missing professional deadlines. Paradoxically, like Sisyphus in Greek mythology, pushing a boulder uphill without assurance of success, the methodical work of dataset construction became therapeutic. MEGA14C became the only constant thread, providing a sense of continuity across years marked by professional transition, geographic mobility and family upheavals.
GETTING IT PUBLISHED
The peer-review process lasted 18 months, from initial submission in November 2024. Throughout, I continued updating the dataset to incorporate newly released radiocarbon ages.
Manuscript Version-1 received two reviewer reports in February 2025. Both were constructive and I addressed them within two weeks. In addition, the editors requested substantial revisions in two principal ways, which halved the length of the manuscript. First, background information and dataset summaries were shortened and streamlined. Second, the editors requested the removal of the detailed description of how unpublished radiocarbon pretreatment information had been obtained through personal communications. I contested this second request, because the primary novelty of the dataset lies precisely in the direct technical validation of unpublished information with the individuals involved in generating each radiocarbon age. I complied by reducing this description to a minimal summary within the manuscript, but developed the full methodological account in the companion paper. The editors indicated that the companion paper could not be cited in the dataset manuscript without a DOI. I therefore prepared and submitted the companion paper in April 2025, and it was accepted in May 2025, representing my fastest publication turnaround. I could now formally cite the companion paper in the dataset manuscript, allowing the submission process to proceed.
Manuscript Version-2 was submitted in August 2025, but was returned with three reiterated editorial requests, even though the reviewers were fully satisfied with the revised version. First, the editors required removing the dataset name (MEGA14C) from the manuscript title, despite this not being mandated by the journal’s author guidelines and contrary to widespread precedent in Scientific Data; yet I complied. Second, they required that the dataset be made public (figshare), which raised my concerns about data confidentiality in the event the paper was rejected or withdrawn. Nevertheless, I complied, and the public dataset (including verbatim personal communications) immediately attracted hundreds of views and tens of downloads. Third, the editors instructed that contributors providing unpublished information be anonymized, their personal communications removed or explicitly written consent obtained from each of them. I had stored these communications in a single dataset column serving as core evidence for technical validation. It contained exclusively technical information (e.g., a dated bone was a femur not a molar; the pretreatment was X; the fossil belonged to species Y, along with name + surname of communicator and date of communication). I contested this requirement and resubmitted in September 2025 (Manuscript Version-3), but the manuscript was returned for the same reason.
I sought assistance in AI tools to anonymize personal communications. However, the trials revealed that the extreme heterogeneity of these entries rendered automated anonymization unreliable, ultimately requiring manual, row-by-row verification in a spreadsheet. This approach was impractical given the scale of thousands of contributors across >10K records. Editorial correspondence during this period unfortunately suggested a misunderstanding of the dataset’s scale and complexity, with one editor severely underestimating that it contained <150 individual names!
I must admit I briefly went a bit nuts at the lack of editorial understanding of the magnitude of the work. At this stage, I prepared to withdraw the submission and sent pre-submission inquiries to two journals, fully explaining the case with Scientific Data: Data in Brief declined, and Ecology was unable to reach a decision within a month. Ultimately, I took a deep breath… reluctantly removed the personal-communications column from the dataset, and submitted Manuscript Version-4 to Scientific Data, along with the amputated dataset to figshare in December 2025. The manuscript was accepted on 8 January 2026 but... was it?
PAYING THE FEE
Following acceptance, I submitted the revised proofs and forwarded the publication-fee invoice to the University of Adelaide, now known as Adelaide University. Due to an institutional merger, the University had previously informed me that they could only cover publication fees invoiced before the end of 2025. After so many years, this project had effectively lost institutional tracking and become primarily a personal endeavor.
Two of my co-authors (from the UK and the USA) and my current employer in Spain generously agreed to share the costs, but the journal did not accept split invoices in different currencies. That seemingly minor complication took over three months to resolve, delaying payment approval and tripling the invoice administration fees, with the total fee ultimately increasing to €2,555. Of that figure, I contributed €85 from my salary to reconcile the final amount. Though symbolic, this final cost brought to a close a journey that had tested every measure of my character. The final version of the manuscript was published on 9 April 2026. Amen.
WHAT IT MEANS
Beyond the reality that work interacts with personal lives in complex ways, I will finish this blog post with what, after all, is most important: the scientific implications of the study. After communicating with thousands of archeologists, paleoecologists and paleontologists over the course of the project, my impression is that the majority of scientists entirely attribute pretreatment choice (radiocarbon chemistry) for their study fossil material to the radiocarbon lab. They rarely question whether the radiocarbon measurements they obtain might be incorrect, and many regard the description of radiocarbon chemistry as a technical detail beyond their responsibility that they need not include in their papers. This resembles doing a statistical test in a research paper and not explaining what test was done. Such lack of reporting standards should never pass the peer review process by both editors and reviewers, as it renders the data and analyses irreproducible.
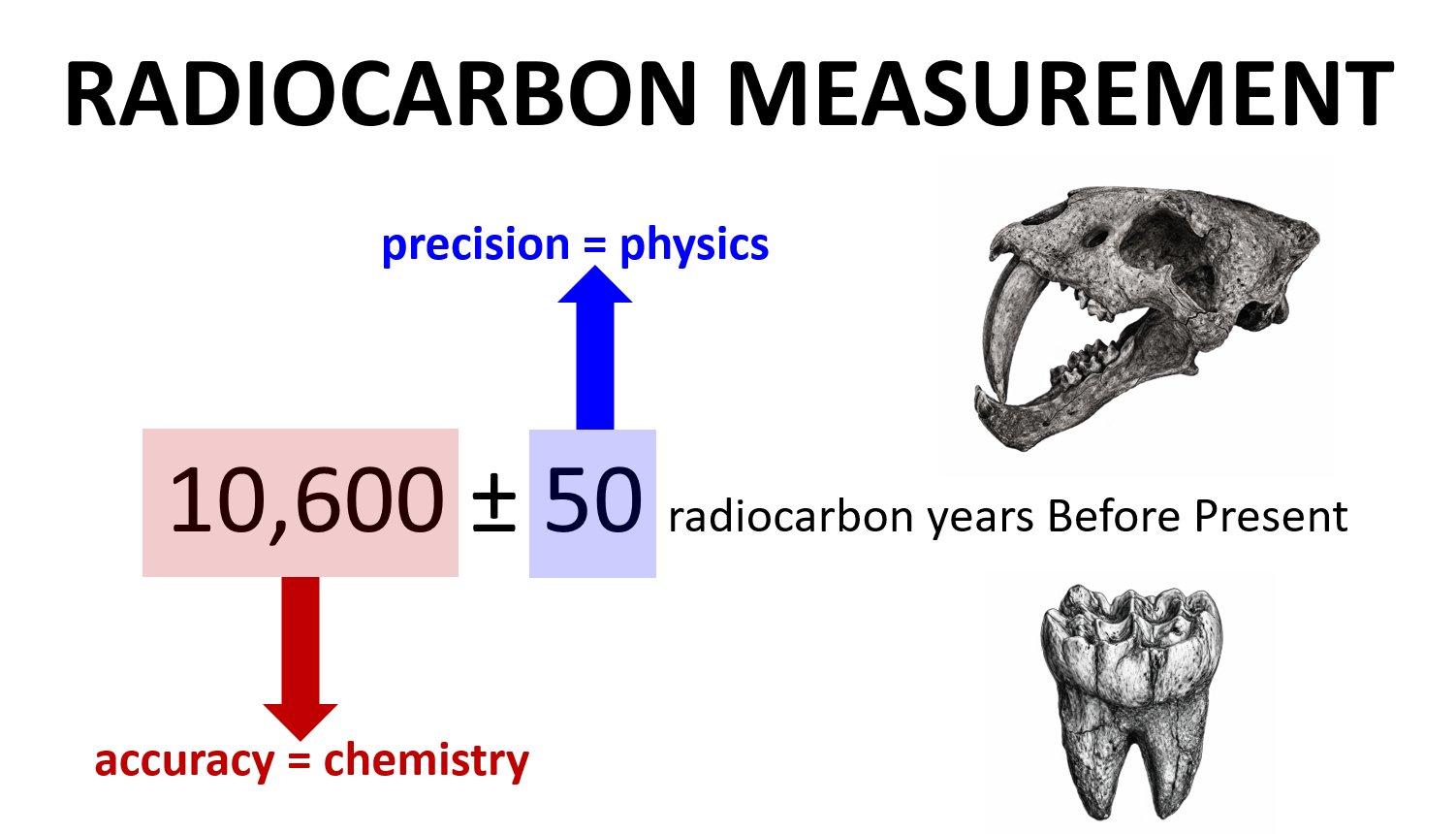
| Accuracy and precision in radiocarbon measurements. Radiocarbon ages are typically reported as a value with an associated uncertainty—for example: a fossil tooth dated at 10,600 ± 50 radiocarbon years Before Present. The uncertainty (± 50 years) reflects precision and relies on the physics of the radiocarbon measurement: the statistical error of counting radiocarbon atoms in a particle accelerator. The age itself (10,600 years), however, reflects accuracy and relies on the chemistry of the radiocarbon measurement: whether the radiocarbon atoms being counted truly belong to the fossil tooth OR a fraction was incorporated from the burial environment after the animal’s death. If chemical collagen purification does not fully remove contamination, the particle accelerator will count both endogenous and exogenous radiocarbon as if it were native to the sample. As a result, contamination can shift apparent fossil ages by decades to millennia, leading to fossils and species being placed in incorrect climatic, ecological and human contexts. |
|
The three photos show: [top] a rib fragment of the extinct Mexican horse (Equus conversidens) from Wally's Beach, Canada, and dried collagen [bottom-left] and collagen gelatin [bottom-right] from the fragment prior to further purification steps and final dating. This archaeological site illustrates the use of radiocarbon dating to trace human activity and faunal extirpations around 13,000 years ago. Courtesy of Thomas Stafford Jr. |

MEGA14C showcases the practical challenges of curating research data at scale. By documenting radiocarbon chemistry alongside radiocarbon ages, the dataset provides a robust foundation for interpreting megafaunal events and for revising hypotheses, analyses and interpretations (many published in Nature, Science and other multi-disciplinary journals that guide scientific knowledge) that often rely on radiocarbon ages that are inaccurate and/or cannot be reliably ranked. Data quality should be considered at least as important as data quantity. Currently, the development and application of modern collagen purification methods and the production of high-quality radiocarbon data lag behind the growth in computational capacity capable of processing terabytes of information. This imbalance creates a persistent and often overlooked bottleneck in large-scale chronological research, and calls into question the extent to which the timelines of archaeological and paleoecological events are understood.
ACKNOWLEDGMENTS
I am deeply grateful to the co-authors of the study (Tom Stafford Jr., Kieren Mitchell, John Southon, Chris Turney) for their intellectual and financial support, and to Ana Rey Simó (Department of Biogeography and Global Change / DBGC-MNCN-CSIC) for her assistance in facilitating the contribution to the publication costs. Corey Bradshaw and Tom Stafford Jr. kindly proofread an earlier version of this blog post.
The study was made possible through access to resources and employment opportunities facilitated by Christian Huber, Kieren Mitchell and Laura Parry, following the conclusion of my original postdoctoral research contract at the University of Adelaide. That period of work was complex in many respects but being part of the team at the Australian Centre for Ancient DNA (ACAD) was a truly rewarding experience.
REFERENCES
The dataset was the final output of a postdoctoral project with ACAD, focused on the chronology of megafauna species, and resulted in four publications:
-
Expert-guided review of collagen pretreatment methods for radiocarbon dating
Herrando-Pérez S 2021. Bone need not remain an elephant in the room for radiocarbon dating. Royal Society Open Science 8(1):201351. https://doi.org/10.1098/rsos.201351 -
CRIWM: method for estimating extinction time that accounts for calibration uncertainty in time series of radiocarbon ages
Herrando-Pérez S, Saltré F 2024. Estimating extinction time using radiocarbon dates. Quaternary Geochronology 79:101489. https://doi.org/10.1016/j.quageo.2023.101489 -
Improving the standards for reporting radiocarbon data – a companion paper detailing the challenges involved in compiling MEGA14C
Herrando-Pérez S, Stafford Jr TW 2025. Making vertebrate fossil radiocarbon dates more useful for global scientific research. Journal of Quaternary Science 40(8):1309-1335. https://doi.org/10.1002/jqs.70012 -
Introducing MEGA14C to the scientific community
Herrando-Pérez S et al 2026. A database of radiocarbon dates from Holarctic mammal collagen purified with high-quality chemistry. Scientific Data 13:556. https://doi.org/10.1038/s41597-026-06562-3 / https://doi.org/10.6084/m9.figshare.27826200 -
MEGA14C: pretreatment-curated dataset of radiocarbon ages
Herrando-Pérez S 2026. MEGA14C: a dataset of radiocarbon dates from Holarctic mammal collagen purified with high-quality chemistry. Figshare 03 March 2026 https://doi.org/10.6084/m9.figshare.27826200
|
Research: I am a quantitative ecologist focused on the curation and analysis of biodiversity data. My work spans taxa and habitats and bridges contemporary ecology with deep-time perspectives, with a growing emphasis on palaeoecology. My core strength is careful, methodical work that improves the quality, consistency and reliability of biological data resources. I aim to improve the accuracy of Quaternary megafaunal chronologies using radiocarbon dating of fossil collagen.
Outputs: I have published 37 peer-reviewed scientific papers (20 as first author), lectured 15 postgraduate courses on multivariate statistics, developed two statistical R packages, and described four species new to science. Since 2011, I have actively engaged in science communication, producing more than 100 printed articles and blogs, contributing to knowledge dissemination across academic and public audiences.
Training: My career has been built through a BSc in Biology/Zoology (1991), an MPhil in marine ecology (1992-1996) and a PhD in population dynamics (2007-2012), with postdoctoral work spanning ecophysiology (2013-2015), palaeoecology (2012-2013, 2018-2020, 2021-present), ecological monitoring (2021-2022) and fire ecology (2022-2023). Throughout, I experienced nine years of career interruptions, primarily due to parenting responsibilities, while maintaining research engagement, productivity and resilience. --- Currently, I serve as Science Manager in Miguel B. Araújo's research group and continue my research in palaeoecology, at the National Museum of Natural Sciences in Madrid, Spain. |
Follow the Topic
-
Scientific Data
A peer-reviewed, open-access journal for descriptions of datasets, and research that advances the sharing and reuse of scientific data.

Related Collections
With Collections, you can get published faster and increase your visibility.
Computer vision in plant science and agriculture
Publishing Model: Open Access
Deadline: Oct 10, 2026
Wearable and Computer Vision Data for Health and Behaviour Research
Publishing Model: Open Access
Deadline: Aug 08, 2026

Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in