Automated Extraction of Chemical Synthesis Actions from Experimental Procedures
Published in Chemistry

In the past few years, the Future of Computing team at IBM Research Europe developed machine learning models to assist organic chemists. We made the technology available worldwide through the "RXN for Chemistry" portal, catalyzing the growth of a vivid community of more than 14,000 users who generated more than 700,000 machine learning predictions of chemical reactions in two years. The RXN for Chemistry platform provides pre-trained models to predict the products of chemical reactions [1] and suggest retrosynthetic pathways [2].
As a next step, we explored the possibility to enable the machine learning algorithms to design and drive chemical reactions in a real laboratory with what we call RoboRXN. Its implementation entails learning how reactions are executed in the lab, e.g., the series of experimental actions needed for a chemical reaction to succeed, all the way from mixing compounds in a flask to the work-up of the product. So far, no database contains such information in an adequate format. Luckily, the chemical literature holds more than enough information about executing reactions: millions of experimental procedures are available in journal articles and in patents. However, they are reported in prose, which hampers a straightforward analysis and interpretation. Therefore, we took on the challenge of designing an algorithm to extract this information and provide it in a structured and automation-friendly format, as illustrated in the following table.
| Experimental procedure sentence | Associated actions |
| Then water was added and the mixture was extracted with EA three times, the combined organic layers were washed with brine and dried (anhydrous Na2SO4). |
|
| 18.1 ml (18 mmol) of a 1-molar solution of boron tribromide in dichloromethane were added to a solution of 3.37 g (9 mmol) of 4-chloro-3-(2,3-dichloro-4-methoxybenzyl)-5-difluoromethoxy-1-methyl-1H-pyrazole in 45 ml of dichloromethane which had been cooled to (−78)° C. |
|
| The resulting slurry was stirred for 30 minutes at 25° C. and the pH was adjusted to pH=9 by addition of 6M NaOH (0.135 L). |
|
In order to implement a computational approach to extract actions as illustrated in the table above, we first turned our attention to so-called rule-based models. They use rules to analyze sentences and the relationships between their components to determine compounds, operations, or reaction conditions. We soon realized that this approach was not flexible and powerful enough to reach our goals: when sentences are complex and their meaning highly context-dependent, it is not practicable anymore to specify robust rules to fully capture the sense of sentences unambiguously.
Instead, we chose a purely data-driven approach: after seeing enough examples, a machine learning algorithm will be able to figure out on its own what words to pay attention to in order to extract sensible experimental steps. The major advantage of such a data-driven approach is that it relies only on data - in order to improve it, one simply needs more examples.
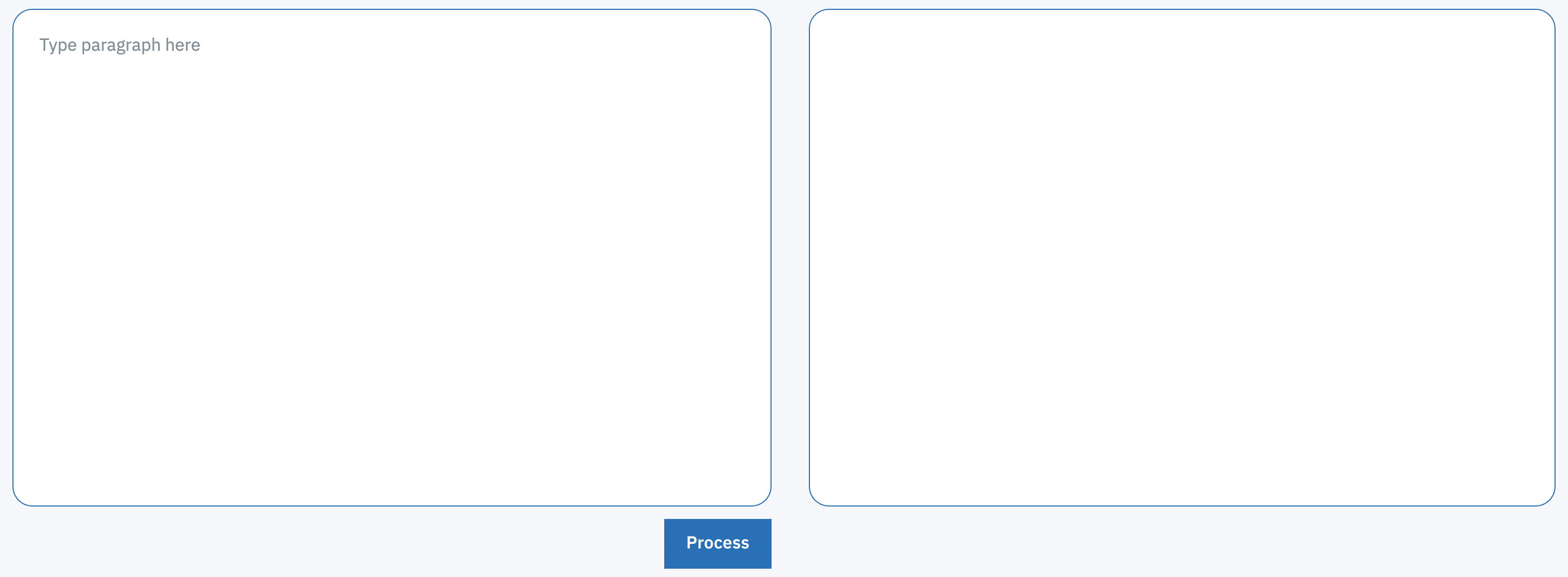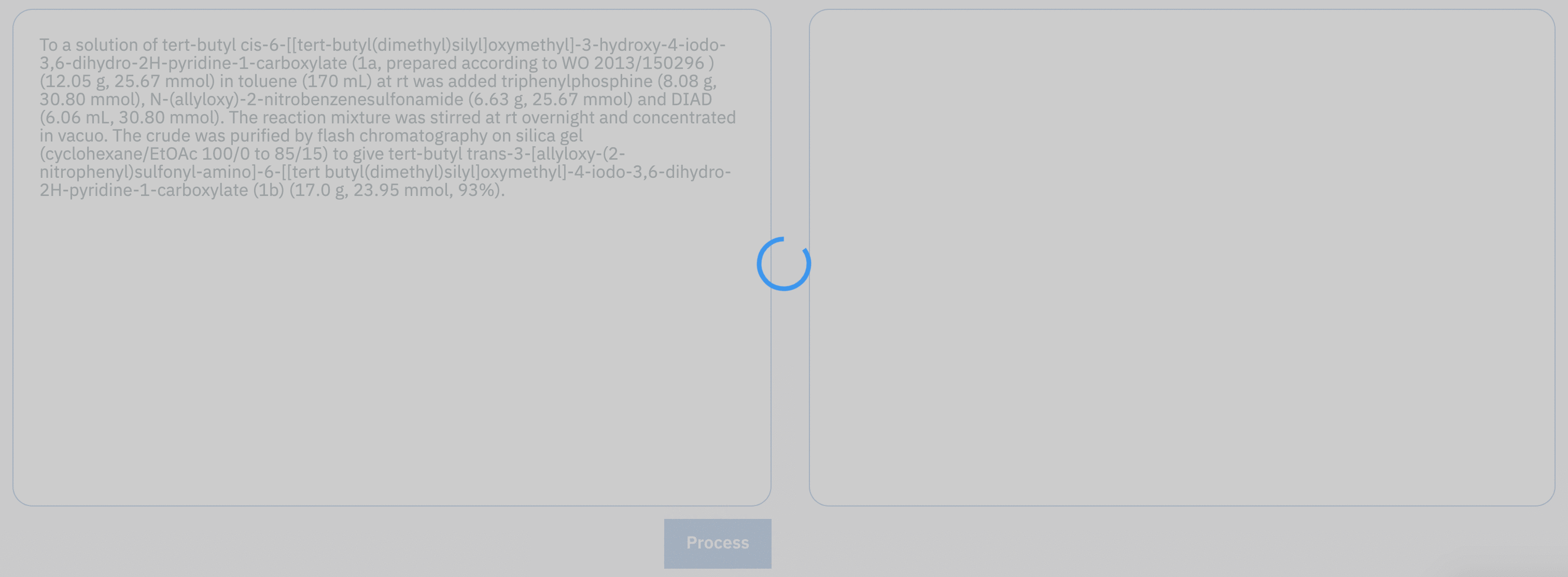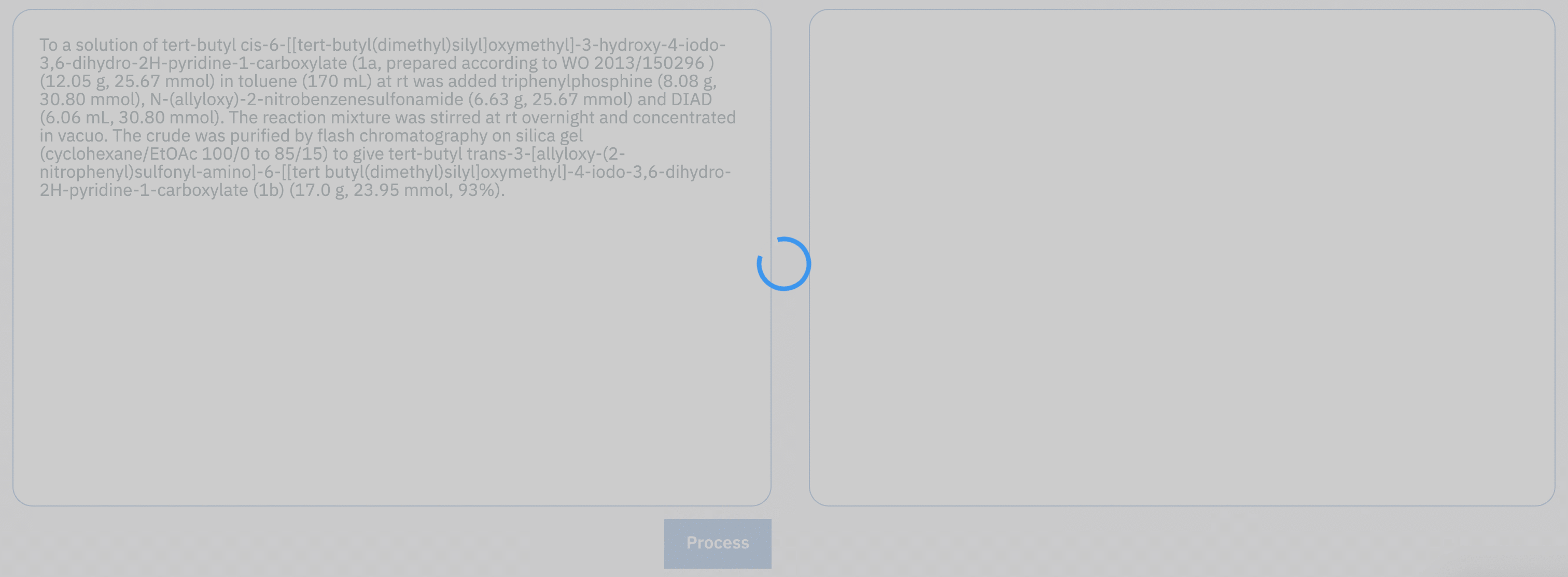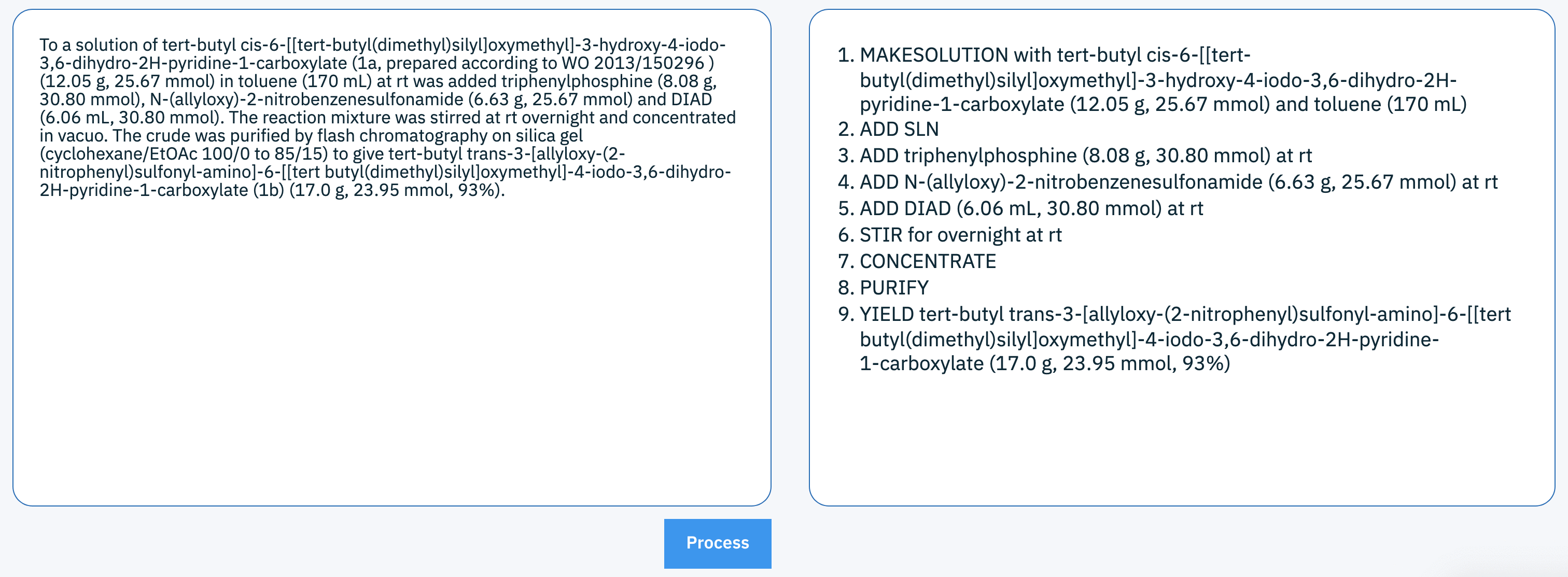
To provide the training data for the machine-learning model, we set up an annotation framework that enabled us to generate examples of experimental procedure sentences and corresponding operations.

In this way, we generated more than 1700 pairs of sentences and associated action sequences. Although substantial, this number is too small to train a reliable machine-learning model from the ground up. Nevertheless, we figured that the rule-based model that we had been studying earlier would be able to provide millions of examples at virtually no cost, albeit of lower quality. By pre-training the machine-learning model on that inexpensive data first, we could refine it on the manually annotated samples to obtain a satisfactory accuracy. The model can be used for free on our online platform:
What still amazes me is the ability of the model to learn a structured syntax on its own. No need to tell it beforehand what action types are allowed and what set of properties is associated with each of them!
We presented this approach in an article published in Nature Communications, available here. Since then, the model for extracting actions from experimental procedures has paved the way to the implementation of RoboRXN. For instance, we used a large corpus of chemical procedures extracted from millions of experimental protocols to train a machine learning model to predict the experimental steps for new chemical reactions. Having assimilated the knowledge corresponding to decades of bench experience, this new model will act as the brain of the synthesis robot. More to come soon!
Follow the Topic
-
Nature Communications
An open access, multidisciplinary journal dedicated to publishing high-quality research in all areas of the biological, health, physical, chemical and Earth sciences.

Related Collections
With Collections, you can get published faster and increase your visibility.
Women's Health
Publishing Model: Hybrid
Deadline: Ongoing
Tumor Microenvironment Crosstalk and Therapeutic Implications
Publishing Model: Hybrid
Deadline: Nov 02, 2026

Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in
Congratulation, Alain for your good work! I am happy for your success.