A survey of classification tasks and approaches for legal contracts
Published in Computational Sciences

Legal contracts are everywhere: when renting an apartment, getting a job, or signing up for a service, people agree to complex legal agreements. These contracts contain many pages with important clauses that are often hidden by legal jargon. As automation in the legal field continues to expand, the need for efficient contract analysis becomes important for legal practitioners, AI researchers, and laypeople who want to understand these agreements. This is the focus of the survey, A survey of classification tasks and approaches for legal contracts.
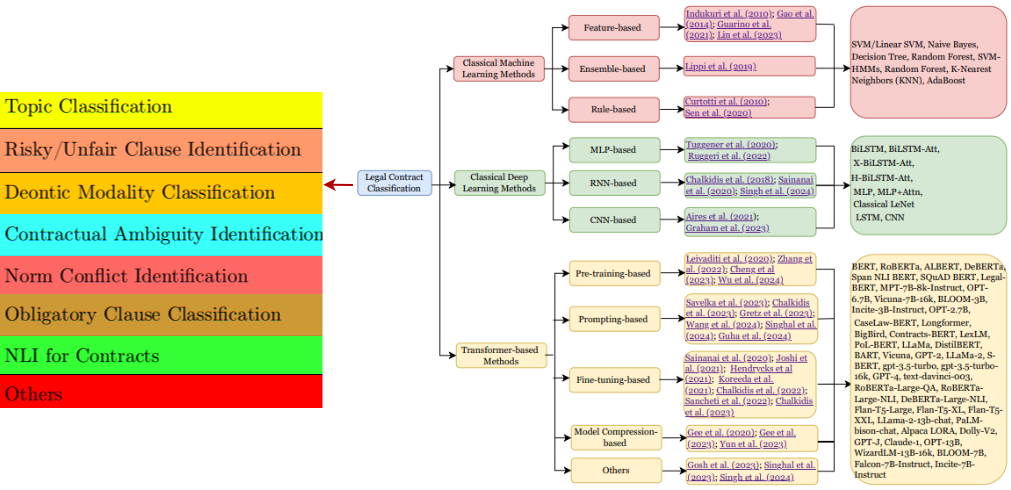
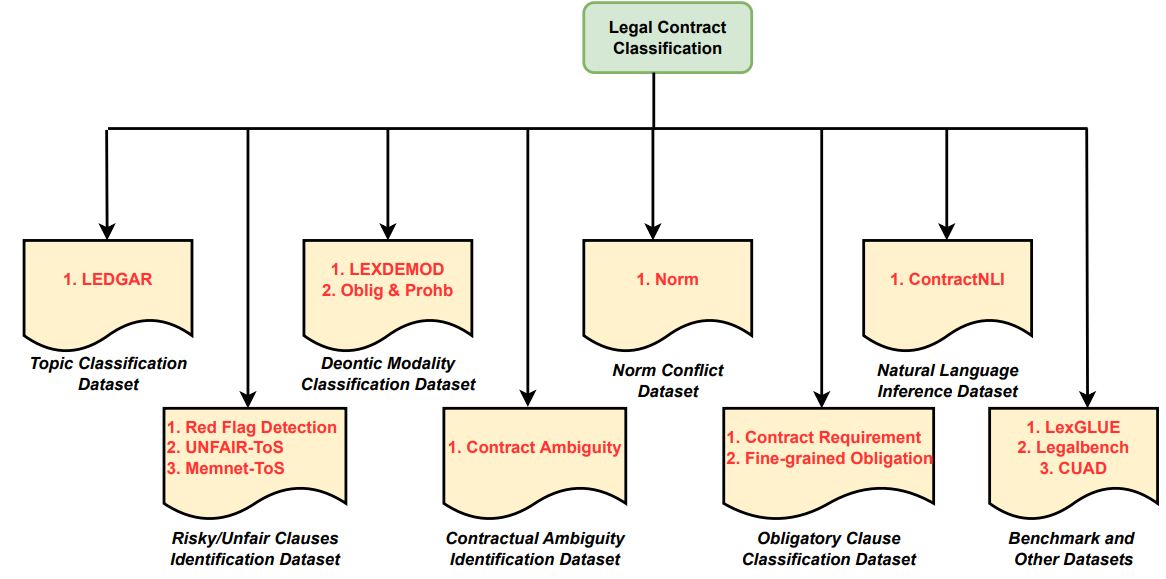
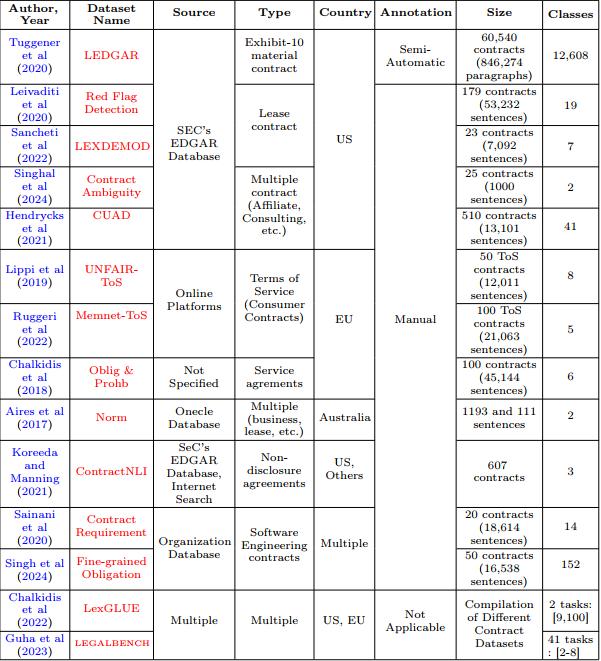
The survey outlines 7 key tasks within legal contract classification (LCC), ranging from classifying the topic of a clause or provision, identifying risky or unfair clauses, to classifying ambiguous clauses, among others. It also reviews 14 LCC datasets organized according to these seven task categories, including eleven publicly available, one non-public, and two proprietary datasets. The survey discusses 8 challenges related to LCC datasets: the lack of a standard benchmark dataset, geographic and jurisdictional imbalance in labeled datasets, lack of transparent annotation, issues in dataset design, quality, and bias, challenges in pre-processing legal contracts, restrictions on multi-task learning and task diversity, challenges with small-sized publicly available datasets, and difficulties with proprietary datasets. It also discusses potential avenues for future advancements to overcome these challenges.
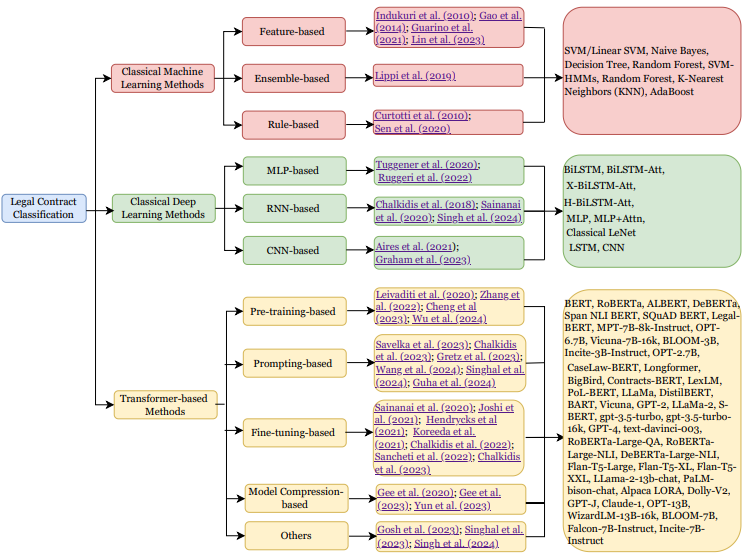
To automate and address these tasks effectively, the survey introduces a methodology-based taxonomy, categorizing the various approaches into three main groups: Classical Machine Learning, Classical Deep Learning, and Transformer-based methods.
The survey highlights 10 key challenges and future directions in LCC methods, such as issues with prompting strategies, class imbalance, model evaluation, failure handling, ethical and privacy concerns, explainability, multilingual classification, and small language models. This comprehensive review aims to provide researchers with insights into current advanced techniques and valuable guidance for newcomers to the field. For more details, refer to the full survey paper at https://link.springer.com/article/10.1007/s10462-025-11359-8.
Follow the Topic
-
Artificial Intelligence Review
Artificial Intelligence Review is a fully open-access journal publishing cutting-edge AI and cognitive science research. It features evaluation of applications and algorithms, offers a platform for researchers and developers, and presents surveys, tutorials and commentary on key developments.




Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in