Do Large Language Models reason like us?
Published in Neuroscience and Computational Sciences
By now everyone has heard about Large Language Models (LLMs) and their wonderful exploits. It seems impossible not to: every other day, media portals around the world show language models becoming more and more apt in matching and even surpassing human capabilities, blurring the limits of what’s possible in the field of Artificial Intelligence (AI). But why are these models capable of “surprising” us with their feats of thought? Are AIs (and programs in general) not supposed to do whatever it is that their authors dictate them to do? Not quite, as it turns out. When artificial intelligence implementations are run on a combination of deep neural networks and transformer architectures, results can take a turn to the unexpected. Much like our own human brains, these particular AIs are dotted with a recursive and multi-layered processing structure that makes it almost impossible to predict which course of action they will take when solving a task, or for that matter, where exactly lie the limits to their immense capabilities. Namely, the behaviors of LLMs "emerge" as they face novel tasks, much like human behavior does. For many cognitive scientists around the world, this warrants the study of LLMs’ behavior using the same tools that we would typically implement to understand our own behavior, and ultimately, our own cognition.
In the latest installment of our work, our team has undertaken this challenge by picking some of the most commonly used tools in the study of human rationality, and optimized them to analyze the reasoning capabilities of various LLMs, including ChatGPT, and simultaneously compare them to human reasoning. Our findings underscore the existence of reasoning errors within these models akin to those of humans, despite the mechanisms behind their reasoning processes not being the same. And interestingly, in their most recent and powerful versions, our findings show that their capabilities seem to easily surpass human reasoning benchmarks.
What are "Large Language Models"?
Language models are AIs capable of parsing human language, and responding to it with self-generated coherent bouts of human language. Their technique is as straightforward as it is powerful: language models simply predict, based on context, how likely it is for a word to be followed by another word within a sentence, and follows this probability tree to generate its own linguistic output. Incredibly, it is by virtue of this sole operation that LLMs have managed to produce the dashing performances we have come to know in the present date.
While this language generation strategy may be simple, the mechanisms behind it certainly are not. LLMs are algorithms based on artificial neural networks, inspired by the functioning of the biological neural networks that make up the human brain (and possibly clouded by the same complexity). In a network, nodes of artificial neurons receive a constant flow of multiple information values as input, and generate just as many output values after processing, with unpredictable impact. In particular, LLMs are beyond most "classic" artificial neural network algorithms by virtue of their specific transformational architecture and size (in the order of several billion "neurons"), which was specifically designed for training on gargantuan textual databases, sometimes as large as the Internet itself.
Due to their training, size and structure, LLMs showed impressive performances when solving the tasks for which they were originally designed, including text creation, translation, and correction. But since, LLMs have also demonstrated surprisingly robust performance in a variety of diverse human and human-like tasks, ranging from spontaneous use of mathematics to basic forms of reasoning. In other words, the network that supports the generation of language appears to harbor (and act upon) additional knowledge, including conceptual, spatial and temporal representations of the world, that the network itself was not originally designed to contemplate. Moreover, LLMs appear capable of learning new tasks from zero, after only a few examples, displaying an ingenuity previously reserved to humans and advanced mammals alone. As a result, we have come to a unique impasse in the field of AI: these systems are currently so complex that we find ourselves unable to predict their full range of abilities in advance. Thus, we must "discover" their cognitive capacities experimentally, much like we do with human cognition. In the face of this challenge, our team and others have hypothesized that the tools developed in the field of psychology could be relevant for studying LLMs emerging properties, including its apparent cognition and its behavioral outputs.
Why Study Reasoning in Large Language Models?
Given the role that LLMs seem destined to play in our near-future lives, understanding how they reason and make decisions is a fundamental scientific and societal milestone. Efficient communication with these models may be the single most important difference between LLMs enhancing our daily lives, or encumbering them beyond recognition. Further, psychology research also stands to gain from this endeavor: there is a distinct possibility that artificial neural networks could also serve as efficient cognitive models. Indeed, a growing body of evidence suggests that neural networks implemented in LLMs provide precise predictions concerning the neuronal activity involved in vision and language processing. For example, the neuronal activity of neural networks trained to recognize objects correlates significantly with the neuronal activity recorded in the visual cortex of an individual performing the exact same task. And it doesn’t stop there: recent findings point to these networks being quite useful for reproducing human choice behavior, biases and learning , making them ideal candidates for modeling human reasoning.
Human (and Super Human) Performances
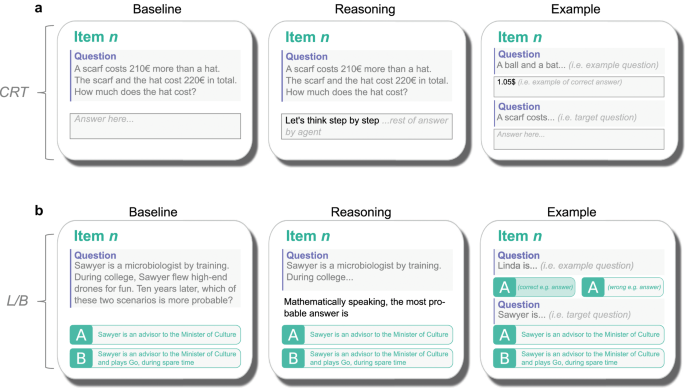
In our work, we primarily focused on LLMs from OpenAI, the company behind the language models used in ChatGPT. We created an interface that allowed us to simultaneously present humans and models with novel, optimized versions of classical reasoning problems (i.e. the Linda/Bill problem and the Cognitive Reflection Test![]()
![]()
![]()
![]() ) , and observe their behaviours. We tested several versions of GPT-3, starting with the earlier models and working our way up the release chain diachronically, until reaching ChatGPT and GPT-4. In contrast to humans, LLMs responses exhibited three distinct behavioral patterns, closely linked to their release dates and level of advancement:
) , and observe their behaviours. We tested several versions of GPT-3, starting with the earlier models and working our way up the release chain diachronically, until reaching ChatGPT and GPT-4. In contrast to humans, LLMs responses exhibited three distinct behavioral patterns, closely linked to their release dates and level of advancement:
- Older models were simply unable to produce sensible answers.
- Intermediate models responded to the questions, but often engaged in intuitive reasoning that led to human-like errors: they favored "System 1" reasoning (fast, instinctive, emotional, less resource intensive) as opposed to “System 2” reasoning (slower, reflective, but more resource intensive):
[Example Item from the "Cognitive Reflection Test”![]()
![]()
![]()
![]() :]
:]
- Question asked: A bat and a ball cost a total of $1.10. The bat costs $1.00 more than the ball. How much does the ball cost?
- Intuitive answer ("System 1"): $0.10; [preferred by these models]
- Correct answer ("System 2"): $0.05.
- The latest generation of models (ChatGPT and GPT-4) exhibited performances that surpassed that of humans in terms of rationallity, always privileging the correct answer no matter the context, or how appealing the intuitive answer would be.
A complete outline of the models tested and their results in terms of reasoning performance (compared to humans) can be seen in the figure below. Overall, our work identified a positive trajectory which could be conceived as a "developmental" or "evolutionary" path, in which these artificial individuals/species seem to be acquiring more and more skills over time.
Example items of our optimized versions of the Cognitive Reflection Test, and the Linda/Bill problem, alongside the performances these tests elicited in all tested models and humans. Presentation was identical for humans and models, to ease the comparison between the two.
Improving models with a human approach
We then wondered whether it would be possible to improve the performance of the models exhibiting "intermediate" performances (i.e., presenting human-like cognitive biases) by "encouraging" them to approach the problems differently, much as one would do with a human participant. We tested a series of different strategies, with varying degrees of success. We found that a very simple way to improve model performance was to literally ask them to "think step by step" before posing each question. Another very effective solution was to show them an example of how to correctly solve each problem, which induced a rapid "one-shot" learning behavior. These results indicate once again that the performance of these models is not fixed, but plastic: within the same model, apparently neutral contextual modifications can alter performance much like in humans, where framing and context effects are not just common but instrumental.
Not everything that speaks is human
Despite the aforementioned similarities, it must be underscored that we observed numerous LLM behaviors that deviated from human standards. For one, only a few of the dozen models we tested could approximate the level of correct and intuitive response rates achieved by humans. In our experiments, AI models were either far better or much worse. Additionally, we found evidence that model and human reasoning processes could be fundamentally different, as the questions that posed the most difficulty for humans were not necessarily perceived as the hardest by models, and vice-versa. Further, we also observed that the reproducibility of experiments using these models was somewhat questionable: after retesting ChatGPT and GPT-4 a few months apart, we observed that their performances had changed, and not necessarily for the better. This is not entirely surprising considering that OpenAI oftentimes modifies their models without informing the scientific community (an inherent risk of working with proprietary models).
These observations suggest that, at least at the present time, we are not ready to substitute human participants with LLMs to better understand human psychology, as some authors have suggested recently, or model our own cognition on their structure. We propose that the path forward in LLM research should accompany the development of open and transparent models, which would ultimately ensure greater control when conducting experiments, and give experimenters the possibility to tweak and refine models at a fundamental level to render them more human (a goal of interest for science, but potentially less appealing for companies chasing performance). Overall, we still have a long road ahead when it comes to understanding the “thought processes” of LLMs, and whether these could be hijacked to better understand human thought. Our work has brought us one step closer to this end, hopefully paving the way for future endeavors trying to understand and improve reasoning in both humans and machines.
Follow the Topic
-
Communications Psychology
An open-access journal from Nature Portfolio publishing high-quality research, reviews and commentary. The scope of the journal includes all of the psychological sciences.

Related Collections
With Collections, you can get published faster and increase your visibility.
Replication and generalization
Publishing Model: Open Access
Deadline: Dec 31, 2026
Comparative Psychology of Cognition, Affect, and Behaviour
Publishing Model: Open Access
Deadline: Oct 31, 2026
Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in