Behind the Research: Optimizing Real-Time Thermal Imaging for Agricultural Automation
Published in Computational Sciences

.png)
A deep dive into benchmarking lightweight YOLO architectures for okra maturity detection
Introduction
Agricultural automation faces a critical challenge: how can we develop inspection systems that are both highly accurate and fast enough for real-time processing? In our recent study published in The Journal of Supercomputing, my colleagues and I addressed this question by systematically benchmarking four state-of-the-art YOLO nano-variant object detection models for thermal imaging applications in okra maturity grading.
Why Thermal Imaging Matters
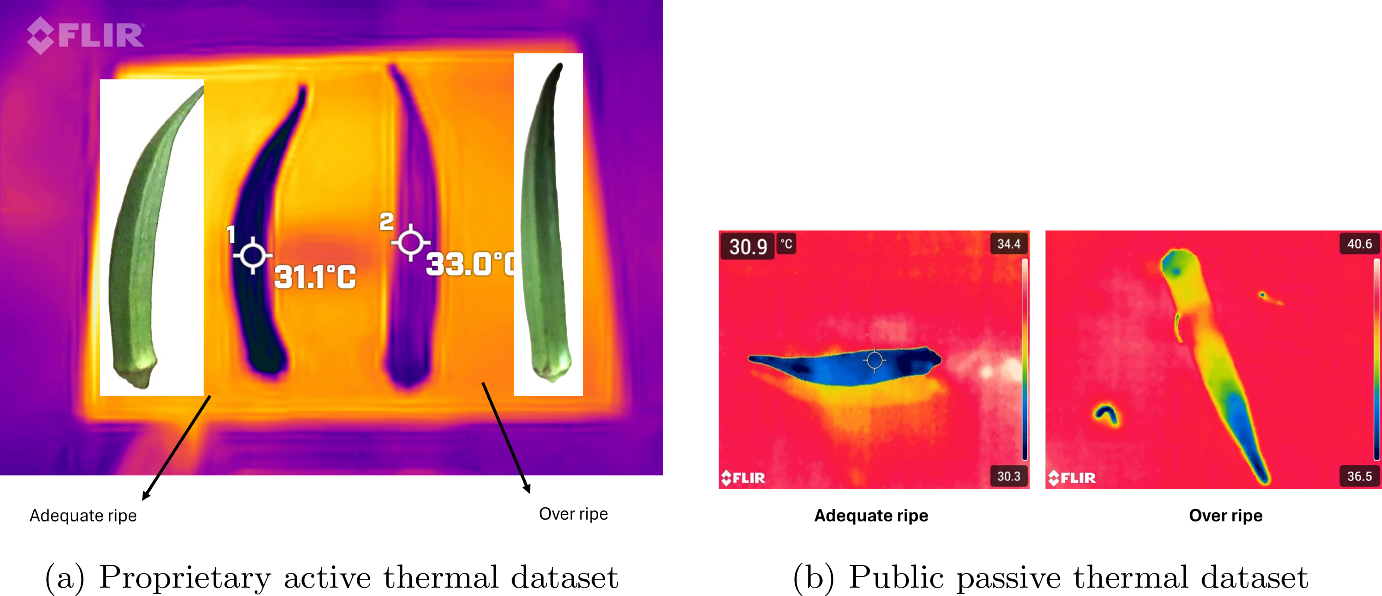
Traditional RGB-based inspection systems struggle under variable lighting conditions—a common reality in agricultural settings ranging from night harvesting to indoor packing facilities. Thermal imaging offers a compelling alternative by capturing temperature-dependent information that remains consistent regardless of ambient lighting. For okra specifically, thermal signatures reveal physiological differences in moisture content and thermal mass between maturity stages, providing a robust basis for automated quality assessment.
However, thermal imagery presents unique computational challenges. Single-channel intensity data, reduced texture information, and temperature-dependent contrast require specialized architectural considerations that haven't been systematically evaluated in prior research.
The Research Gap
While YOLO (You Only Look Once) architectures have been extensively benchmarked on RGB datasets such as COCO and ImageNet, comprehensive evaluation on thermal agricultural imagery remained absent from the literature. This gap is particularly significant because:
- Architectural innovations designed for RGB may not transfer effectively to thermal domains
- Real-time industrial sorting requires sub-50 millisecond inference latency
- Deployment on heterogeneous computing platforms (GPU vs. CPU) demands quantitative performance analysis
Our study addresses these gaps by evaluating YOLOv5n, YOLOv8n, YOLOv11n, and YOLOv12n across multiple performance dimensions.
Methodology Highlights
We developed a dual-source thermal dataset combining passive and active thermal imaging modalities. The active thermal approach—involving controlled preheating to 30°C—proved particularly important. Natural thermal contrast between adequately matured and overripe okra averages only 2.8°C under ambient conditions, which can be insufficient under variable environments. Controlled preheating amplifies this contrast to 4–8°C by exploiting maturity-dependent differences in thermal mass and cooling behavior.
Our experimental design incorporated rigorous statistical validation across five independent training runs, ensuring reproducibility and significance testing of observed performance differences. This methodological rigor is essential for drawing reliable conclusions in machine learning research.
Key Findings
Training Duration Dependency
One of our most significant findings relates to training efficiency. Under the resource-efficient 10-epoch protocol—reflecting rapid development scenarios—YOLOv8n achieved the highest detection accuracy (66.3% mAP@0.5–0.95), while YOLOv5n delivered comparable performance (66.1%) with superior computational efficiency.
However, extended training experiments revealed a critical insight: attention-based architectures (YOLOv11n and YOLOv12n) achieve higher peak accuracy (73.1% and 72.9% respectively) when training budgets permit 45–67 epochs. This performance ranking inversion suggests that architectural complexity translates to gains only with sufficient training iterations—a crucial consideration for practical deployment.
Platform-Specific Performance
Our benchmarking across heterogeneous computing platforms revealed distinct trade-offs:
- GPU deployment (NVIDIA T4 with TensorRT): YOLOv8n achieved 1.6 ms inference latency, supporting throughput exceeding 625 FPS—well above the ≥20 FPS requirement for real-time sorting
- CPU deployment (ONNX Runtime): YOLOv5n exhibited superior performance at 31.1 ms, making it optimal for edge and embedded scenarios
These findings provide practical guidance for selecting architectures based on deployment constraints.
Architectural Insights
Through gradient-weighted class activation mapping (Grad-CAM) analysis, we discovered that decoupled detection heads enable task-specific feature specialization. Classification branches focus selectively on thermal intensity gradients, while localization branches emphasize geometric boundaries—a design principle particularly beneficial for thermal imagery where diagnostic features are spatially distinct.
Ablation studies confirmed that mosaic augmentation improved detection performance by 6.2% without additional latency, while balanced loss weighting outperformed imbalanced configurations in this binary classification task.
Practical Implications
Our research demonstrates that thermal-based YOLO nano-variants are ready for integration into automated sorting pipelines, achieving 75 kg/min throughput with <2% background false positives. The system operates at sustained rates exceeding industrial requirements while maintaining high detection accuracy.
For practitioners, the key takeaway is this: model selection must jointly consider deployment constraints (inference latency, memory footprint) and available training resources (time budget, computational capacity). Simple architectures like YOLOv5n and YOLOv8n excel in rapid-iteration scenarios, while attention-based variants justify their complexity only when extended training is feasible.
Future Directions
Several promising research directions emerge from this work:
- Dataset expansion across cultivars, seasons, and environmental conditions to enhance model robustness
- Multi-class grading spanning the full maturity spectrum
- Multispectral fusion combining thermal and RGB modalities
- Knowledge distillation from transformer-based teachers to lightweight students
- Field deployment trials in commercial facilities for long-term validation
Conclusion
This systematic benchmark establishes quantitative baselines for thermal agricultural imaging and provides practical guidance for architecture selection. The identified strategies—anchor-free detection, decoupled heads, mosaic augmentation, and balanced loss weighting—are transferable to other crops and sensing modalities, offering strong potential for advancing automated agricultural inspection systems.
Article Citation: Ganapathy, M.R., Pugazhendi, P., Periasamy, S., Nagarajan, B. (2026). Benchmarking YOLO nano-architectures for real-time thermal imaging: application to okra maturity grading on heterogeneous computing platforms. The Journal of Supercomputing, 82:97. https://doi.org/10.1007/s11227-026-08226-w
Data Availability: The public thermal dataset is available at Mendeley Data. Code is available at the project GitHub repository.
I'm Dr. Pathmanaban Pugazhendi, an Assistant Professor at Easwari Engineering College, where I combine my passion for Computer Vision, Thermal Imaging, Deep Learning, and Edge AI to solve real-world problems in agriculture, food safety, and sustainable technology.
My Research Journey
My work has been cited over 410 times across various international journals, with a Total Author Impact Factor of 62.20. What drives me is the opportunity to bridge the gap between cutting-edge AI research and practical applications that make a tangible difference.
In Agricultural Technology & Food Science:
- I develop AI-powered systems for precision agriculture, helping farmers detect diseases and defects in crops like guava, sugarcane, and sapota
- I use thermal imaging to assess fruit quality post-harvest, reducing food waste and improving safety
- My recent work includes uncertainty-aware deep learning models that make agricultural AI more reliable and trustworthy
In Sustainable Engineering:
- I apply machine learning to optimize engine performance using alternative fuels like biodiesel and ethanol-water blends
- I'm working on intelligent battery management systems for electric vehicles
- My research explores how AI can accelerate our transition to renewable energy
In Computer Vision & AI:
- I specialize in developing lightweight deep learning models (like YOLO architectures) that can run on edge devices
- I'm particularly interested in making AI accessible for resource-constrained environments—bringing powerful technology to where it's needed most, not just where computational resources are abundant
What Drives My Work
I believe AI should be practical, deployable, and accessible. That's why much of my research focuses on developing efficient models that work in real-world conditions—whether it's detecting bread contamination using thermal imaging, identifying weld defects in manufacturing, or helping farmers spot crop diseases early.
My work has been published in top-tier Q1 journals including Journal of Food Engineering (IF: 5.8), Scientific Reports (IF: 3.9), and Trends in Food Science & Technology (IF: 15.4), but what matters most to me is seeing these technologies actually being used to solve problems.
Looking Forward
I'm currently focused on advancing Edge AI technologies—developing intelligent systems that can make split-second decisions without needing constant cloud connectivity. From smart farming tools to industrial quality control systems, I'm excited about building AI that works anywhere, for anyone.
I'm always open to collaborations, discussions, and connecting with fellow researchers, students, and industry professionals who share a passion for applied AI and sustainable technology.
Follow the Topic
-
The Journal of Supercomputing
The Journal of Supercomputing publishes papers on the technology, architecture and systems, algorithms, languages and programs, performance measures and methods, and applications of all aspects of supercomputing.

Related Collections
With Collections, you can get published faster and increase your visibility.
Section - Architectures, Systems and Hardware Security
All aspects of high-performance hardware and architectures, including optimizing and evaluating processors, systems issues, and security, especially at the hardware level and sustainability of systems.
Topics include but not limited to the following:
T
• Architectural support for programming languages or software development.
• Architectures to support extremely heterogeneous composable systems (e.g., chiplets)
• Design-space exploration/performance projection for future systems
• Evaluation and measurement on testbed or production hardware systems
• Hardware acceleration of containerization and virtualization mechanisms for HPC
• Interconnect technologies, topology, switch architecture
• I/O architecture/hardware and emerging storage technologies
• Memory systems: caches, memory technology, non-volatile memory, memory system architecture (to include address translation for cores and accelerators)
• Multi-processor architecture and micro-architecture (e.g., reconfigurable, vector, stream, dataflow, GPUs, and custom/novel architecture)
• Sustainable design aspects, including power and energy efficiency and power-management strategies
• Resilience, error correction, high availability architectures
• Scalable and composable coherence (for cores and accelerators)
• Secure architectures, side-channel attacks, and mitigation, covering all attack vectors, including all forms of side-channel attacks, piracy, reverse engineering, tampering, and hardware Trojan attacks, including countermeasures at different stages of system design - i.e., architecture definition, design, validation, and deployment
• The security of hardware and system security at all levels of abstraction
• Interactions between hardware and systems, and between hardware and firmware/software, including in the context of security and trust
• Software/hardware co-design, domain-specific language support
• Interactions among architectures, compilers, programming languages, and operating systems
Architectures, Systems and Hardware Security research relates to multiple United Nations Sustainable Development Goals (SDGs) through advances in health care, education, and energy, among other fields. This Section particularly welcomes submissions related to SDG 9 “Industry, Innovation, And Infrastructure.”
An essential aspect of supercomputing involves solving computer-intensive problems. Paper submissions are expected to address problems that require significant computational resources.
Publishing Model: Hybrid
Deadline: Ongoing
Section - Advanced Embedded Systems
The Journal of Supercomputing announces a new section dedicated to Advanced Embedded Systems, bringing together embedded hardware, novel embedded software solutions, and advancements related to solving critical issues in embedded security, energy efficiency, or emerging applications. We aim to foster collaboration among researchers spanning various domains, facilitating the exchange of original research findings and practical insights relevant to the expansive realm of embedded systems.
Topics of interest include, but are not restricted to:
Embedded Hardware Design:
• Microcontroller and microprocessor architectures
• FPGA design
• High-performance embedded computing
• Power-efficient hardware design
• Hardware security and trustworthiness
Embedded Software Development:
• Real-time operating systems (RTOS)
• Embedded software development tools and methodologies
• Firmware development and debugging
• Middleware and communication protocols for embedded systems
• Embedded software testing and verification
IoT and Wireless Embedded Systems:
• Internet of Things (IoT) applications and technologies
• Wireless sensor networks
• Low-power communication protocols (e.g., LoRa, Zigbee, NB-IoT)
• Edge computing in IoT
• Security and privacy in IoT and wireless embedded systems
Embedded System Security:
• Hardware and software security mechanisms
• Secure boot and firmware update
• Intrusion detection and prevention in embedded systems
• Secure communication and encryption
• Vulnerability assessment and mitigation
Embedded Systems in Autonomous Vehicles:
• Autonomous vehicle control systems
• Perception and sensor fusion for autonomous vehicles
• V2X communication and vehicle-to-vehicle (V2V) communication
• Safety-critical embedded systems in automotive applications
• Regulatory and safety standards in automotive embedded systems
Medical Embedded Systems:
• Medical device design and development
• Wearable health monitoring systems
• Telemedicine and remote patient monitoring
• Regulatory compliance and safety in medical embedded systems
• Healthcare data security and privacy
Energy-efficient Embedded Systems:
• Energy harvesting for embedded systems
• Battery management and energy optimization
• Green computing and sustainability in embedded systems
• Energy-efficient algorithms and hardware design
Embedded Systems for Space and Aerospace:
• Spacecraft onboard computers
• Satellite control systems
• Avionics and flight control systems
• Radiation-hardened electronics
• Space communication protocols
AI and Machine Learning in Embedded Systems:
• Edge AI and inference on embedded devices
• Deep learning accelerators for embedded systems
• Machine learning for embedded vision and audio processing
• AI-driven autonomous systems
• Ethical considerations in AI-enabled embedded systems
Trends and Emerging Technologies:
• Emerging hardware platforms (e.g., neuromorphic computing)
• Quantum computing and its potential impact on embedded systems
Advanced Embedded Systems research relates to multiple United Nations Sustainable Development Goals (SDGs) through advances in health care, education, and energy, among other fields. This Section particularly welcomes submissions related to SDG 9 “Industry, Innovation, And Infrastructure.”
An essential aspect of supercomputing involves solving computer-intensive problems. Paper submissions are expected to address problems that require significant computational resources.
Publishing Model: Hybrid
Deadline: Ongoing


Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in