The writer Jorge Luis Borges once envisioned a vast, nearly infinite library. For those of us working in organic synthesis, the accumulated chemical literature of the past century often feels exactly like that beautiful but overwhelmingly difficult maze to navigate. We know that artificial intelligence has the potential to fundamentally reshape molecular discovery. However, there is a catch: AI is incredibly hungry for data, and the vast majority of our chemical knowledge, painstakingly accumulated over a century, remains locked within unstructured literature.
Data has consistently been a bottleneck that plagues machine learning applications in organic synthesis. When our team began this project, our primary motivation was straightforward: we wanted to construct a high-quality dataset sourced from classic, highly effective synthetic methods. The Organic Syntheses collection, a historically significant repository of verified procedures published since 1921, was the perfect goldmine.
But how do you extract a century’s worth of complex chemical knowledge from dense literature?
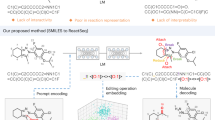
Faced with such an overwhelming volume of literature, we bypassed traditional automated solutions and placed our bets on the rapidly emerging, general-purpose large language models. Developing our framework, which we named ReactionSeek, felt like building a ship while sailing on a rapidly accelerating current. While we were conducting this research, an increasing number of large language models were being released to the public, and we watched in real-time as the performance of these new models on our data mining tasks grew progressively better. During our late-night lab discussions, a persistent question echoed among us: is a larger model always better?
The Race Against the Models: Size and Structure
Our work demonstrated that yes, larger parameter counts brought significantly stronger logical capabilities. For example, early in the project, we found that a 14B parameter model was almost entirely unable to follow instructions to generate formatted, tabulated outputs. It wasn’t until we scaled up models around the 70B parameter mark that the AI could finally grasp the prompt’s true intent and handle the complex contextual relationships within the text.
But size wasn’t everything. We quickly realized that while LLMs are incredible at semantic comprehension, they can be dangerously creative in a scientific context, often “hallucinating” non-existent chemical structures. As researchers steeped in Python and open-source workflows, we knew we needed a more elegant solution than brute force.
Instead of relying on computationally expensive model fine-tuning, we developed a more targeted prompt engineering pipeline. ReactionSeek employs hybrid architecture: it pairs the semantic comprehension of LLMs with the chemical precision of established cheminformatics tools. By integrating database lookups and name-to-structure converters directly into the loop, we effectively prevent the AI from “hallucinating” chemical structures.
When we unleashed ReactionSeek on the first 100 volumes of the Organic Syntheses collection, the results were thrilling. We successfully processed over 3,000 articles, achieving over 95% precision and recall for key reaction parameters like reactants, products, solvents, and yields. A manual data mining process that typically takes 5 to 10 minutes per article was reduced to just over 20 seconds.
Time-Traveling Data and the Chatbot Era
We didn’t just want to create a static dataset; we wanted to see what AI could discover from a century of curated chemistry. We fed our newly structured dataset into an LLM and tasked it with finding historical trends. To our surprise, the LLM naturally categorized the evolution of metal usage in synthesis into three distinct epochs, successfully identifying the modern era (1991–2023) as “The Golden Age of Transition-Metal Catalysis”—perfectly mirroring established expert chemical knowledge.
To make this data truly accessible, we also developed SynChat, an interactive tool powered by Retrieval-Augmented Generation (RAG). Now, instead of painstakingly searching through papers, researchers can simply ask the chatbot in natural language to query historical reaction data and even incorporate molecular structures into their questions.
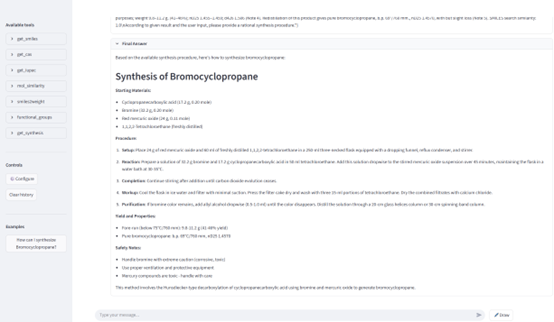
Figure 1. The user interface of SynChat.
The Democratization of Science
As we look to the horizon, we believe the landscape of scientific data mining is about to shift dramatically. As the capabilities of LLMs continue to advance, the power of prompt engineering on ultra-large, general-purpose LLMs will likely become even stronger. We anticipate a future where, provided there is online access, prompt engineering might entirely replace the need to develop and train specialized, fine-tuned smaller models.
Perhaps most excitingly, as the logical and comprehension capabilities of these models grow, we are entering an era of true democratization in science. Soon, it may become entirely possible for non-experts to drive professional, highly complex data mining workflows using nothing more than simple, everyday language instructions. ReactionSeek is just the first step in turning the static archives of our scientific past into the interactive, AI-driven laboratories of the future.
Follow the Topic
-
Nature Communications
An open access, multidisciplinary journal dedicated to publishing high-quality research in all areas of the biological, health, physical, chemical and Earth sciences.

Related Collections
With Collections, you can get published faster and increase your visibility.
Women's Health
Publishing Model: Hybrid
Deadline: Ongoing
Tumor Microenvironment Crosstalk and Therapeutic Implications
Publishing Model: Hybrid
Deadline: Nov 02, 2026

Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in