Behind the paper: Development of a differential treatment selection model for depression on consolidated and transformed clinical trial datasets
Published in Computational Sciences and General & Internal Medicine
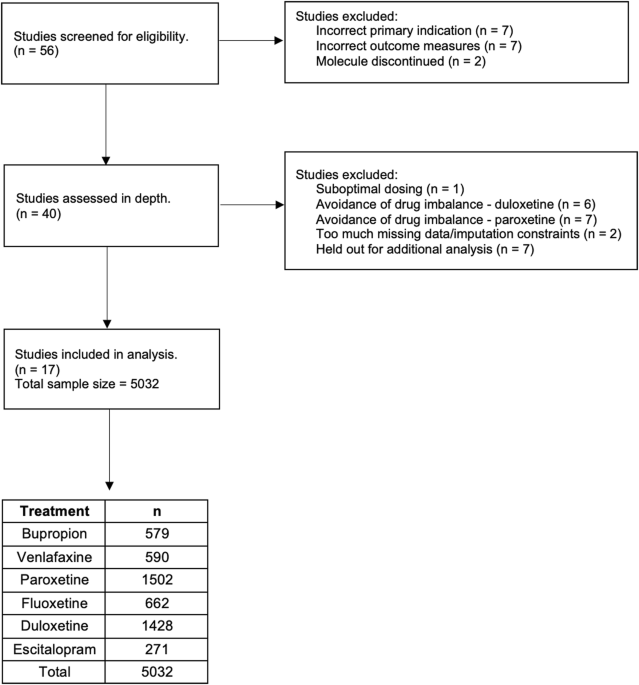
In this paper, we demonstrate the ability to harness machine learning to predict remission rates across 6 different antidepressant treatments. Previous work is focused on overall outcomes across treatments or outcomes between 2 drugs, but in this study we show that we can predict differential treatment benefit across multiple first line treatments for depression. This is highly clinically relevant, since patients and clinicians have over 20 treatment options to choose from, and being able to choose among many options is essential.
Importantly, this analysis was only made possible through our harmonized method of transforming and merging different clinical trial datasets. Previously, we have been limited in our ability to consider datasets from different trials together because they often use different standard questionnaires to collect clinical measures, thus prohibiting the merging of multiple trials. However, with our generalizable method (see figure below), data across disparate trials can be combined and prepared to be used in a machine learning model.
")
This process involves organization of variables using a custom taxonomy, categorical and binary data transformations, and various quality checks, such that a set of transformed features (consisting of merged variables across studies probing the same clinical dimension or sociodemographic factor) can be fed into a machine learning algorithm which performs feature selection. This algorithm selected a list of 21 transformed features which were the most predictive of differential treatment benefit. Many of these features were consistent with previous literature, and knowing what predicts outcome in depression opens new potential research avenues.
Follow the Topic
-
Translational Psychiatry
This journal focuses on papers that directly study psychiatric disorders and bring new discovery into clinical practice.

Related Collections
With Collections, you can get published faster and increase your visibility.
Moving towards mechanism, causality and novel therapeutic interventions in translational psychiatry: focus on the microbiome-gut-brain axis
Publishing Model: Open Access
Deadline: Nov 15, 2026



Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in