Behind the paper “A comparison between Machine and Deep Learning Models on high stationarity data”
Published in Mathematics and Statistics
Time series forecasting is one of the most critical aspects of big data analytics. However, conventional time series forecasting models cannot effectively identify appropriate sequence features, often leading to a lack of forecast accuracy. A crucial concept is stationarity, which indicates that a series' behavior remains constant over time despite variations. Stationary series have a well-understood theory and are fundamental to studying time series, although many non-stationary ones are related.
In this paper, we will investigate some stationarity time series features deeply, considering endogenous mathematical aspects that arose from observations related to a class of big data. We will show that implementing Machine Learning (ML) algorithms, like eXtreme Gradient Boosting (XGBoost), will be more effective regarding a more robust model, as Long Short-Term Memory (LSTM) is usually determined with this issue.
Many authors have preferred to resort to dataset manipulations to eliminate stationarity, for example, by applying restrictions (where possible) or working with decompositions of the latter to obtain higher accuracy values of Deep Learning (DL) models. However, models characterized by a lower complexity are more accurate in the prediction phase than competitors in this type of time series.
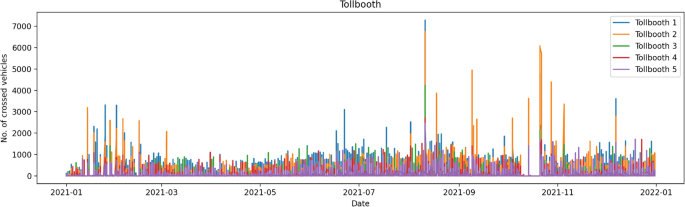
The prediction tests between ML and DL algorithms were carried out on a dataset relating to the number of vehicles passing through 5 Italian tollbooths on different days. Sequential numbering indicates the “interest” for each of them, linked, for example, to geographical factors. In this sense, Tollbooth 1 is of greater interest than Tollbooth 5 and is the subject of the prediction task. Specifically, the dataset used represents a restriction of the originally collected data, which included a series of additional variables linked to climatic conditions and extended over a longer period. These data show how the different time series are characterized by stationarity, in which many hours are characterized by the passage of no vehicles, especially at night, followed by hours of heavy traffic.
We have tested the predictive capabilities of SVM, Random Forest, XGBoost, and RNN-LSTM on the Tollbooth 1 feature. After searching for the best combination of hyperparameters, the algorithm that outperforms the competitors was found to be XGBoost, as evident in Figure 1 on a 200-hour vehicle flow prediction.
Specifically, even graphically, the prediction with LSTM tends to be less stationary and smoother while maintaining the prediction around a trend. At the same time, XGBoost optimally adapts the detrended predicted series to the original one, which is the best choice for a prediction with this type of time series. A similar behavior is adopted by Random Forest (which still uses Decision Trees) but achieves lower performance than XGBoost.
https://www.nature.com/articles/s41598-024-70341-6/figures/1
https://www.nature.com/articles/s41598-024-70341-6/figures/2
https://www.nature.com/articles/s41598-024-70341-6/figures/3
On the explainability side, the SHAP framework allowed us to study which features were the most important in influencing the prediction of Tollbooth 1 with the XGBoost algorithm. Considering Tollbooth 1 as the target feature, as shown in Figure 2, the most important feature that affects the prediction is Tollbooth 3 linked to the highest Shapley value, followed by Tollbooth 4. The distribution can explain this relationship over time of vehicles that passed through Tollbooths 2 to 5. Assuming that Tollbooth 1 is the most significant interest to travelers and absorbs the greatest number of vehicles that pass through at different times of the day, various types of users use the remaining toll booths. In this case, Tollbooth 3 has a distribution of vehicles very similar to Tollbooth 1 at different times of the day, albeit with a much smaller number of vehicles, which is why it is the feature that most influences the model. Instead, Tollbooth 2, despite having a very high average number of vehicles passed through, has a different temporal distribution, which makes it a feature characterized by minimal importance and almost on par with Tollbooth 5. The summary plot, however, illustrates different Shapley values as the instances vary, considering the increase in feature values depending on the color intensity of each point. Although not the most important, the Tollbooth 2 feature reaches higher values (regarding vehicles passed through), pushing towards an increase in the Shapley value.
https://www.nature.com/articles/s41598-024-70341-6/figures/4
Biographical notes
Massimiliano Ferrara was born in Pisa on June 8, 1972. Married and One children. He holds a master’s degree in Economics (MSc) cum laude (1995) and a PhD cum laude both from University of Messina (2001) and two post-master’s studies cum laude from University of Naples Federico II (on Mathematical Economics - 1998) and Scuola Normale Superiore - Pisa (on Mathematical Finance - 2001)
Academic Career
Full Professor of “Mathematical Economics” and “Business Analytics” at“Mediterranea” University of Reggio Calabria (since 2016), where he was PhD School Coordinator, Vice Rector to strategic planning, development and general affairs, Member of the Academic Senate and Chairman Department of Law, Economics and Human Sciences. He was in time Researcher and Assistant Professor in Mathematical Economics, Mathematical Finance and Risk Theory from 2000 to 2002 at University of Messina, Associate Professor from 2002 to 2007 at University of Messina and successively from 2007 to 2016 at University Mediterranea.
Professional Activities
Research Affiliate at ICRIOS – "The Invernizzi Center for Research on Innovation, Organization,Strategy and Entrepreneurship", Bocconi University since 2013 and President of Scientific Committee of MEDAlics Research Centre - University "Dante Alighieri" of Reggio Calabria and Scientific Director ofDecisions_LAB at University Mediterranea. He served as President of Research Institute named "IRITMED" - Istituto di Ricerca per l'Innovazione e la Tecnologia nel Mediterraneo" (2014-2019), General Counsel of Fondazione Banco di Napoli (2013-2015), Vice Rector at University for foreigners “Dante Alighieri” of Reggio Calabria(2009-2010) and Director (Head) of Department of Culture, University and Research of Calabria Region, Italy(2010-2013). Member of the AMASES Scientific Committee for the lapse time (2017-2022 and 2024-current). Member of Evaluation Board at “Politecnico di Torino” (2022).
International Research Experiences
Visiting Professor at Advanced Computing Lab - Faculty of Engineering and Natural Sciences - Istanbul OKAN University (Turkey). He was in time Visiting Professor at Harvard University, Cambridge (USA), Western Michigan University (USA), Morgan State University, Baltimora (USA), Northeastern University di Boston (USA)and Center for Dynamics of Dresden University of Technology (Germany). Member of Sigma Xi and of the Indian Academy of Mathematics, Indore.
Research Interests
Mathematical Economics, Game Theory, Machine and Deep Learning applications, Explainable Artificial Intelligence, Business Analytics, Epidemic Modeling, Optimization Theory, Nonlinear Analysis, Dynamical Systems
Follow the Topic
-
Scientific Reports
An open access journal publishing original research from across all areas of the natural sciences, psychology, medicine and engineering.

Related Collections
With Collections, you can get published faster and increase your visibility.
Phytochemicals and health
Publishing Model: Open Access
Deadline: Jul 28, 2026
Health Policy and Systems Research
Publishing Model: Hybrid
Deadline: Jul 14, 2026




Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in
We want to acknowledge the University of Aosta Valley, in particular the Department of Economics and Political Sciences by the CT-TEM UNIVDA - Centro Transfrontaliero sul Turismo e l’Economia di Montagna and their Director. Prof. Marco Alderighi for their support through the MONTUR Project. A part of Data testing was developed by using “Real Time Series” extrapolated by the mentioned project and will be adopted as the basis for future work. The present work defines the crucial and pivotal structural elements of the Decision Support Systems will be developed into the MONTUR Project. The Authors thank equally the Decisions LAB - Department of Law, Economics and Human Sciences - University Mediterranea of Reggio Calabria for its support to the present research. Funded by European Union- Next Generation EU, Component M4C2, Investment 1.1., Progetti di Ricerca di Rilevante Interesse Nazionale (PRIN) - Notice 1409, 14/09/2022- BANDO PRIN 2022 PNRR. Project title: “Climate risk and uncertainty: environmental sustainability and asset pricing”. Project code “P20225MJW8”, CUP: E53D23016470001.