A global patent dataset of bioeconomy-related inventions
Published in Social Sciences, Earth & Environment, and Sustainability
Explore the Research

A global patent dataset of bioeconomy-related inventions - Scientific Data
Scientific Data - A global patent dataset of bioeconomy-related inventions
The challenge of identifying bioeconomy-related patents
The bioeconomy offers transformative solutions to global challenges such as climate change, resource depletion, and environmental degradation. The transition to a bio-based economy, however, requires the development and diffusion of (technological) innovations. Tracking innovation in the bioeconomy is challenging due to its multidimensional and cross-sectoral nature. To address this problem, we developed a comprehensive dataset of patents related to the bioeconomy, leveraging artificial intelligence (AI). Patents are a common indicator for knowledge development and innovation. Traditional methods for identifying bioeconomy-related patents have significant limitations. Static technology classifications and keyword searches in patent abstracts, while widely used, are prone to inaccuracies. For instance, bio-based innovations may be misclassified under unrelated categories or overlooked entirely due to variations in terminology across languages and disciplines. These shortcomings in traditional methodologies highlighted the need for a more adaptable and dynamic approach to accurately reflect the evolving nature of the bioeconomy.
Leveraging AI for tracking the bioeconomy in patent data
To overcome these challenges, we fine-tuned a pre-trained large language model (LLM) using manually annotated patent abstracts. This model was designed to identify bio-based products, services, and processes with greater accuracy and comprehensiveness. We analyzed a dataset of 67 million patents and successfully identified 5.6 million as bioeconomy-related. This approach transcended the limitations of traditional methods by accommodating linguistic and contextual variations in patent descriptions.
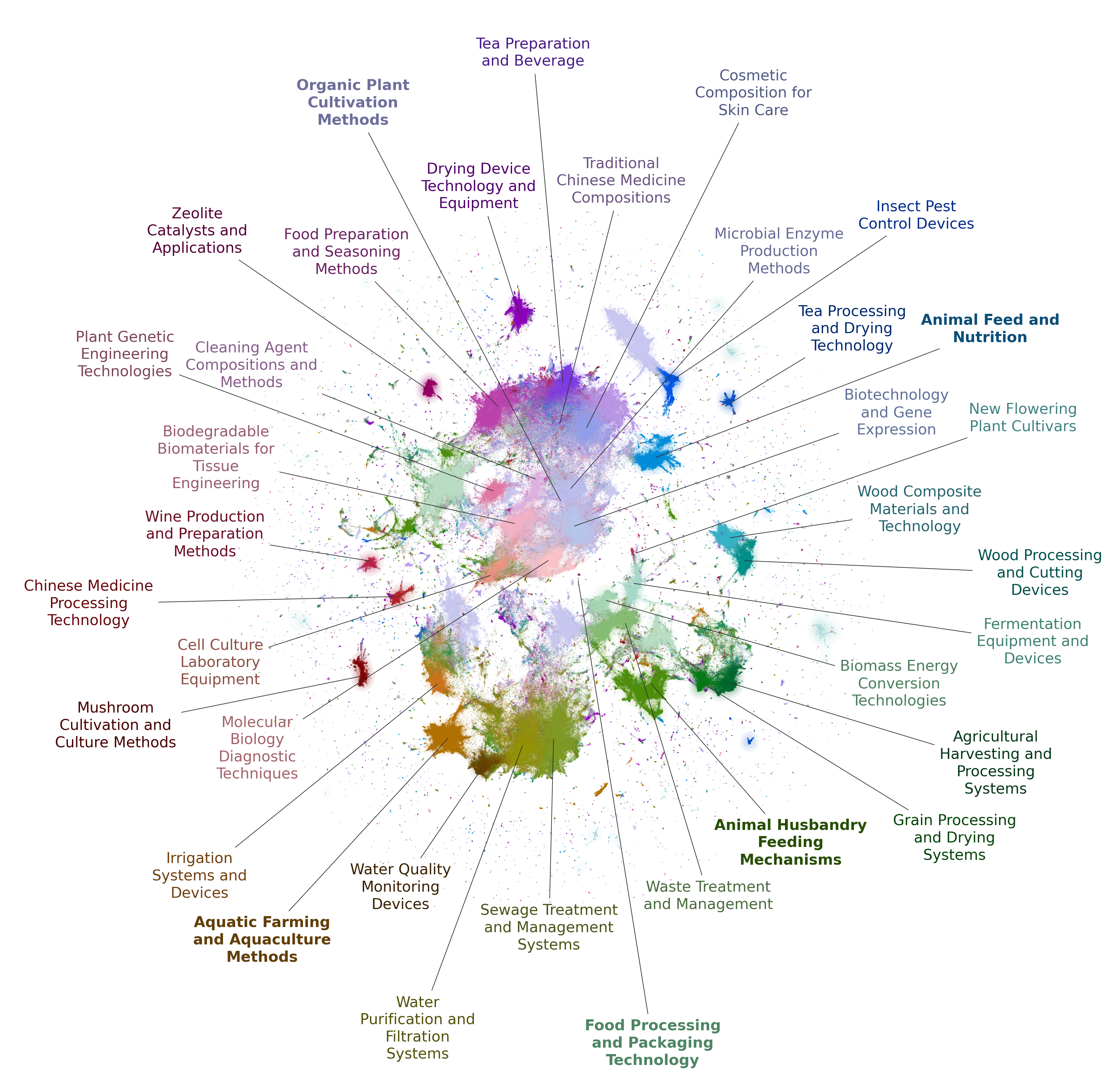
Mapping bioeconomy-related inventions
To map innovation within the bioeconomy, we applied topic modeling, a technique that groups text data into thematic clusters. This analysis revealed key areas of innovation, including organic farming, water purification techniques, fermentation methods, biodegradable materials or sustainable feed solutions. These themes were visualized through a detailed map of bioeconomy advancements, showcasing thematic clusters and their interconnections. This visualization enables researchers and policymakers to explore inventions in the bioeconomy and identify underexplored opportunities.
Lessons learned: Harnessing AI for innovation research
This project showcased the immense potential of AI models, particularly large language models (LLMs), in extracting meaningful information from unstructured data like patent abstracts. By overcoming the constraints of static classifications and keyword-based methods, fine-tuned LLMs provided a more nuanced and comprehensive view of innovation patterns in the bioeconomy. We encourage fellow researchers to explore these new techniques, in particular in economics and the social sciences.
Implications for policy and research
Our dataset opens new possibilities for policymakers and researchers: Policymakers can use these insights to design targeted strategies that foster bio-based innovation. For example, identifying regions or industries with high innovation potential can inform funding priorities and regulatory support. Moreover, the dataset provides a foundation for exploring trends in bioeconomy innovations, assessing the impact of policies, and understanding the evolution of innovation systems.
Follow the Topic
-
Scientific Data
A peer-reviewed, open-access journal for descriptions of datasets, and research that advances the sharing and reuse of scientific data.

Related Collections
With Collections, you can get published faster and increase your visibility.
Computer vision in plant science and agriculture
Publishing Model: Open Access
Deadline: Oct 10, 2026
Wearable and Computer Vision Data for Health and Behaviour Research
Publishing Model: Open Access
Deadline: Aug 08, 2026


Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in