Behind the Paper: Deploying Decision-Aware Machine Learning for Real-World Health Systems
Published in Computational Sciences, Public Health, and Economics
Recent advances in machine learning have enormous potential to improve healthcare. However, many health systems—especially in the resource-constrained countries that stand to benefit the most from machine learning—lack the infrastructure that has enabled wealthier countries to innovate with them. But does that mean less-resourced nations cannot benefit from these advances at all? As researchers, we wanted to turn the obstacles low- and middle-income countries face into research questions and develop a practical way to democratize what machine learning can offer.
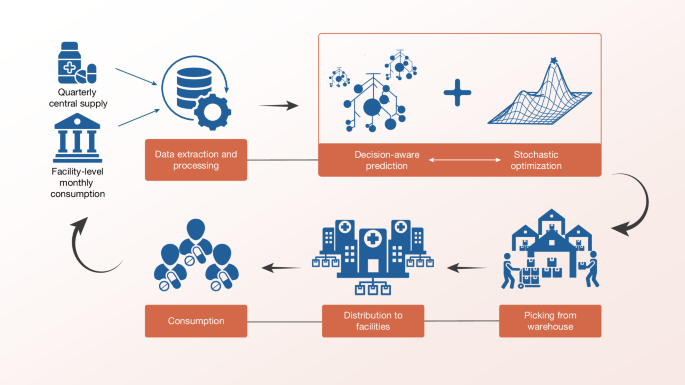
Our research addresses a perennial topic in operations management: how can healthcare providers allocate limited essential medicines to better match patient demand? In Sierra Leone—our study context—supply is limited, demand is highly volatile, and reliable data are scarce, as is common in many developing countries. Existing approaches to optimizing medicine allocation fall short in the face of these challenges. Countries like Sierra Leone need an end-to-end system that can use their limited data to forecast demand and optimize allocation decisions.
To address the data quality challenge, we leveraged multi-task learning to share data across facilities and products. Compared to the standard strategy of predicting demand for each facility and product in isolation, multi-task learning enables the model to discover patterns in regions with comparatively high-quality data and apply them to regions with very low-quality data. However, this approach raised a policy-level concern about equity. Lower-quality data often comes from the most resource-constrained regions where getting the allocation right mattered most, yet these regions may exhibit different patterns compared to wealthier ones. To ensure equity, we incorporated catalytic priors, which gives the model a stable, population-based prior in regions with low-quality data.
These components improved demand prediction, but a good forecast alone is not enough—the forecast must lead to better allocation decisions. The stakes are high since resource-constrained systems have far less capacity to absorb the cost of waste and mismatch than wealthier ones. We designed a novel “decision-aware learning” algorithm to address this challenge—our learning algorithm prioritizes the downstream goal of improving actual allocations instead of purely minimizing forecasting error.
However, designing this forecasting and allocation system was only the first step. The more challenging part was deploying our system. We needed to develop a technically sound system that fit into existing government workflows, produced outputs that planners would actually use, and operated as a decision support tool rather than replacing human judgment. The most pressing questions went beyond statistics: which data could be trusted, which objectives matched policy priorities, what format made recommendations usable, and what kind of system could be sustainably used.
Answering these questions required setting aside our laptops and immersing ourselves in local communities. I traveled to Sierra Leone, where I learned from policymakers and frontline workers who understood the culture, operations, and policies far better than my research team and I. Our local partners showed us key bottlenecks, explained which constraints were truly binding, and suggested what would make a tool credible. We also came to understand their concerns about job displacement—how our optimization system, if poorly framed, could feel like a threat rather than a source of support.
Some of the most consequential lessons came from field visits that upended our prior assumptions. When we were starting out, we wondered whether it was more important to prioritize rural clinics or to prevent larger facilities from stockouts. Visiting these facilities and observing care-seeking behavior firsthand provided valuable insight: small clinics were often unreliable or closed entirely, forcing patients to travel to larger facilities in times of critical need.
Our field experiences and the feedback we received from local stakeholders were instrumental in shaping the design of our system. Rather than a story of academics introducing solutions from the outside, this involved a process of mutual learning and trust-building to implement something new and effective in an entrenched public system.
Looking forward, we hope this work can inspire more researchers to view local constraints and objectives not as reasons to step away but as invitations to solve challenging problems. If machine learning and AI are to transform healthcare for the better, it should not be built only for places where data are abundant and implementation is smooth—the places with the least resources and the most intractable problems may have the most to teach us.
Read our paper here: https://www.nature.com/articles/s41586-026-10433-7
Follow the Topic
-
Nature
A weekly international journal publishing the finest peer-reviewed research in all fields of science and technology on the basis of its originality, importance, interdisciplinary interest, timeliness, accessibility, elegance and surprising conclusions.

Related Collections
With Collections, you can get published faster and increase your visibility.
Carbon Dioxide Removal
Publishing Model: Hybrid
Deadline: Jan 16, 2027



Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in