Benchmark data for machine learning in ecotoxicology
Published in Research Data
Explore the Research

A benchmark dataset for machine learning in ecotoxicology - Scientific Data
Scientific Data - A benchmark dataset for machine learning in ecotoxicology
Machine learning for ecotoxicology
High hopes are put into the use of machine learning (ML) and artificial intelligence (AI) for different kinds of research - from image recognition for early-stage cancer growth and plankton species to prediction of groundwater levels. This is not different for predicting (eco)toxicology (Hartung 2023; Hartung and Tsatsakis 2021).
However, like any other, ML-based research depends on best practices and transparent reporting. Many fields that employ ML for their use-cases seem to individually adopt such best practices with varying speeds and levels of success. In ecotoxicological hazard assessment (testing how toxic a certain chemical is to a specific species), modeling has a long history in the form of quantitative structure-activity relationship (QSAR) models, that predict biological activity (including toxicity) from chemical properties and structures (Muratov et al. 2020). The strength of machine learning lies in finding patterns in large datasets and using those patterns to make predictions on unknown feature combinations. For this, it can integrate different kinds of data and, unlike QSARs, is not limited to only data on the chemicals.
Comparability equals progress
The process of compiling data to explore the potential and limitations of applying machine learning to ecotoxicology (the science of what chemicals do to organisms and what organisms do to chemicals) requires significant understanding of both biology and machine learning. This is something that not everyone in the field, or intending to venture into the field, possesses. This can present a barrier of entry for people willing to apply their machine learning expertise to ecotoxicological problems. Meanwhile, the field needs more attention by machine-learning experts and would greatly benefit from the adoption of standards for modeling and reporting.
Accordingly, our goal is to contribute to the progress and improved comparability within the field by providing our dataset ADORE (Schür et al. 2023). Its focus is on acute mortality in aquatic species from the taxonomic groups of fish, crustaceans, and algae. For this it is supposed to serve as a benchmark dataset for machine learning in ecotoxicology. Model performances in studies on machine learning are only really comparable to each other when they were obtained on the same dataset with a comparable chemical space and species scope. Put simply, a good model performance on a dataset containing only data from a single species (assumed the number of datapoints is sufficiently high) is easier to obtain than on a model with a hundred different species. The latter includes far more factors influencing data variability, not the least of which is the difference in the sensitivity of species to chemicals. Hence, the machine learning revolution depends on the availability of large datasets that provide a common ground on which to train, benchmark, and compare models. This was made clear through the already established benchmark datasets, such as CIFAR (https://www.cs.toronto.edu/~kriz/cifar.html), ImageNet (https://www.image-net.org) and CAMELS (Addor et al. 2017).
Representing chemicals and species
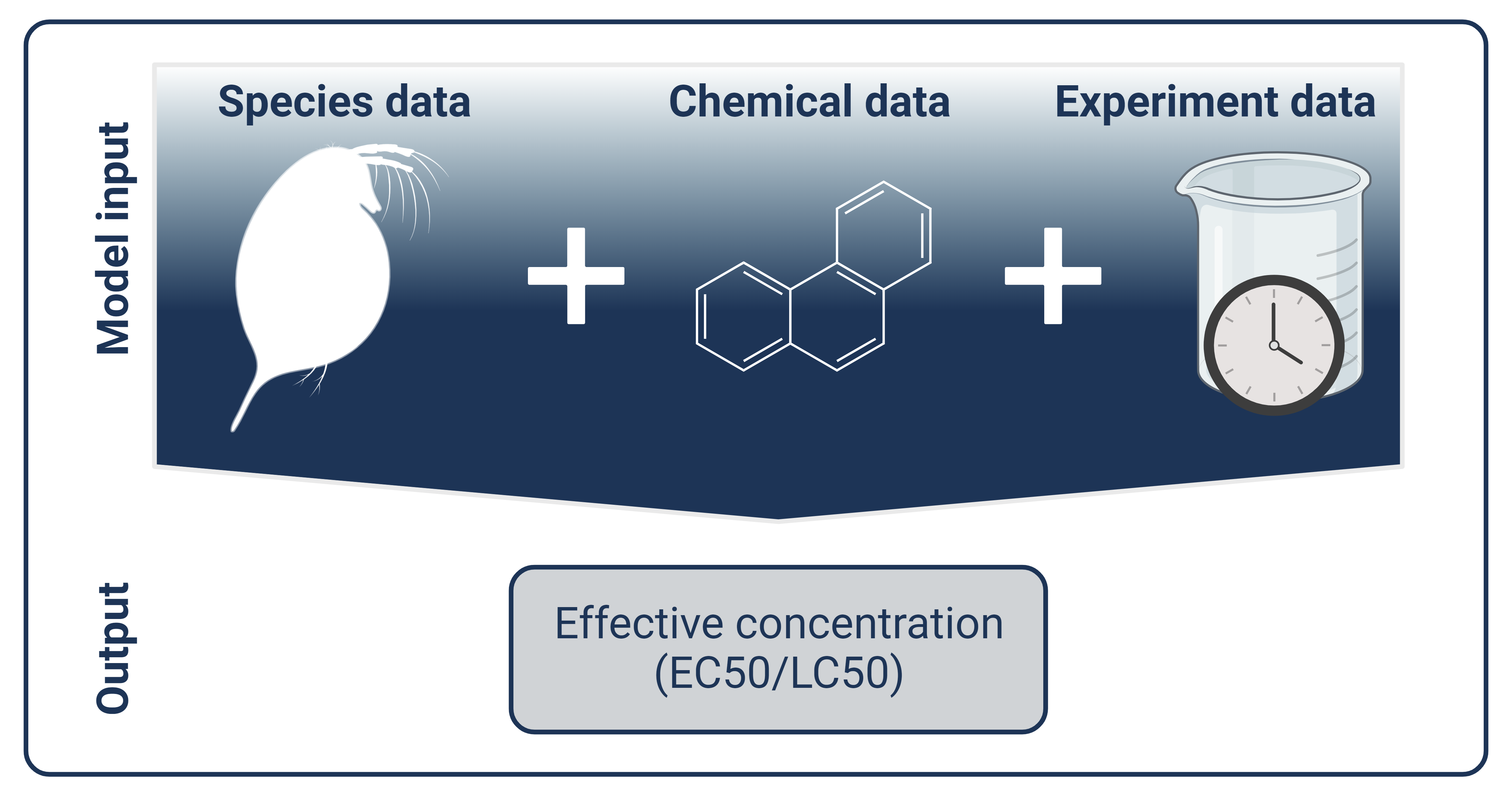
When attempting to predict ecotoxicological outcomes through machine learning, one needs to find data that adequately translates the components of an experiment into something a ML model can use to base its prediction on. This, on the one hand, includes information on the chemical, and on the other hand, on the target species. Chemical information can take the form of basic chemical properties (water solubility, measures of lipophilicity, molecular weight, etc.) and molecular representations. The latter are ways to describe a molecule and its substructures in a way that can be understood by an algorithm (Cartwright 2020). Several kinds of molecular representations exist; our dataset contains four common fingerprints (PubChem, MACCS, Morgan, ToxPrints), the molecular embedding mol2vec, and the molecular descriptor Mordred. We provide these so researchers have many different options to analyze their model performances and investigate the impact of those representations on their own. Meanwhile, adequately representing what makes a species a species, distinguishes it from other species and shapes their response to a chemical is less than trivial and often restricted by availability of the data for a large range of species. Here, we included ecological, life-history, and phylogenetic information. The latter describes how closely related two species are to each other based on the time since their lineages diverged from their last common ancestor species. The inclusion of this feature is based on the observation that species that are more closely related to each other share a similar sensitivity profile to chemicals compared to less-related species.
Splits and challenges
The gauging of model performance depends on splitting the dataset into training data that is presented to the model to learn patterns in the data that can be used to make predictions and testing data. The quality of the model predictions tested on the testing dataset that the model has never seen until that point and where it is asked to predict the outcome. The difference between the known true outcome (the ground truth) and the prediction is how well or poorly the model performs. Several ways exist to arrive at a train-test-split and not all are equally useful. For many approaches, randomly distributing data points at a fixed ratio across train and test set is sufficient. Our experimental data, however, contains many duplicate values that overlap in species, chemical, and experimental variables, but produce a different outcome. Randomly dividing these values across train and test set would result in data leakage, i.e. the model is asked to make a prediction on data that it has been trained on, resulting in it not needing to do a prediction but just recalling what it already knows. This artificially leads to overly optimistic model performances and is a common problem in ML-based research (Kapoor and Narayanan 2023). This is why, in our paper, we discuss different approaches to train-test-splitting and provide fixed splittings for others to work with. We also defined several challenges for others to compete with us on our dataset ranging from making predictions on algae and invertebrates as a surrogate for toxicity in fish, optimizing performance on a broad dataset on 140 fish species or on single, well-represented, model species.
The way forward
We hope our benchmark dataset helps open up ecotoxicology to non-biologist machine-learning-experts and moves the field closer to established methods for better reproducibility and comparability. We invite others to compete with us on making predictions across the different challenges or using our dataset for their own analyses and to answer other relevant questions from ecotoxciology. Learn more about the MLTox project here.
References
Addor, Nans, Andrew J. Newman, Naoki Mizukami, and Martyn P. Clark. 2017. “The CAMELS Data Set: Catchment Attributes and Meteorology for Large-Sample Studies.” Hydrology and Earth System Sciences 21 (10): 5293–5313. https://doi.org/10.5194/hess-21-5293-2017.
Cartwright, Hugh M, ed. 2020. Machine Learning in Chemistry: The Impact of Artificial Intelligence. Theoretical and Computational Chemistry Series. Cambridge: Royal Society of Chemistry. https://doi.org/10.1039/9781839160233.
Hartung, Thomas. 2023. “ToxAIcology – The Evolving Role of Artificial Intelligence in Advancing Toxicology and Modernizing Regulatory Science.” https://www.altex.org/index.php/altex/article/view/2692
Hartung, Thomas, and Aristides M Tsatsakis. 2021. “The State of the Scientific Revolution in Toxicology,” https://doi.org/10.14573/altex.2106101.
Kapoor, Sayash, and Arvind Narayanan. 2023. “Leakage and the Reproducibility Crisis in Machine-Learning-Based Science.” Patterns, August, 100804. https://doi.org/10.1016/j.patter.2023.100804.
Muratov, Eugene N., Jürgen Bajorath, Robert P. Sheridan, Igor V. Tetko, Dmitry Filimonov, Vladimir Poroikov, Tudor I. Oprea, et al. 2020. “QSAR without Borders.” Chemical Society Reviews 49 (11): 3525–64. https://doi.org/10.1039/D0CS00098A.
Schür, Christoph, Lilian Gasser, Fernando Perez-Cruz, Kristin Schirmer, and Marco Baity-Jesi. 2023. “A Benchmark Dataset for Machine Learning in Ecotoxicology.” Scientific Data 10 (1): 718. https://doi.org/10.1038/s41597-023-02612-2.
Follow the Topic
-
Scientific Data
A peer-reviewed, open-access journal for descriptions of datasets, and research that advances the sharing and reuse of scientific data.

Related Collections
With Collections, you can get published faster and increase your visibility.
Genomics in freshwater and marine science
Publishing Model: Open Access
Deadline: Jul 23, 2026
Genomes of endangered species
Publishing Model: Open Access
Deadline: Jul 01, 2026




Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in