Behind "Substitution"
Published in Social Sciences

Please find our recent study on substitution through the link: https://www.nature.com/articles/s41562-019-0638-y
When I mention this work to friends, the first question I’m asked is why I’ve made substitution the primary focus of this research. There’s even a little confusion sometimes. “A six-year-long project about substitution? Why substitution?” And, honestly, when we launched the project in 2013, I would have never imagined that "people's behaviour of replacing one item for another" would ultimately become the main topic of our paper. In fact, it would be two years later when we even started to use the term in our conversations.
Our goal in the beginning was simple: to gain further insight of the topic “diffusion of innovations” by using a large-scale cellphone dataset (D1 in our paper, thanks to Johannes and Geoffrey). Working intensively over two years, we discovered several new macroscopic properties about the adoption behvaiour in the system. We even obtained an entire modeling framework (thanks to Chaoming and Dashun) which could accurately capture various complex phenomena in the dataset. This was exciting, and as a junior PhD student, I felt that we had already gathered enough raw material for a paper, although the mechanisms behind the model were not yet clear.
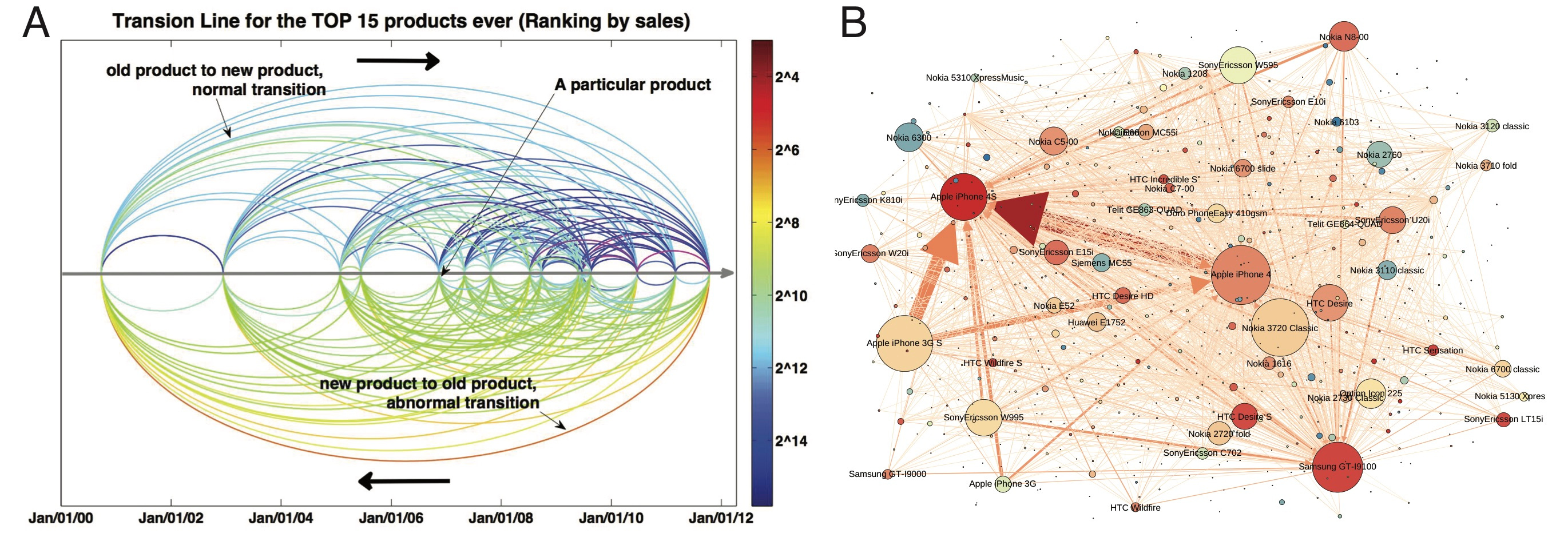
Fig. 1. (A) The first version of network visualization, the “egg plot”. (B) An early version of the network visualization.
“I’ll just wrap everything up and complete the project,” I told myself. But when I suggested as much to Dashun, my advisor, he wasn’t quite convinced. Instead, he encouraged me to think deeply: There was more we were able to explore with the help of our high-resolution dataset, especially when it came to the mechanisms behind the model. “On the individual level, it’s not simply about adopting new phones, it’s also about replacing old ones,” he said. “Can we link these two behaviours and quantify that entire process? I guess you’d call it…substitution?” "Substitution!" I said, "That's a great word!"
This was the first time we had a name for the process. Of course, neither of us realized that “substitution” would become the most frequently used word in our conversations for the next four years.

Fig. 2. A random selected version of the network visualization.
Back then, though, the concept was still sort of fuzzy. To try to pin it down, I drew a sketch based on the transition data from 15 handsets (Fig. 1A, which we also called the “egg plot”). As I see it today, it’s a rather naive and simple plot, but it helped us identify some trends in the data that we hadn’t focused on before. When we showed the figure to Chaoming, we were surprised to realize that he, too, had been thinking about the substitution process as it related to the data. He even proposed several potential mechanisms for the process, some of which proved to be impressively accurate when I tested them in the real data later. As the new substitution mechanisms (preferential attachment, recency, and propensity) were sequentially discovered, we began to incorporate them into our visualizations (I picked a couple of them in Fig. 1B and Fig. 2), which leads to the final network in our paper (Fig. 3, here we especially want to thank Prof. A-L. Barabási, from whom we got several valuable comments and great inspirations during this process). The discovered mechanisms not only push the "substitution" of the "network visualization", but also provide a link between individual-level behaviours and the macroscopic framework we built years ago, highlighting a unique early growth pattern of impact dynamics in the studied system that follows a power law.
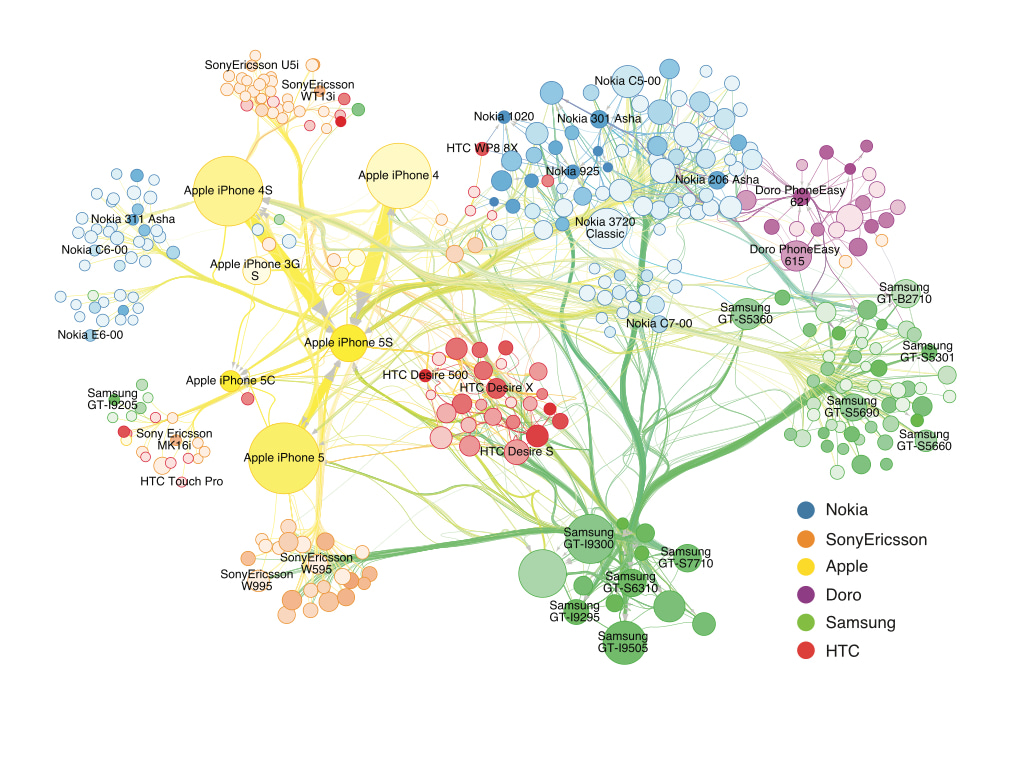
Fig. 3. The final version of the network visualization.
We now had a way of understanding substitution dynamics in the cellphone data. But our conversations led us to question the broader implications of our findings. “If the power law early growth pattern is indeed the fingerprint for substitution, then we should find it in other substitution systems as well,” Dashun and Chaoming said. “We need to test this.”
It turns out to be extremely difficult to find substitution datasets—searching for them took another year. Finally, we located two datasets with fine resolution, which became the automobile dataset (D2) and the smartphone dataset (D3) discussed in our paper. About a year later, we came across an additional dataset that focused on substitution in scientific fields (D4). We tested the early growth patterns in these datasets, finding that the growth of a substantial fraction of products indeed follows a power law, supporting our original model. These results gave us more confidence about our modeling framework. Instead of vague patterns in a single dataset—which I’d so naively deemed publishable years before—we now had identified strong substitution patterns in a variety of realms.
That, in a nut-shell, is the story of this six-year-long project. Much has changed—or should I say “been substituted” ?—during these six years. We swapped a focus on adoption for a focus on substitution. We grew the research, exchanging a single system for four. We even developed better ways to visualize the data, trading our original egg plot for a cellphone map. But "behind" these substitutions, an essential aspect of the project has remained unchanged. The spirit of this endeavor, instilled from the beginning by my advisors and collaborators: Be curious, think deeply and broadly, exchange old lenses for new ones to push the research further. Hone, refine and upgrade our methods.
In other words, let the concept of substitution take over.
Follow the Topic
-
Nature Human Behaviour
Drawing from a broad spectrum of social, biological, health, and physical science disciplines, this journal publishes research of outstanding significance into any aspect of individual or collective human behaviour.

Related Collections
With Collections, you can get published faster and increase your visibility.
Digital Media and Mental Health
Publishing Model: Hybrid
Deadline: Oct 30, 2026
Basic Psychological Needs and Well-Being
Publishing Model: Hybrid
Deadline: Nov 27, 2026



Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in
Great story. Thanks for sharing. Substitution of products and sublimation of life!
Hey Chao, Thanks a lot for your kind words!