Driving and suppressing the human language network using large language models
Published in Neuroscience, Protocols & Methods, and Computational Sciences
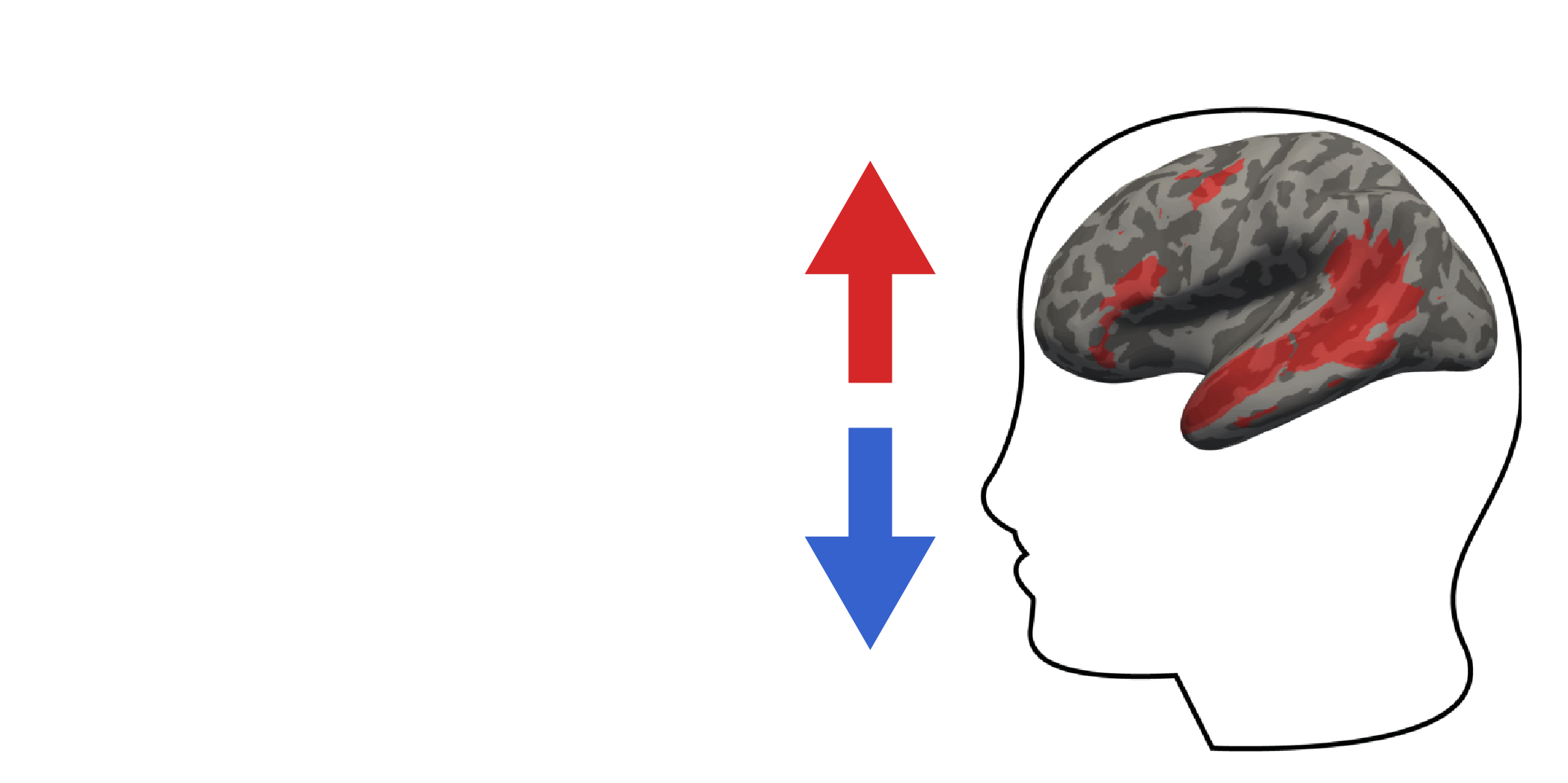

“I’m progressive and you fall right.”
While you read the sentence above, your brain’s language system was hard at work.
The brain’s language system consists of a set of regions in the frontal and temporal parts of the brain, lateralized to the left hemisphere in most individuals. These regions are implicated in understanding language, both while reading and listening to speech. If some of these regions are damaged in adulthood, you will end up with linguistic deficits. These brain regions, denoted as the “language system”, form an interconnected network that selectively supports language processing. However, obtaining an understanding of the internal representations and the processes that occur within this system remains a challenge.


The left hemisphere of a surface-inflated brain. The red demarcations illustrate the typical language areas across many individuals.
In this study, we asked: what kinds of sentences will make the language system respond the most? Generally speaking, it is very useful to know the "preferred" stimulus for a given brain cell or region. This approach is rooted in the pioneering work by Hubel and Wiesel in the late 1950’s and 1960’s, who found that certain brain cells in the visual areas of cats and monkeys responded strongly and selectively to specific visual features, such as light at different orientations. These findings provided critical insight into the building blocks that enable visual perception.
In our study, our focus was not the visual system or orientations of light – rather, we wanted to discover the preferred stimulus of the human language system. As a first step towards this goal, we curated a set of 1,000 6-word-long sentences. These sentences were sampled from various text corpora, including fiction stories, web text, and transcribed spoken text, spanning a wide range of topics. To study the language system responses to these sentences, we recorded brain activity using functional magnetic resonance imaging (fMRI) while participants read each sentence. Each participant spent around four hours in the fMRI scanner across two days. From these scanning sessions, we obtained an image of brain activity for each of the 1,000 sentences across all "3D pixels" in the brain. We isolated the 3D pixels that comprise the language system in each participant and examined the activity in this system to the 1,000 sentences. The language system showed quite a bit of variation in its response to these sentences: some sentences elicited a high response, some sentences elicited a lower response. However, considering the vast number of possible 6-word sentences, it was impossible to know whether our set of 1,000 sentences by pure chance included the language system’s "preferred" sentences.
So as a second step, we took a targeted, data-driven approach to identify the language system’s "preferred" sentences that would elicit maximal activity in this network. To do so, we leveraged recent evidence that large language models, like ChatGPT, are predictive of brain responses during language processing. Because large language models are predictive of brain responses, we can invert the process: Instead of predicting brain responses, we can select a brain region of interest and use the model to predict stimuli that will drive the brain region to a desired state. In our case, our brain region of interest was the language system, and our desired state was maximal activity (“drive sentences”). To span the full range of brain responses and to ensure that our method did not indiscriminately increase brain responses, we also identified sentences to elicit minimal activity (“suppress sentences”).
To identify our new drive and suppress sentences, we fitted a regression model from the sentence representations of the large language model to the average brain activity to the 1,000 sentences from our five participants. The utility of such a regression model is its ability to take as input any arbitrary sentence and output the predicted level of brain activity associated with that sentence. We applied this regression model to a massive number of sentences (~1.8 million), obtaining a predicted response in the language system for each of these 1.8 million sentences. From this large set, we selected 250 drive sentences that were predicted to elicit highest brain activity, sentences such as “Changing PhD group: Yes or Not?” and “Buy sell signals remains a particular.”. Similarly, we identified our suppress sentences as the 250 sentences that were predicted to elicit minimal activity, such as “We were sitting on the couch.” and “They walked out onto the balcony.”.
We then wanted to causally test whether the new sentences would perturb brain activity as predicted. Critically, instead of relying on the original five participants used to develop the regression model, we recruited three new participants for this experiment. In this manner, we asked whether our predictions about the drive and suppress sentences would hold true for these new participants. Such generalization would indicate that our model had discovered features of language processing that are shared across humans.
The results of the new experiment confirmed our predictions: The drive and suppress sentences elicited respectively high and low activity in the three new participants’ language system. Hence, we had trained a regression model to generate predictions about the magnitude of activation in the language system for the new drive/suppress sentences and then closed the loop, so to speak, by collecting brain data for the new sentences from new participants, effectively “controlling” their brain activity.
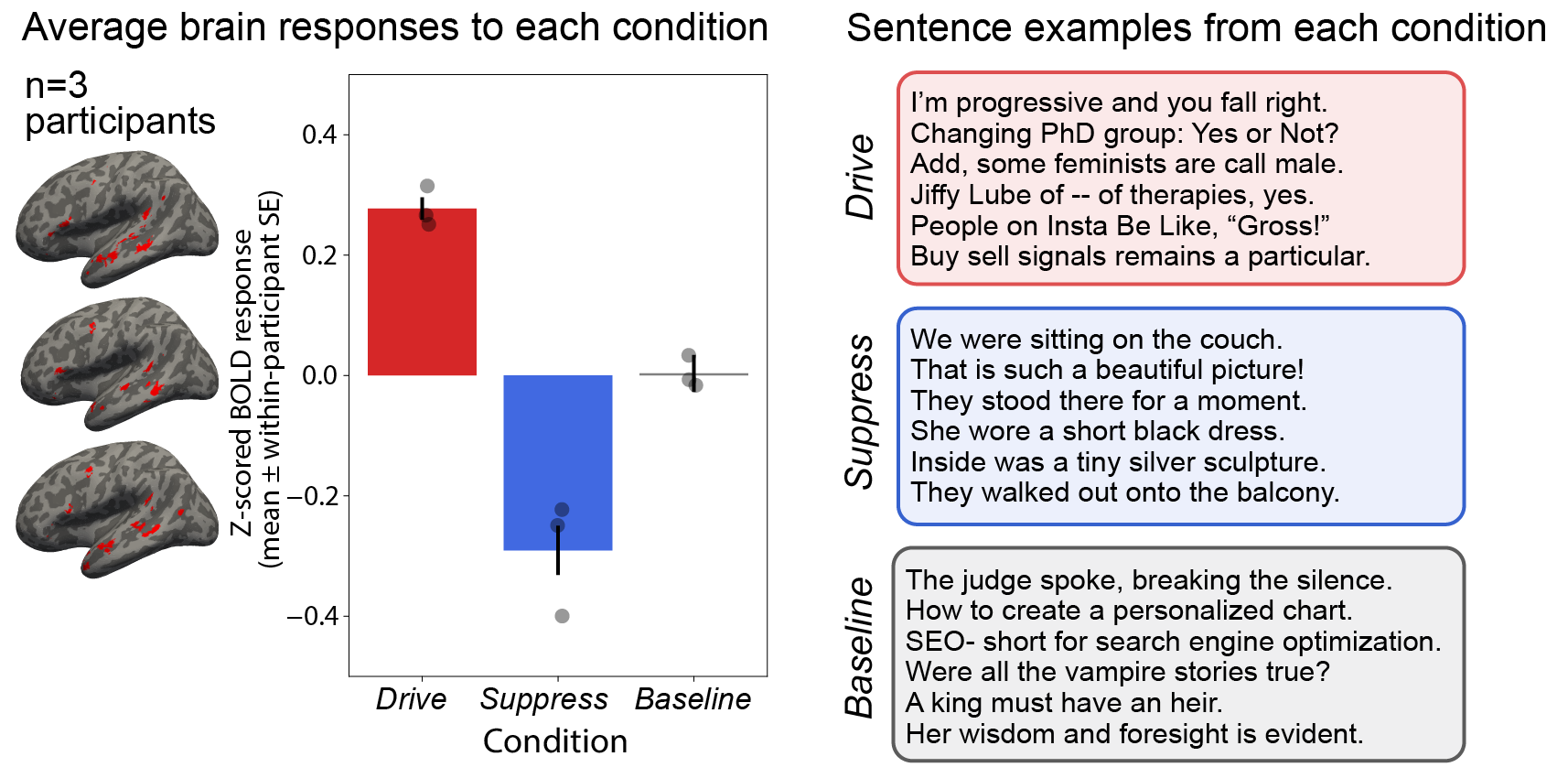
The bars show the normalized language system fMRI activity averaged across the three participants to the “drive” condition (designed to elicit high brain activity), the “suppress” condition (designed to elicit minimal activity), as well as a diverse set of 1,000 sentences (“baseline”). The boxes on the right show examples from each condition.
With a diverse set of sentences selected by our model, spanning the full range of brain responses from low to high, we could characterize the preferred stimulus of the language system. We discovered that sentences with a certain degree of unusual grammar and/or meaning elicit the highest activity in the language system – for instance, such as the sentence in the beginning of this article: “I’m progressive and you fall right.”. Although the sentence is composed of standard English words, the sentence-level meaning is challenging to interpret – the unexpected construction and ambiguous meaning of this type of sentence puts the language system to hard work. However, what if the stimulus becomes even more unusual, such as “LG'll obj you back suggested Git.”? The responses to such sentences are quite low: The language system does not respond strongly to these nonsensical sentences that do not adhere to the natural statistics of English. In other words, a stimulus has to sufficiently resemble the kind of input we encounter in our experiences with language, given that our experiences presumably tune the language system to those kinds of input.
Hence, specific areas of your brain – the language system – will respond selectively to linguistic input that aligns with the statistics of the language and will work really hard to make sense of the words and how they go together.
Follow the Topic
-
Nature Human Behaviour
Drawing from a broad spectrum of social, biological, health, and physical science disciplines, this journal publishes research of outstanding significance into any aspect of individual or collective human behaviour.

Related Collections
With Collections, you can get published faster and increase your visibility.
Digital Media and Mental Health
Publishing Model: Hybrid
Deadline: Oct 30, 2026
Basic Psychological Needs and Well-Being
Publishing Model: Hybrid
Deadline: Nov 27, 2026



Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in