Merging of the learning algorithms and the artificial synapses
Published in Electrical & Electronic Engineering

Perspective and issues of neuromorphic computing
Deep learning heavily relies on huge memory and computation resources as well as on the frequent shuttling of the data between the memory unit and computation unit. A promise was made by the neuromorphic computing community that this issue will be addressed by memristive devices arranged in crossbar structure, which memorize the weight parameters and conduct the neural network computation in the location of memory. The computing-in-memory solution leverages the basic physical laws, i.e., Ohm’s law and Kirchhoff's current law.
However, the promise has not been realized, due to multiple reasons.
First, the information flow in the deep neural network should be represented accurately and with high precision. Thus, the peripheral circuits around the crossbar of the memristor need to source accurate voltages on the crossbar and accurately sense the currents from the crossbar. This results in high costs for circuit designers and high energy consumption for the users.
Second, the golden learning algorithm for deep learning is the gradient descent based on error backpropagation, which requires even more accurate backward information flow in the neural network and accurately tunes the weight parameters. The latter means that the conductance of the memristive devices or the artificial synapses should be tuned in high precision.
Third, the memristive devices that exist to date are not good enough. There are many kinds of memristive devices, resistive random-access memory, ferroelectric memory, magnetic random-access memory, phase-change memory, etc. Several issues exist in these devices, such as high stochasticity and fluctuation, low production yield, the limited number of states, non-Ohmic conduction, and non-linear weight update behavior. And, mostly, they are only available in academic labs or commercially on a small-scale. Production lines are straggling to introduce these emerging memory technologies.
Our solutions on the device level
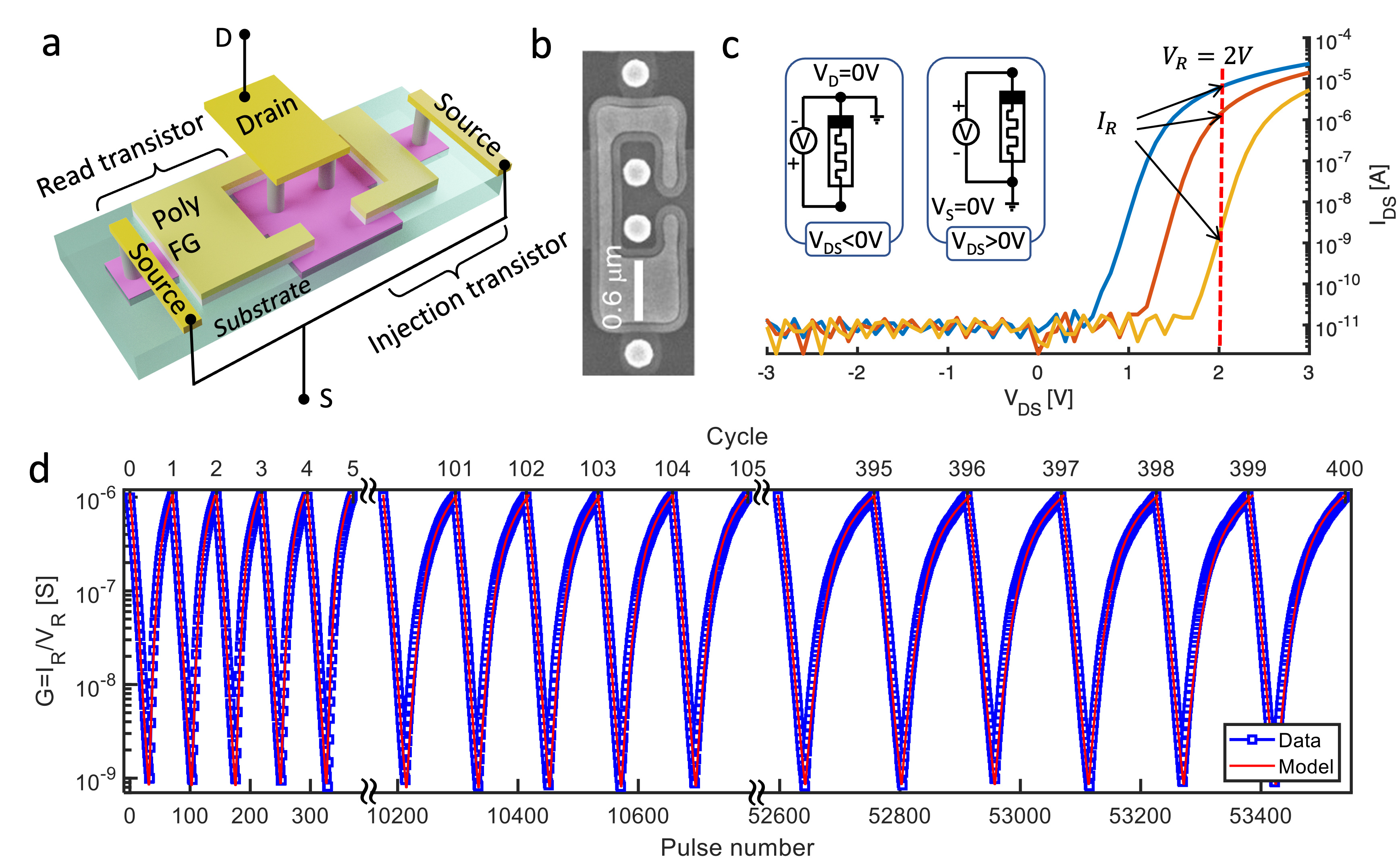
Instead of waiting for the maturity of the emerging memories, in the work we recently published in Nature Electronics, we use the silicon synapses, i.e., two-terminal floating-gate transistors or Y-Flash memories directly from a commercial production line of the silicon industry – a complementary metal-oxide-semiconductor (CMOS) production line.
The silicon synapses have several advantages, such as self-selectivity, analogue conductance tunability, high retention time, small and predictable cycling degradation, and moderate device-to-device variation. But they are not perfect. First, the reading I-V curves are not linear, meaning that it does not follow Ohm’s law for variable voltage. Second, identical pulses do not induce identical conductance changes. In previous work, we developed a full-winged physical and compact model to describe all the electrical behaviors of the device (Applied Physics Letters, 119, 263504, 2021).
In another previous work (Nature Electronics, 2, 596, 2019), we utilize a small-signal technique to circumvent the first issue. The second issue is not a big problem since we only demonstrated neural network applications on small scale.
Our solutions on the learning algorithm level
This time, we are trying to scale up the size of the neural network based on the silicon synapse and attempting to solve the remaining issues from the side of the neural network algorithm.
Without the linear reading I-V, we cannot exploit Ohm’s law for the multiplication with variable input voltage. Instead, if the input voltage is binary, we only need Ohm’s law at a fixed read voltage. We first think of the restricted Boltzmann machine and deep belief network to solve this issue, where all the neurons have binary states.
Surprisingly, after a closer look at the restricted Boltzmann machine and deep belief network, we find more beautiful things. And, with algorithm modifications and novel hardware designs, we make them the perfect platforms to implement a neural network in hardware based on the silicon synapses.
Multiple benefits of our contributions
First, due to the binary states of the neurons, the hardware version of the restricted Boltzmann machine and deep belief network highly relax the peripheral circuits of the crossbar array of the silicon synapses. Specifically, they do not need to apply accurate voltages on the silicon synapses nor to accurately sense the current output from the silicon synapses.
Second, non-linear activation functions, which are necessary for deep neural networks and implemented by dedicated circuits, are not needed in the restricted Boltzmann machine or deep belief network.
Third, the training of the deep belief network is based on greedy learning. That is, we need to train the restricted Boltzmann machine one by one using only local information. Whereas, in a deep neural network, we need to backpropagate the error signal from the last layer to the first layer for the gradient calculation and weight update, which results in the data dependency issue and needs additional cache memory to store the intermediate states of hidden layers during neural network training.
Fourth, the gradient descent rule based on contrastive divergence results in ternary gradient information, either -1, 0, or 1. This allows us to update the neural network weights, i.e., the conductance of the silicon synapses, step-wise. This means that we only need to send identical pulses to potentiate (increase) or depress (decrease) the conductance of the silicon synapses.
Furthermore, to compensate for the non-linear conductance changes under identical pulses and reduce the number of write operations, we use an array of counters to accumulate the gradient information. The write operation on the silicon synapses, by sending identical pulses to update the conductance, is performed only when the accumulated gradients reach thresholds. In earlier work, through extensive simulation, we find that this arrangement makes the neural network training resilient to multiple non-idealities of general artificial synapses (Advanced Intelligent Systems, 4, 2100249, 2022).
In the work we recently published in Nature Electronics, we implemented all the above techniques a hardware system based on silicon synapses, and confirmed all the above conclusions.
We use two arrays of the silicon synapses to demonstrate the in-situ training of a 19-by-8 memristive restricted Boltzmann machine for pattern recognition (Figure 1). We then extend this approach to a memristive deep belief network for the training and recognition of the handwritten digits in the MNIST dataset. The performance of our system (>97% recognition accuracy) is equivalent to software approaches and comparable to mainstream memristive DNNs based on an error backpropagation algorithm, where complex neural behavior (the peripheral circuit of the memristive array) needs to be implemented in software or hardware and in-situ online training is not available.
Follow the Topic
-
Nature Electronics
This journal publishes both fundamental and applied research across all areas of electronics, from the study of novel phenomena and devices, to the design, construction and wider application of electronic circuits.




Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in