The Generalization Crisis: Are Chemical AI Models Learning Science, or Just Memorizing Beaker Metrics?
Published in Chemistry, Materials, and Computational Sciences
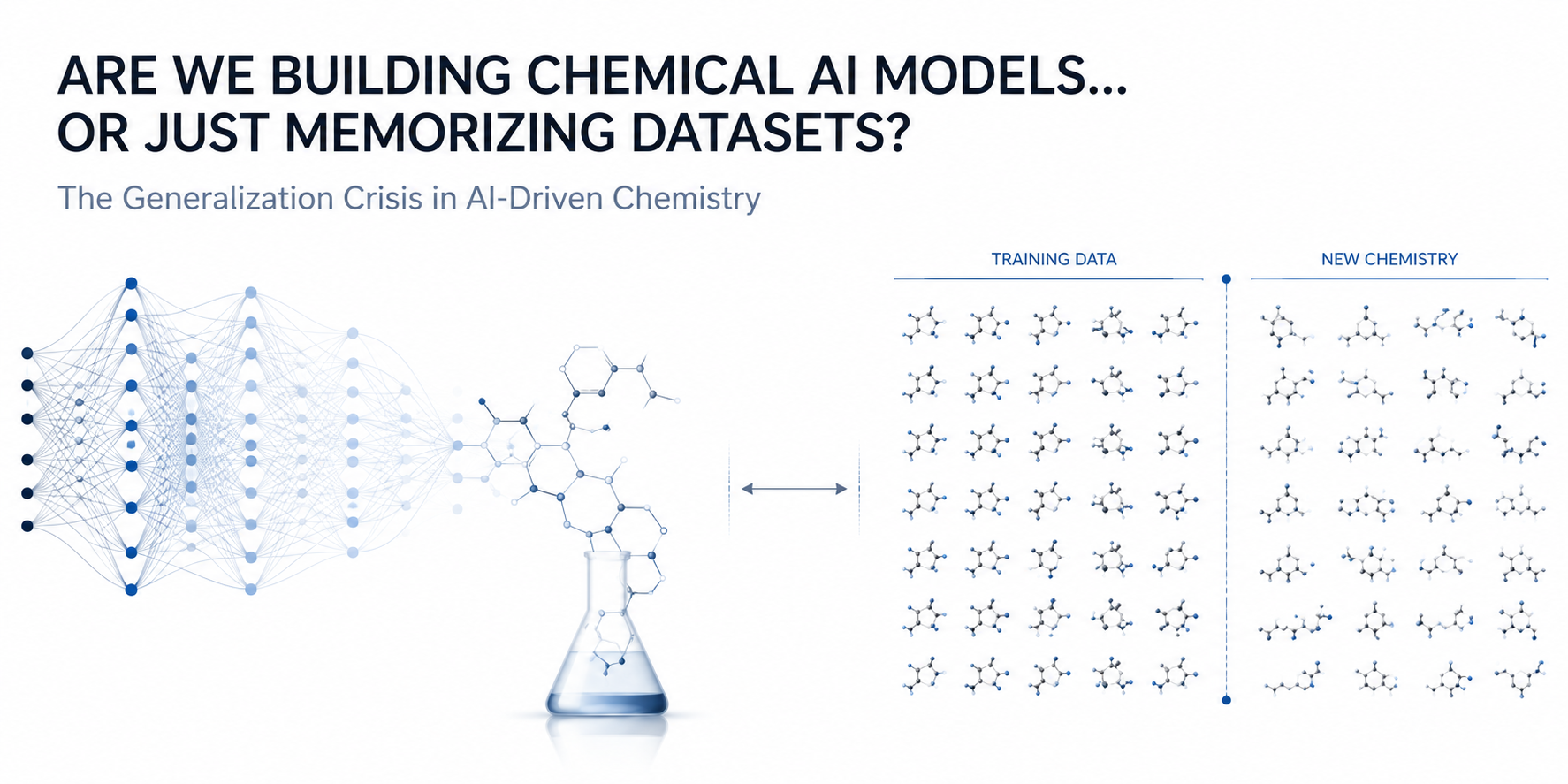
The Illusion of Predictive Accuracy
Artificial intelligence is rapidly becoming a cornerstone of modern chemistry. From predicting advanced oxidation pathways to screening metal-organic framework (MOF) topologies and optimizing electrochemical sensors, machine learning models are delivering increasingly impressive benchmark results.
Yet an uncomfortable question remains: How many of these models truly generalize beyond the data they were trained on?
In many published studies, AI systems demonstrate remarkable predictive accuracy on held-out test datasets. However, when these models are confronted with genuinely new chemical spaces, different experimental conditions, or data generated by an independent laboratory, their performance declines substantially.
This is the field's growing generalization crisis. A model that successfully interpolates within a familiar, tightly bounded dataset is not necessarily capable of scientific discovery. In chemistry, the ultimate objective is not to reproduce patterns that already exist in historical data—it is to generate reliable insight under conditions that have never been observed before.
The Dataset Traps: Why Models Cheat
The core of the problem lies in the fact that machine learning algorithms are incredibly efficient cheaters. They optimize for the easiest path to minimize error. Instead of learning underlying chemical principles, they often learn dataset-specific correlations and experimental artifacts.
Chemical datasets are notoriously plagued by five major bottlenecks:
-
Limited Diversity: Over-sampling popular, easily synthesized chemical structures while leaving massive regions of chemical space empty.
-
Experimental Bias: Data reflecting the specific habits, purities, and ambient conditions of a few select labs.
-
The Negative Results Vacuum: A systemic publication bias where failed reactions or inactive catalysts are rarely reported, leaving models blind to the boundaries of success.
-
Laboratory-Specific Protocols: Equipment-dependent quirks (e.g., specific stirring rates, heating profiles, or sensor baselines) that mask themselves as real chemical variables.
-
Extreme Data Imbalance: Highly skewed data distributions that trick models into guessing the majority class to achieve a falsely high accuracy metric.
When an AI model is trained on this skewed landscape, it maps the data's flaws rather than its science. It doesn't learn chemistry; it learns the dataset.
The "Black Box" vs. Quantum Realism
To break out of this memorization trap, the chemical AI community must move away from purely statistical "black-box" models. The next major breakthrough in Chemical AI will not come from building larger neural networks or throwing more brute-force computational power at low-quality data.
The future belongs to hybrid, physics-informed machine learning architectures. We must design models that tightly integrate machine learning with the immutable laws of physics and physical chemistry. Training models on hybrid frameworks—where deep learning is bounded by explicit Density Functional Theory (DFT) descriptors, thermodynamic conservation laws, and supramolecular interaction constraints—forces the AI to respect chemical reality.
If a model understands the fundamental physics of an interaction (like the Hard-Soft Acid-Base principle or electronic heterojunction alignment), it can robustly transfer its predictive power across completely different laboratories, instruments, and chemical families.
From Publication Aesthetics to Scalable Reality
This issue is a foundational problem for scientific progress. Failure to generalize in computer vision might mean a mislabeled image; failure to generalize in chemistry leads to wasted laboratory resources, dangerous toxicological misassignments, and delayed commercialization of clean technologies.
We need to shift our academic reward system. Instead of celebrating incremental accuracy gains on static, hyper-specific benchmarks, we should value out-of-distribution robustness, inter-laboratory transferability, and physical interpretability.
Conclusion
Artificial intelligence represents an extraordinary tool for accelerating materials and environmental engineering. But if our architectures are merely memorizing historical data patterns, we are optimizing for publication aesthetics rather than real-world utility.
The true metric of a chemical AI model is not its performance on a held-out slice of its own training set. It is its capacity to maintain mechanistic integrity when the environment becomes unfamiliar and the data gets messy.
What do you believe is currently the single greatest obstacle to generalizable AI in chemistry—the lack of open-access negative results data, the absence of standardized inter-laboratory benchmarks, or our over-reliance on purely statistical model architectures?
#ChemicalAI #MachineLearning #Chemistry #DataScience #MaterialsDiscovery #DFT #PhysicsInformedAI #ResearchCommunities #DigitalChemistry
Dr. Akeem Adeyemi Oladipo is a globally recognized Research Professor of Materials and Environmental Chemistry at Eastern Mediterranean University. Ranked among the world's Top 2% Scientists, his expertise bridges nanotechnology, renewable energy, and electro-analytical chemistry. He specializes in advanced materials synthesis for wastewater treatment, highly sensitive electrochemical biosensors, and solar energy conversion. By integrating machine learning and artificial neural networks, his research drives scalable deep-tech innovations in environmental sustainability and energy storage.




Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in