Integrated multimodal artificial intelligence framework for healthcare applications
Published in Healthcare & Nursing

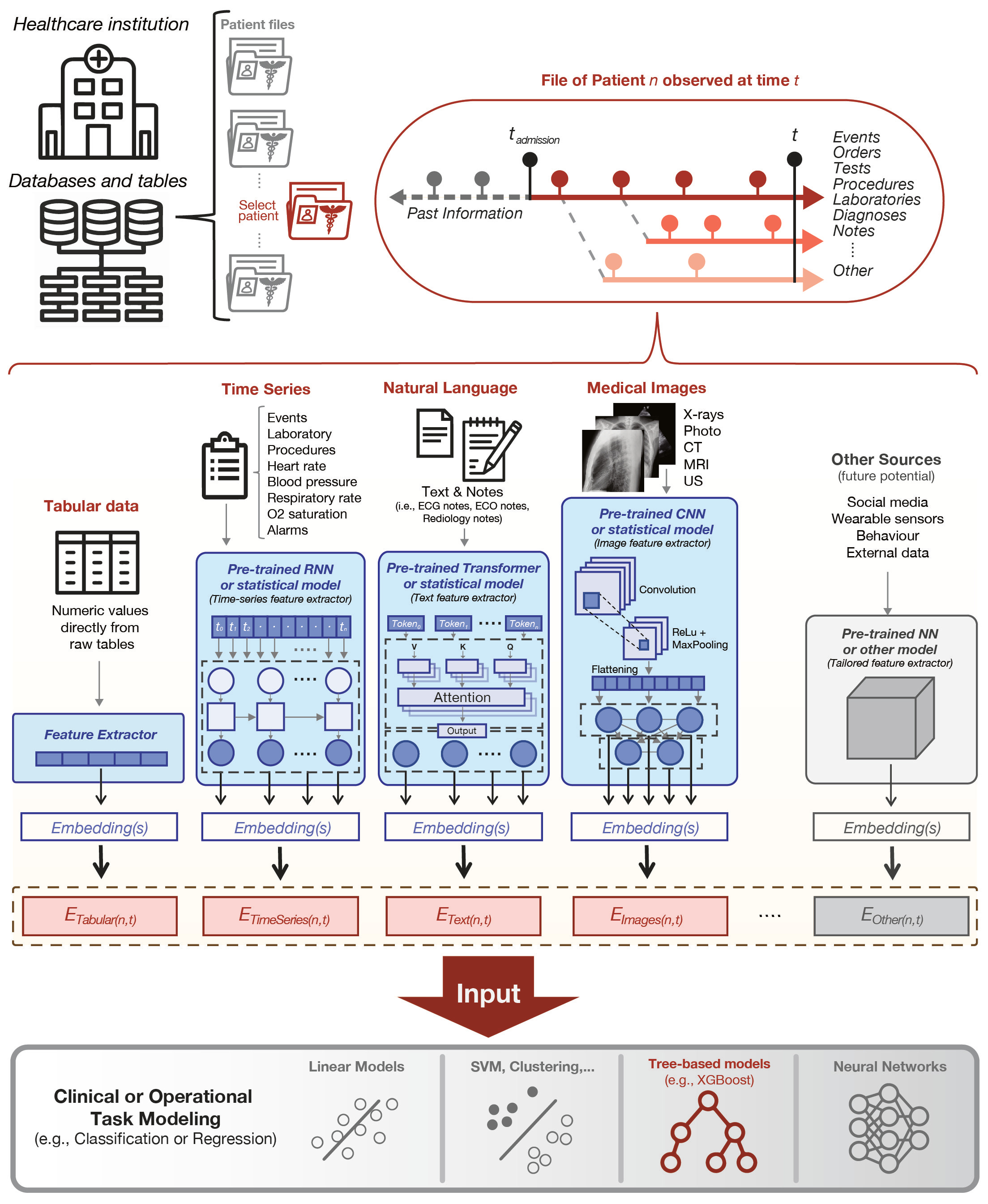
Holistic Artificial Intelligence in Medicine (HAIM) framework
Artificial intelligence (AI) systems hold great promise to improve healthcare over the next decades. Specifically, AI systems leveraging multiple data sources and input modalities are poised to become a viable method to deliver more accurate results and deployable pipelines across a wide range of applications.
The HAIM framework facilitates the generation and testing of AI systems that leverage multimodal inputs. Our approach uses generalizable data pre-processing and machine learning modeling stages that can be readily adapted for research and deployment in healthcare environments.
Standardized patient data processing is ready for fast prototyping and deployment
We generated the individual files containing patient-specific information for single hospital admissions by querying the aggregated multimodal dataset from MIMIC-IV v1.0 and MIMIC-CXR-JPG v2.0.0. The resulting dataset, HAIM-MIMIC-MM, is a multimodal clinical database (N=34,537 samples) containing 7,279 unique hospitalizations and 6,485 patients, spanning all possible input combinations of 4 data modalities (i.e., tabular, time-series, text, and images) and 11 unique data sources.
The code to generate the aggregated HAIM-MIMIC-MM dataset is available at our PhysioNet repository (https://doi.org/10.13026/dxcx-n572) as well as our GitHub repository (https://github.com/lrsoenksen/HAIM).
The generated embeddings from input modalities include tabular data, structured time series, unstructured free text, single-image vision, and multi-image vision. We implemented fixed embedding extraction procedures based on standard data modalities (i.e., tabular data, time-series, text, and images) to reduce its dependence on site-specific data architectures and allow for a consistent embedding format that may be applied to arbitrary ML pipelines. For example, we extracted fixed-size embeddings for free text using ClinicalBERT, a transformer-based model pre-trained on a large corpus of biomedical and medical text, and for images using a pre-trained Densenet121 convolutional neural network (CNN) previously fine-tuned on the X-ray CheXpert dataset (i.e., Densenet121-res224-chex).
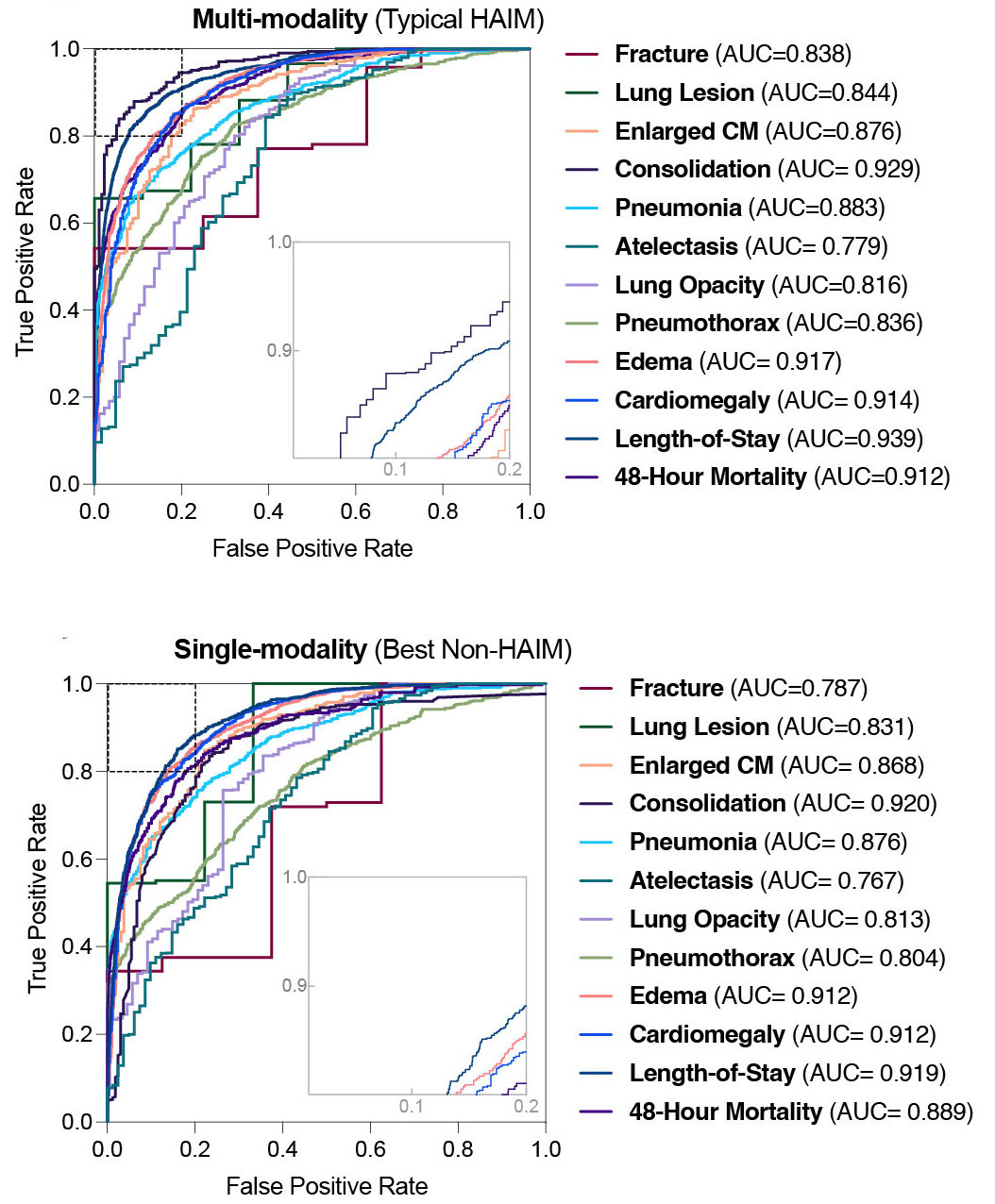
HAIM offers significant quantitative performance improvement over single modality
By training and characterizing 14,324 independent models on 12 predictive tasks using HAIM-MIMIC-MM, we show that HAIM can consistently and robustly produce models that outperform similar single-source approaches across various healthcare demonstrations (by 6-33%), including 10 distinct chest pathology diagnoses, along with length-of-stay and 48-hour mortality predictions.
Our HAIM framework displays consistent improvement on average AUROC across all models as the number of modalities and data sources increases. All 14,324 individual model AUROCs (10,230 for chest diagnosis prediction tasks, 2,047 for length-of-stay, and 2,047 mortality prediction) suggest that our HAIM framework can consistently improve predictive analytics for various applications in healthcare as compared with single-modality analytics. Quantitatively, our HAIM framework produces models with multi-source and multimodality input combinations that improve from average performance of canonical single-source (and by extension single-modality) systems for chest x-ray pathology prediction (∆AUROC: 6-22%), length-of-stay (∆AUROC: 8-20%) and 48-hour mortality (∆AUROC: 11-33%). Specifically, for chest pathology prediction, the minimum per task improvements include: Fracture (∆AUROC=6%), Lung Lesion (∆AUROC=7%), Enlarged Cardio mediastinum (∆AUROC=9%), Consolidation (∆AUROC=10%), Pneumonia (∆AUROC=8%), Atelectasis (∆AUROC=6%), Lung Opacity (∆AUROC=7%), Pneumothorax (∆AUROC=8%), Edema (∆AUROC=10%) and Cardiomegaly (∆AUROC=10%). Furthermore, the average percent improvement of all multimodal HAIM predictive systems is 9-28% across all evaluated tasks.
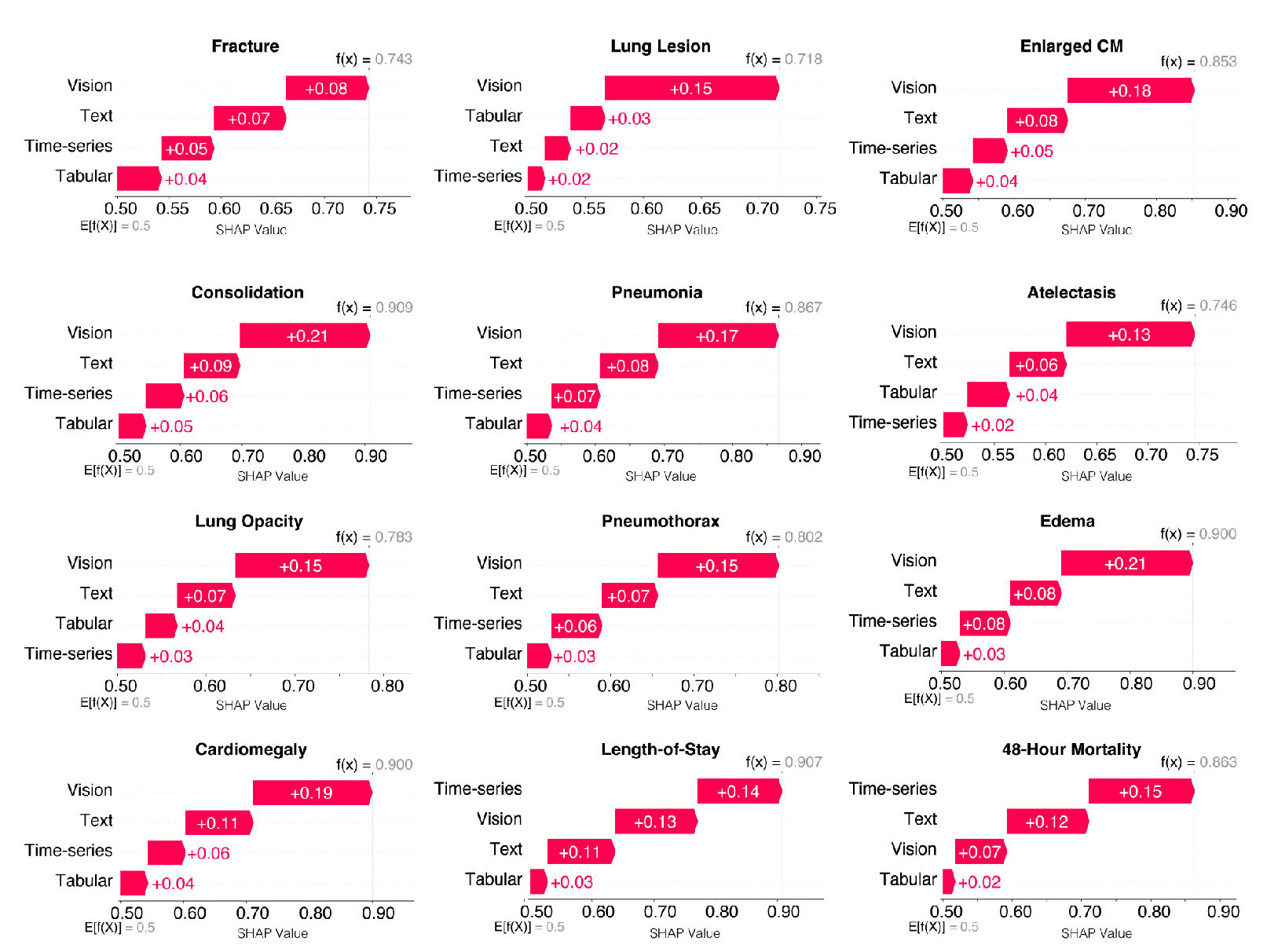
Quantification of modality contribution improves data understanding
We also quantify the contribution of each modality and data source using Shapley values, which demonstrates the heterogeneity in data modality importance and the necessity of multimodal inputs across different healthcare-relevant tasks.
Different tasks exhibit distinct distributions of aggregated Shapley values across data modalities and sources. In particular, we observe that vision data contributed most to the model performance for the chest pathology diagnosis tasks, but for predicting length-of-stay and 48-hour mortality, the patient’s historical time-series records appeared to be the most relevant.
Shapley values also provide a way to monitor errors and information loss propagation during the feature extraction and model training phases of our HAIM framework. Data modalities associated with small (or negative) Shapley values indicate either an absence of extracted information or error propagation leading to detrimental local effects on downstream model performance. This situation can be potentially addressed by removing such input data modalities or by selecting different pre-trained feature extraction models specific to that data modality.
Nevertheless, we see that across all tasks, in our specific sample HAIM-MIMIC-MM demonstrations, every single modality contributes positively to a monotonic trend with diminishing returns on the predictive capacity of the models, likely due to multimodal data redundancy. These observations attest to the potential value (and limitations) of using multimodal inputs and pre-trained feature extraction modules in frameworks like HAIM, which could be used to generate predictive models for diverse clinical tasks more cost-effectively than previous strategies.
Summary
Our work distinguishes itself from previously published systems in three main ways:
- First, our work systematically investigates the value of progressively adding data modalities and sources to clinical multimodal AI/ML systems in much greater detail and larger combinatorial input space than any prior investigation of such class systems. Previous works in this field assume advantageous properties to multimodality without clear validation of the dynamics of such expected performance benefits as data modalities are added.
- Second, our approach leverages externally validated open-sourced models as feature extractors to create unified vector representations of patient files that allow for much simpler downstream modeling of target variables. Furthermore, this framework enables and encourages users to update selected feature extractors more easily with new state-of-the-art or more advantageous methods as the community develops them, without requiring to re-train other feature extractors.
- Finally, our work demonstrates one of the highest numbers of sources and data modalities used so far in multimodal clinical AI/ML systems for EHRs, including tabular data, time-series, text, and images along with the use of interpretability techniques such as Shapley values.
Our system is also provided as an open-source codebase to allow clinicians and researchers to train and test their own multimodal AI/ML systems more easily with local datasets, pre-trained feature extractors, and their own clinical questions.
We hope that our HAIM framework can help reduce the time required to develop relevant AI/ML systems while efficiently utilizing human, financial, and digital resources in a more timely and unified approach than the current methods used in healthcare organizations. The generalizable properties and flexibility of our Holistic AI in Medicine (HAIM) framework could offer a promising pathway for future multimodal predictive systems in clinical and operational healthcare settings.
Follow the Topic
-
npj Digital Medicine
An online open-access journal dedicated to publishing research in all aspects of digital medicine, including the clinical application and implementation of digital and mobile technologies, virtual healthcare, and novel applications of artificial intelligence and informatics.

Related Collections
With Collections, you can get published faster and increase your visibility.
Synthetic Clinical Data and Privacy-Preserving Frameworks for Trustworthy Health AI
Publishing Model: Open Access
Deadline: Jun 03, 2027
Digital Biomarkers for Enabling Proactive Clinical Decisions
Publishing Model: Open Access
Deadline: May 18, 2027

![When PSMA-targeted therapy is not enough: high-risk localized prostate cancer after repeated [177Lu]Lu-PSMA radioligand therapy](/cdn-cgi/image/metadata=copyright,fit=scale-down,format=auto,quality=95,width=256,height=256/https://public-storage.zapnito.com/Ku6h7Yyp4Q0LXqRRMICCHR2v4LcOsmxMrmDPtOYuI1c)



Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in