Driving Healthcare Innovation: A Three-Pronged Approach to Guarantee Safety and Equity of AI
Published in Healthcare & Nursing, Cancer, and Computational Sciences


In the ever-evolving landscape of healthcare, machine learning applications have emerged as powerful tools for predicting critical outcomes, aiding in clinical decision-making, and optimizing patient care. From predicting sepsis risk1 to forecasting hospital readmissions2,3, these models offer promising capabilities. However, before these models find their way into clinical practice, a rigorous validation process is imperative to ensure their reliability and safety.
The standard validation process involves both internal and external evaluations prior to deployment, which help optimize model performance, prevent overfitting, and improve transportability. However, a critical limitation of these approaches is that they are often based on a limited number of data sources collected at specific points in time4. As healthcare systems are dynamic and patient populations vary, these validations might not accurately capture the performance of the model in all situations. Enter continuous monitoring – a paradigm shift that aligns with the dynamic nature of healthcare.
Continuous Model Validation: A Roadmap for Reliability
Imagine a car: it undergoes testing before hitting the roads and comes equipped with safety mechanisms like brakes, seatbelts, and airbags. Similarly, the validation of machine learning models requires a three-pronged approach to maintain high performance over time:
- Initial Validation: This is akin to a car's braking system – a foundational safety mechanism. During model development, internal and external validations are performed to optimize performance and detect potential biases and errors before deployment. This helps prevent foreseeable issues from affecting patient care.
- Real-time Monitoring: Just as seatbelts ensure passenger safety throughout a car journey, continuous monitoring of deployed models ensures ongoing performance evaluation. This proactive approach detects biases and performance hiccups as they arise, allowing for swift corrective action.
- Timely Updates: Just like airbags deploy to protect passengers during a collision, models are updated when issues are identified. This involves retraining or fine-tuning models with new data, keeping them effective and reliable over time.
These three steps collectively guarantee that machine learning models in healthcare maintain their high performance and accuracy throughout their lifecycle, mirroring the reliability of a well-designed car.
Assessing Deployed Model Performance: Leading vs. Lagging Indicators
However, assessing model performance during deployment poses a unique challenge – there is often a delay between when a model prediction is made and when the ground truth is available, which delays the evaluation of performance. This is akin to gauging a car's safety without experiencing an accident. This is where the concept of leading and lagging indicators comes into play:
Lagging Indicators: These indicators, much like post-accident data analysis, rely on known outcomes to assess performance with metrics like AUC. However, there's a delay between when an issue arises and when it's detected due to the time required to collect ground truth data.
Leading Indicators: Similar to monitoring a car's condition during a journey, leading indicators focus on shifts in incoming data distributions compared to training data. Detecting changes early on can signal potential performance decay, enabling proactive interventions.
By utilizing both leading and lagging indicators, healthcare practitioners can ensure a comprehensive understanding of model performance and safety.
Equity and Bias Mitigation: A Continuous Commitment
Healthcare disparities and bias are significant concerns in machine learning applications. Just as cars are designed for diverse road conditions, models should be built for equitable predictions across diverse demographic and socioeconomic groups. Monitoring these groups for fairness during both training and deployment ensures that biases are minimized and patient outcomes are not compromised due to systemic inequalities.
Application in Clinical Practice: Predicting ED Visits in Oncology
To put these principles into action, our team embarked on a project to reliably predict the risk of emergency department (ED) visits for oncology patients5. These individuals often seek urgent care due to cancer therapy side effects. By identifying high-risk patients in advance, clinical resources can be allocated strategically, potentially preventing unnecessary ED visits and other adverse events.
Our model, developed in collaboration with a large academic medical center, underwent rigorous validation. During validation, the model achieved an impressive AUC of 0.8 and Brier score of 0.071, proving its predictive capabilities. Real-world monitoring over a 77-day period further demonstrated its sustained performance, and highlighted the importance of continuous vigilance. In one instance, a sudden drop in predictions was traced to a technical issue, which was swiftly addressed to maintain model effectiveness (Figure 1).
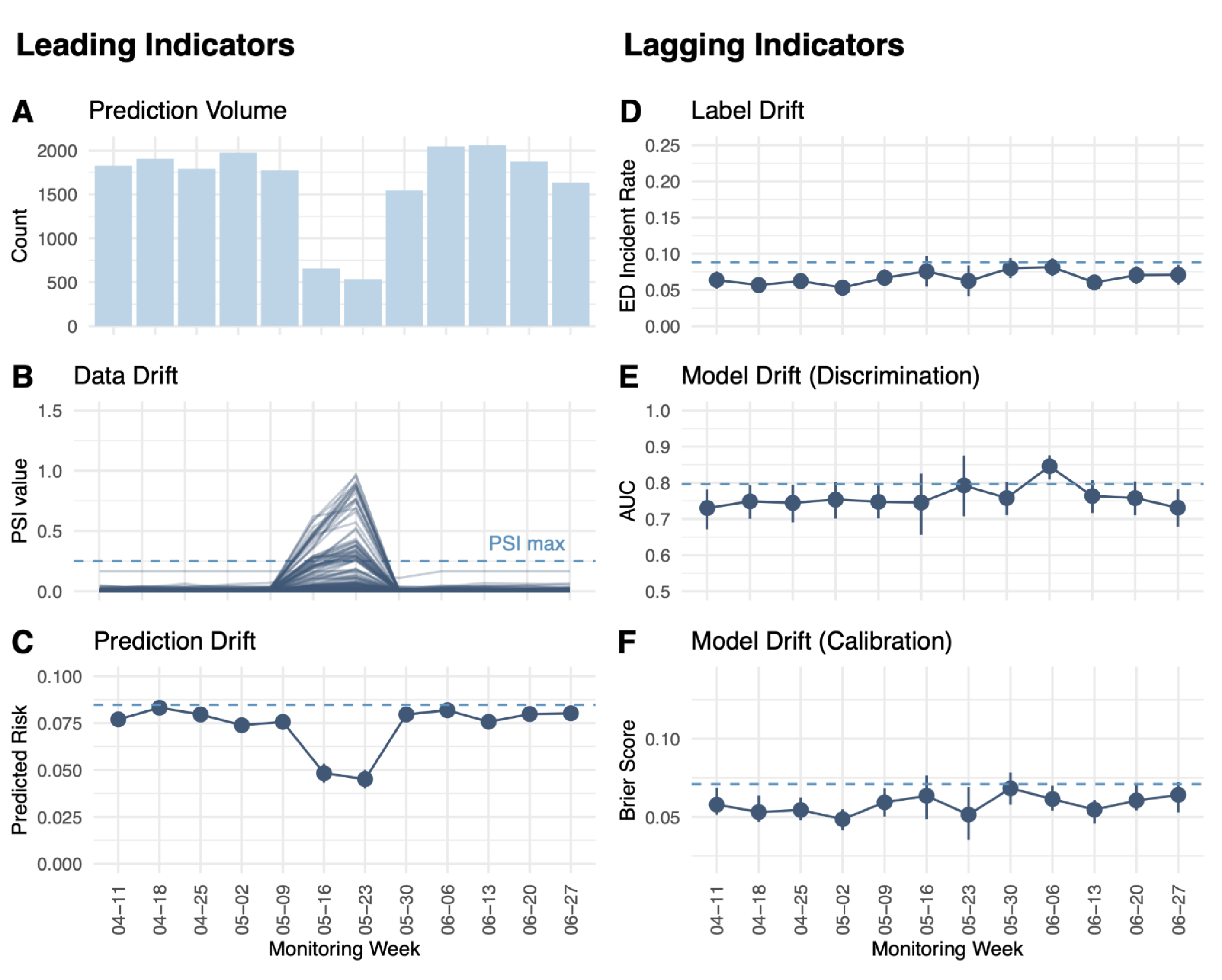
Figure 1. Real-world monitoring of leading and lagging indicators for the ED visit prediction model in production.
Future Steps: Translating Performance to Improved Patient Outcomes
While having a robust machine learning model is crucial, the ultimate goal is to enhance patient outcomes and reduce healthcare costs. Collaborating with clinicians, we're planning a randomized clinical trial to measure the impact of our prediction application on various patient outcomes, including adverse events and hospitalizations.
Continuous monitoring is a requirement to releasing safe and trustworthy machine learning applications in healthcare. Like the safety mechanisms in a car, this approach ensures ongoing reliability, fairness, and effectiveness in the rapidly evolving world of clinical practice. By embracing this paradigm shift, we can create more effective and equitable clinical decisions.
References
- Henry KE, Hager DN, Pronovost PJ, Saria S. A targeted real-time early warning score (TREWScore) for septic shock. Sci Transl Med. 2015. Aug 5;7(299)ra122.
- Van Walraven C, Dhalla IA, Bell C, Etchells E, Stiell IG, Zarnke K, Austin PC, Forster AJ. Derivation and validation of an index to predict early death or unplanned readmission after discharge from hospital to the community. CMAJ. 2010. Apr 6;182(6):551-7.
- Donze J, Aujesky D, Williams D, Schnipper JL. Potentially avoidable 30-day hospital readmissions in medical patients: derivation and validation of a prediction model. JAMA Intern Med. 2013. Apr 22;173(8):632-8.
- Van Calster B, Steyerberg EW, Wynants L, van Smeden M. There is no such thing as a validated prediction model. BMC Med. 2023. Feb 24;21(1):70.
- George R, Ellis B, West A, Graff A, Weaver S, Abramowski M, Brown K, Kerr L, Lu, S-C, Swisher C, Sidey-Gibbons C. Ensuring fair, safe, and interpretable artificial intelligence-based prediction tools in a real-world oncological setting. Commun Med. 2023. Jun 22;3(1):88.
Follow the Topic
-
Communications Medicine
A selective open access journal from Nature Portfolio publishing high-quality research, reviews and commentary across all clinical, translational, and public health research fields.

Related Collections
With Collections, you can get published faster and increase your visibility.
Exercise and Physical Activity in Health and Disease
Publishing Model: Open Access
Deadline: Sep 03, 2026
Life Course Epidemiology
Publishing Model: Open Access
Deadline: Sep 30, 2026

Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in