RE "Active Restoration of Lost Audio Signals Using Machine Learning and Latent Information"
Published in Electrical & Electronic Engineering, Computational Sciences, and Mathematics
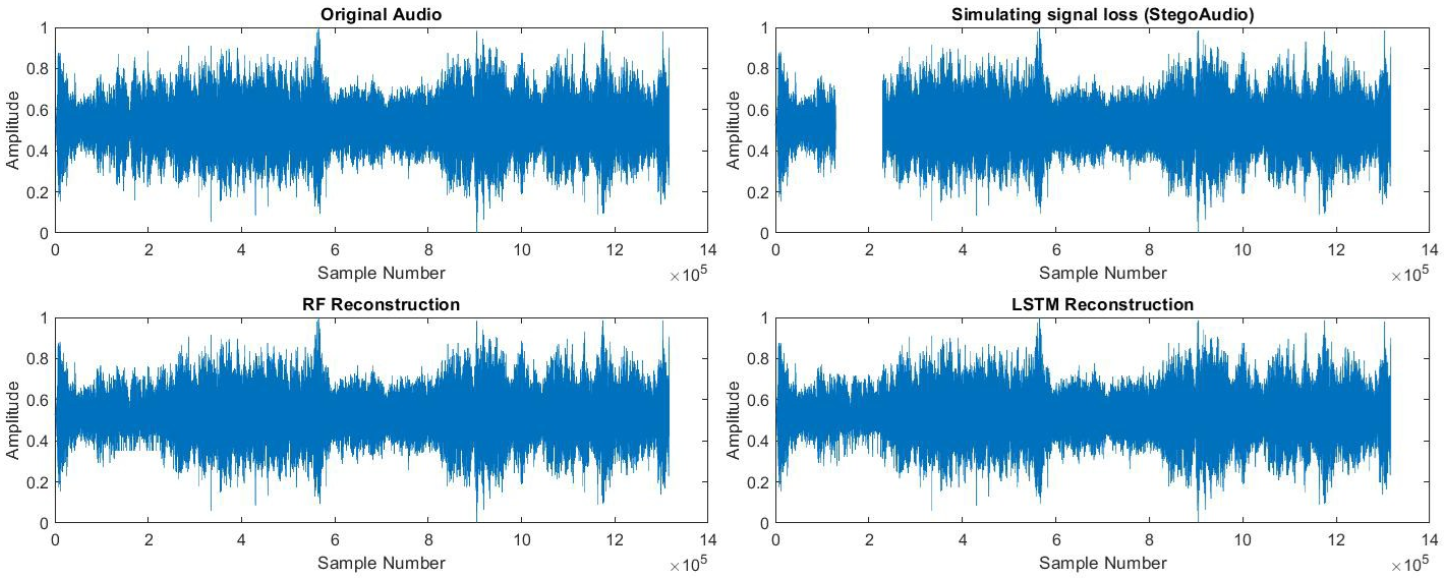


Digital audio signal reconstruction of a lost or corrupt segment using deep learning algorithms has been explored intensively in recent years. Nevertheless, prior traditional methods with linear interpolation, phase coding and tone insertion techniques are still in vogue. However, we found no research work on reconstructing audio signals with the fusion of dithering, steganography, and machine learning regressors. Thus, this paper entitled: "Active Restoration of Lost Audio Signals Using Machine Learning and Latent Information", presents a novel approach to reconstructing lost or corrupted audio segments using a combination of steganography, halftoning (dithering), and machine learning techniques. We propose a framework called HCR (halftone-based compression and reconstruction) that outperforms existing methods in audio signal reconstruction.
Background and Motivation
Traditional audio reconstruction methods often struggle with gaps exceeding half a second, limiting their real-world applicability. We identified a gap in the research, noting that no prior work had explored the fusion of steganography, halftoning, and machine learning for active audio reconstruction. This approach is considered a pre-emptive security measure, allowing for self-healing when parts of an audio file become corrupted.
Proposed Framework
The HCR framework combines several key elements:
- Steganography: This information hiding technique is used to embed compressed latent information within the audio file.
- Halftoning (Dithering): A technique borrowed from image processing, used here for audio compression.
- Machine Learning: Both shallow and deep learning methods are employed to enhance the reconstruction process.
The fusion of these techniques allows for the reconstruction of audio signals using the latent information provided through steganography, which proves to be more effective than traditional passive recovery procedures.
Methodology
We implemented and compared various machine learning models, including:
- Random Forest (RF)
- Support Vector Regression (SVR)
- Long Short-Term Memory (LSTM) networks
These models were trained to estimate the approximate reconstructed signals. The performance of each model was evaluated using four different metrics:
- Pearson linear correlation
- Peak Signal-to-Noise Ratio (PSNR)
- Weighted Peak Signal-to-Noise Ratio (WPSNR)
- Structural Similarity Index Measure (SSIM)
Key Findings
- Performance Improvement: The proposed HCR framework outperformed existing learning-based methods (such as D2WGAN and SG) and traditional statistical algorithms (e.g., SPAIN, TDC, WCP) in terms of signal-to-noise ratio (SNR), objective difference grade (ODG), and Hansen's audio quality metric.
- Effectiveness for Longer Gaps: The approach proved effective for gaps exceeding half a second, making it suitable for real-world scenarios where passive recovery methods typically fail.
- Model Comparison: Among the machine learning models tested, the LSTM model demonstrated superior performance compared to RF and SVR models, particularly in reconstructing lost audio signals for single drop regions on both short and long gaps.
- Drop Region Performance: The reconstruction of audio signals from dropped short single regions was more successful than for multiple regions.
Applications and Implications
- Audio Protection: Beyond its primary purpose of audio recovery, the proposed approach can benefit security systems by protecting audio files from unauthorized manipulation.
- Potential for Extension: The paper suggest that this technique could potentially be extended to other domains, such as image inpainting. The latter is a technique that involves the filling-in of missing data within a designated region of an image. The goal is to reconstruct these areas so that they blend naturally with the surrounding pixels, making the restoration undetectable to a casual observer.
- Real-world Applicability: The ability to handle gaps exceeding half a second makes this method particularly valuable for practical applications where audio corruption or loss is a concern.
Limitations and Future Work
While the proposed framework shows significant improvements over existing methods, there are areas for further research and development:
- Multiple Drop Regions: It is noted that audio reconstruction for multiple drops, especially considering long gaps, needs improvement.
- Exploration of Newer AI Methods: The paper suggests that exploring newer AI methods or optimization techniques could further enhance the quality of reconstructed audio signals.
Conclusion
The paper presents a significant advancement in the field of audio signal reconstruction by introducing a novel framework that combines steganography, halftoning, and machine learning techniques. The HCR approach demonstrates superior performance in reconstructing lost or corrupted audio segments, particularly for gaps exceeding half a second, which has been a limitation of previous methods. The fusion of these techniques not only improves the quality of audio reconstruction but also offers potential applications in audio security and protection against unauthorized manipulation. The proposed approach opens up new avenues for research in active audio reconstruction and may inspire similar approaches in related fields such as image processing. As with any emerging technology, there are areas for improvement and further research, particularly in handling multiple drop regions and exploring more advanced AI methods. Nevertheless, the proposed framework represents an important step forward in addressing the challenges of audio signal reconstruction in real-world scenarios.

Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in
Given the promising results of the HCR framework for single drop regions, have you considered incorporating advanced sequence modeling techniques, such as Transformer architectures, to improve the reconstruction quality for multiple drop regions and longer gaps?
Thank you for your thoughtful response. Indeed, it could be possible for the SOTA Transformers architecture to capture better inferences from noisy and/or incomplete data. Thus, utilizing Transformer decoders for the reconstruction phase in conjunction with the introduced HCR (halftone-based compression and reconstruction) could prove beneficial to generate coherent outputs. However, for applications with limited computational resources, such as mobile apps, LSTM may still be competitive.
In our paper, we have set aside the exploration of these advanced techniques for future work.