Usable electricity usage data for the United States
Published in Research Data


Visualizing your data is a great way to get acquainted with it. When we first plotted the EIA electricity usage data, we saw that many of the values were physically impossible while others were improbable.
Without knowing any details about the electric grid or typical electricity use patterns, I would wager that almost anyone can pick out the extreme outlier data values in the below time series distribution from one of the regions included in the data set.
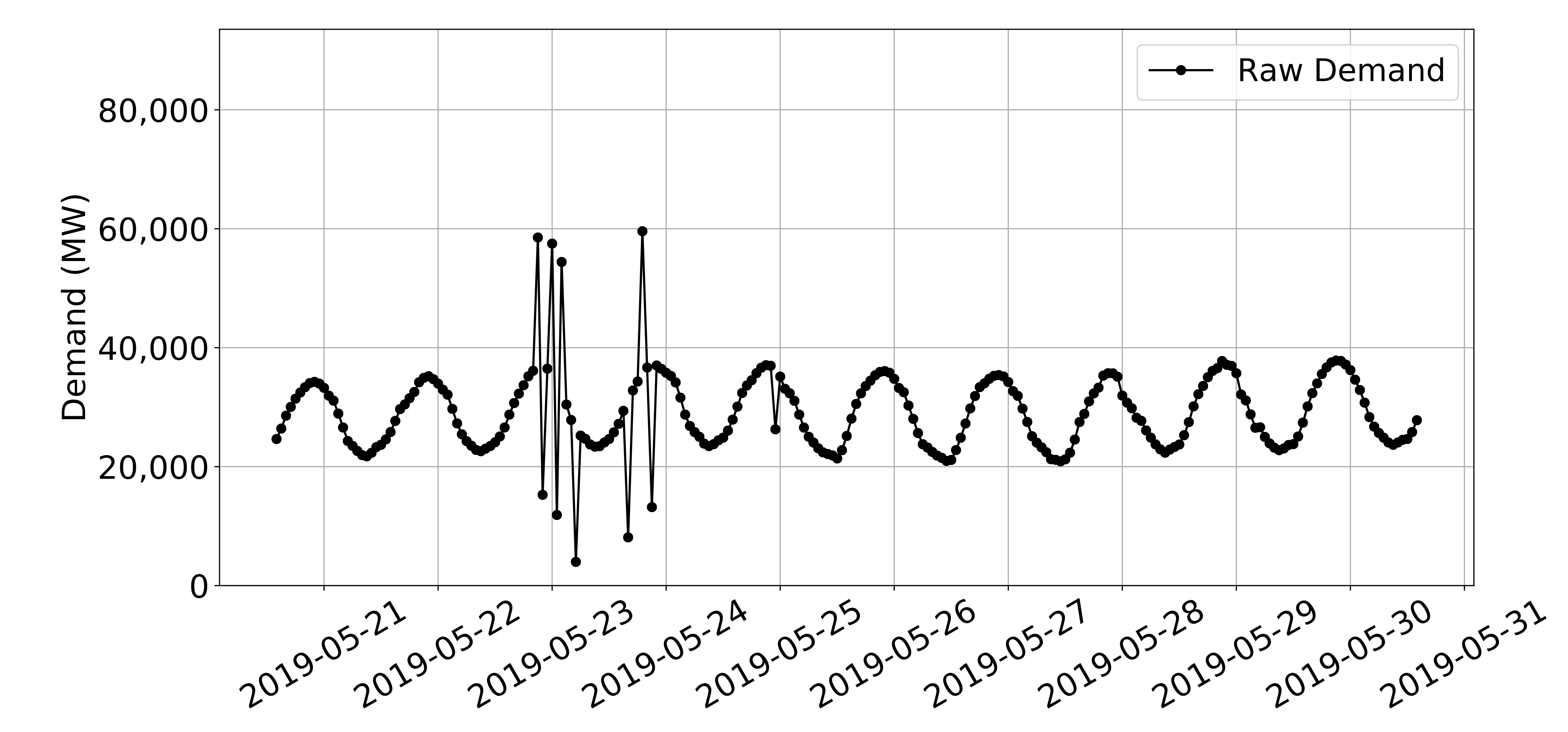
Raw hourly electricity usage from one of the 54 regions included in our data set.
I am part of a group of energy and electricity systems modelers at Carnegie Institution for Science. We model potential future electricity systems with minimal or zero carbon emissions. We use historical electricity usage data to ensure our models can reliably supply electricity demand. Just a handful of extreme outlier values can cause a model to build excessive generation capacity throwing results into question. If the four highest hourly values from the figure above were retained in our analysis, our model would design a power system capable of delivering 60,000 MW of power instead of closer to 40,000 MW based on the “reasonable” looking data.
We cleaned the EIA electricity usage data set to make it usable. We documented our process in Scientific Data and published the cleaned data with an aim to save the rest of the modeling community many hours of labor, and to kindle a discussion about electric utility data quality.
We split the data cleaning process into two steps: 1) develop algorithms to find and remove the impossible and extreme outlier values and 2) replace these removed values and values that were originally missing with imputed replacements.
Humans are incredibly adept at visual pattern recognition and spotting outliers. This is precisely what we relied upon to inspire our filtering algorithms. Visual inspection of our data led us to the extreme outlier values. Then we asked ourselves what characteristics of that outlier made it so obvious? Was it an impossible negative value? Was there an extreme divergence from continuity? Can this outlier be grouped with others based on common characteristics?
We crafted algorithms to remove these groups of outlier values and systematically tuned them to limit any biases the algorithms could introduce into the remaining data. We set thresholds for what degree of divergence would be considered an outlier. It is easy to remove all outliers by filtering out all of your data. The trick is keeping as much good data as possible while removing as many outlier values as possible.
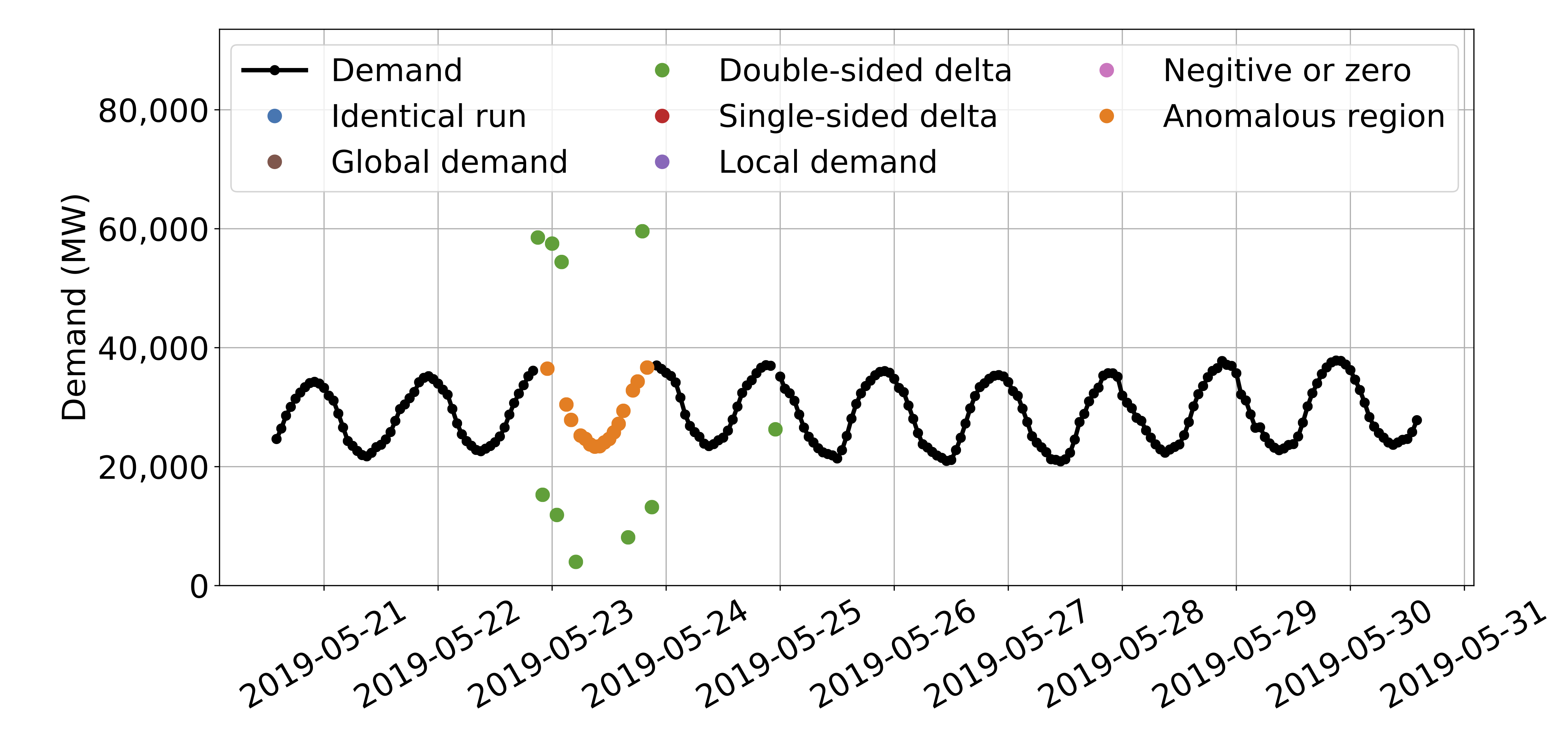
To continue the previous example, our algorithms filtered the highlighted values. The green points indicate a significant deviation from continuity, while the orange points indicate values within a chaotic section of data.
With the outliers removed we focused on calculating reasonable replacement values for them and the 2.2% of values that were originally missing. Data gaps of a few hours can be reasonably filled in with interpolation based on the surrounding good data. However, there were many instances where continuous weeks or months of data needed replacement. Because of these long gaps, we used a Multiple Imputation by Chained Equations (MICE) method for imputation.
At the core of the MICE method is a set of linear regressions that are fit to the data and used to estimate the missing values. The electricity usage data has strong autocorrelation where the values before and after an hour are, in general, quite similar. Additionally, the electricity usage profiles are often similar between geographically similar regions because of similar weather patterns and business schedules. Initially, we parameterized the linear regression estimating the usage in region A at hour t based on the previous (hour t-1) and following (hour t+1) hourly usage in region A and all values occurring at hour t for the other regions. This combination ensures relative continuity in the time series values and leverages information in other regions to help fill in long data gaps.
We tested the model performance by removing good data and imputing their values. Our initial tests showed the imputation model performed well when short, few hour long, data gaps were present. However, for much longer gaps, the imputed values deviated significantly from the actual values. The imputed values were being influenced too strongly by concurrent values in other regions with differing typical usage profiles. We resolved this by adding a climatological variable specific to each region, time of day, and time of year, C(t), to the linear regression. This addition ensured that the typical usage characteristics of region A were incorporated into the prediction of long data gaps in region A.
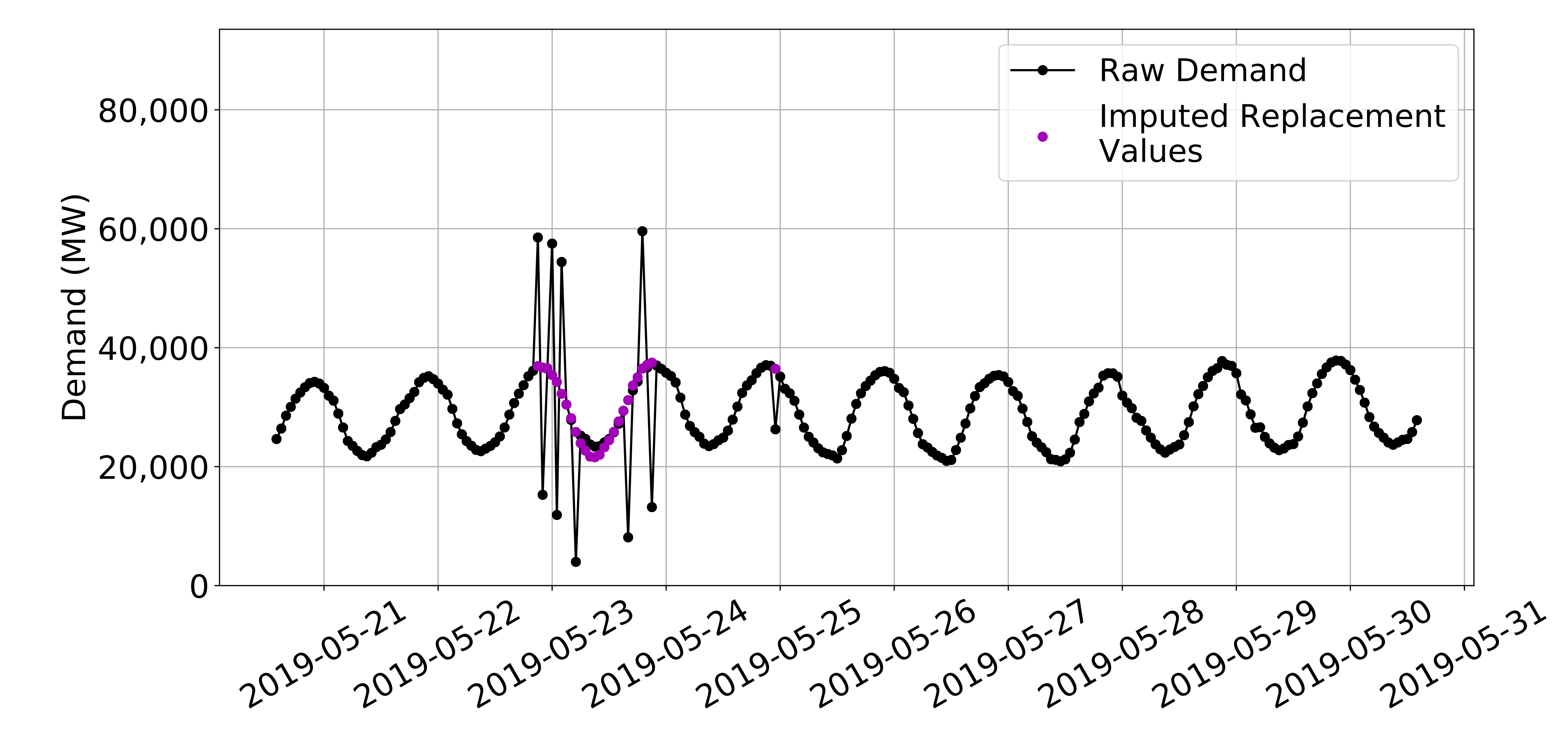
Continuing the previous example, our imputation algorithm replaces the filtered values (not highlighted here) with the magenta values.
By filtering and replacing these values we have attempted to achieve a more realistic electricity usage profile. As this data set grows, we aim to extend this cleaned data product every year for our group and the community to use. We hope this data product is as useful to others as it has been for us.
With a clean and more complete data record for electricity use in the U.S., it may be easier to understand past usage and to project the effects of changing energy sources into the future.
Follow the Topic
-
Scientific Data

A peer-reviewed, open-access journal for descriptions of datasets, and research that advances the sharing and reuse of scientific data.
Related Collections
With Collections, you can get published faster and increase your visibility.
Data for crop management
Publishing Model: Open Access
Deadline: Apr 17, 2026
Data to support drug discovery
Publishing Model: Open Access
Deadline: Apr 22, 2026




Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in