LLMs must not only be accurate - they must be efficient enough to operate where it matters
Published in Statistics

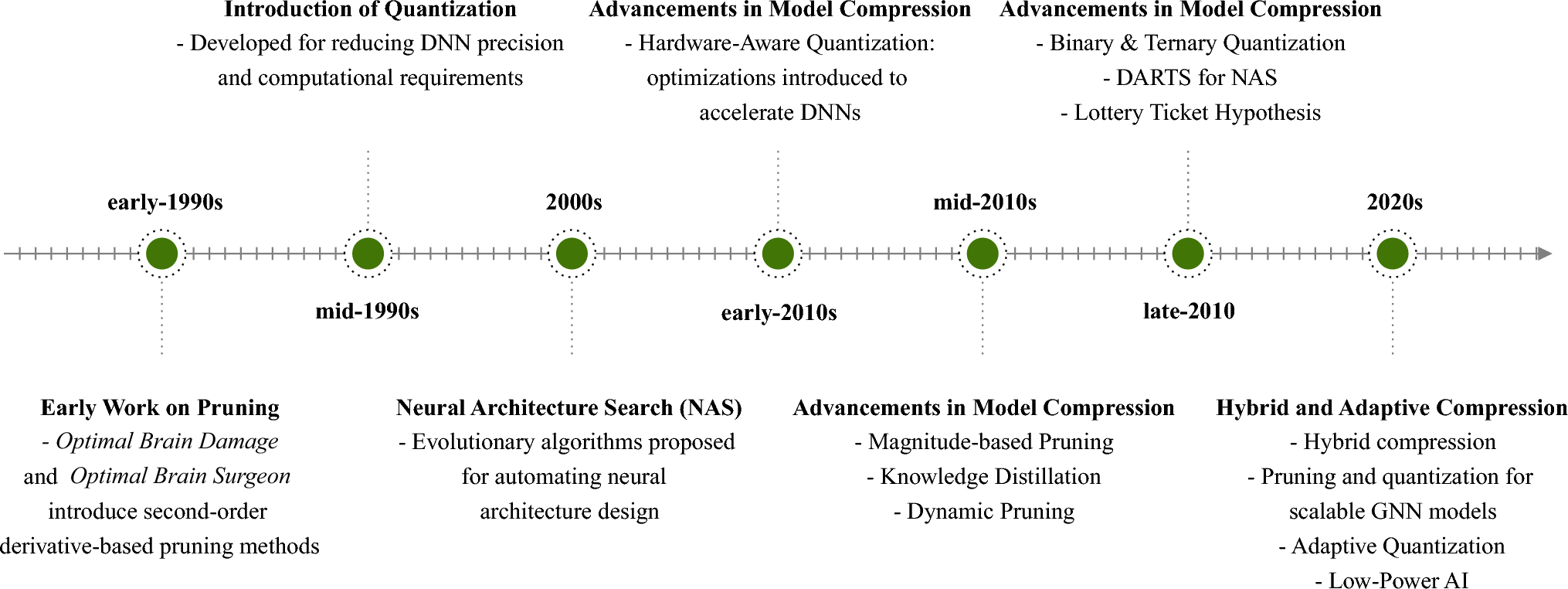
Our latest publication in Complex & Intelligent Systems presents a structured and up-to-date overview of model compression strategies tailored to large language models (LLMs): https://lnkd.in/eZjwgUF6.
This work is particularly valuable for researchers and practitioners aiming to:
- Understand the landscape of compression methods (pruning, quantization, distillation, NAS).
- Explore hardware-aware and fairness-driven design trade-offs.
- Apply a multi-objective evaluation framework (latency, energy, accuracy, robustness).
- Gain insight into hybrid and adaptive approaches for real-world deployment.
- Navigate open challenges and research directions through a detailed roadmap.
Readers looking for practical guidance and theoretical depth will find this review a useful reference point for both academic study and applied development.
Special thanks to my advisor and co-authors, Prof. Waldir Sabino and Prof. Lucas Cordeiro, for their guidance and collaboration throughout this project. Research group and contributors: https://lnkd.in/exKf_wFP
In upcoming work, we will delve into spectral analysis of LLMs, aiming to uncover new compression and interpretability methods rooted in frequency-domain representations.
We also invite you to explore our previous publication on hybrid adaptive compression methods: https://lnkd.in/eyuirZ6R
Follow the Topic
-
Complex & Intelligent Systems
This is an open access journal that focuses on the cross-fertilization of complex systems, computational simulation, and intelligent analytics and visualization.



Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in