Building a Modern Data Platform for the Artificial Intelligence Era
Published in Computational Sciences, Mathematical & Computational Engineering Applications, and Statistics


Artificial Intelligence without data is just Artificially! Having all those recent AI breakthroughs without proper data management would be impossible. Since across various domains, data is the first gate to all data-driven activities, such as Artificial Intelligence, Machine Learning, and Business Intelligence. Effectively managing data to support AI was the main goal of the paper “Building a modern data platform based on the data lakehouse architecture and cloud-native ecosystem”, published on 22 February 2025 (just after the Love Data Week 2025, isn’t it lovely?)
Paper Highlights
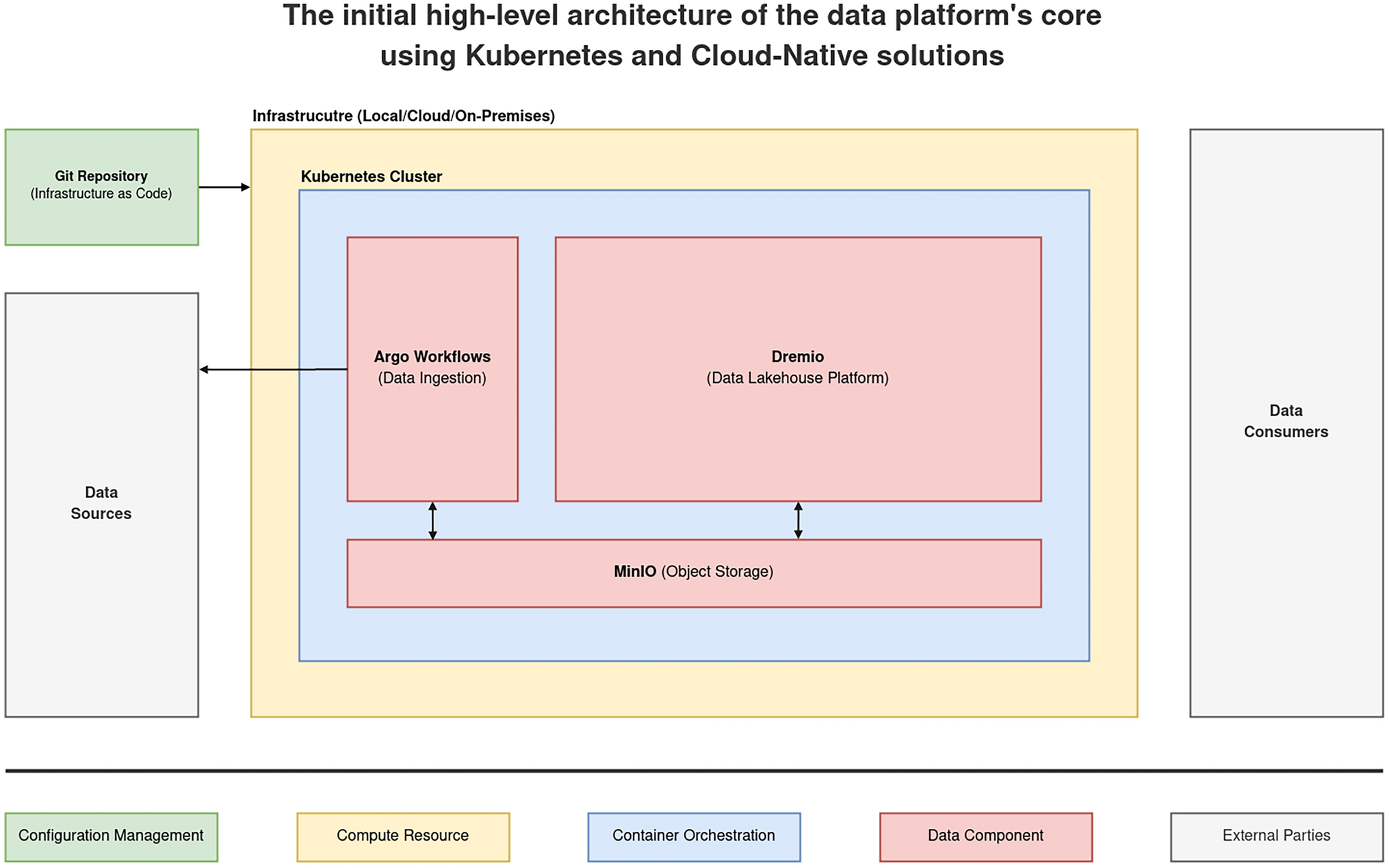
- The research creates a blueprint using DataOps, Kubernetes, and a Cloud-Native ecosystem to build a resilient Big Data platform following the Data Lakehouse architecture, providing the base for Machine Learning and Artificial Intelligence.
- Using an iterative approach, we architectured and implemented the core of the platform, which is composable and cloud-agnostic. This avoids vendor lock-in and enables seamless deployment across environments from any Cloud provider or on-premises.
- The initial benchmarking showed that the platform could efficiently handle massive amounts of records, benefitting from Apache Iceberg format features.
Personal Background
This paper is based on my dissertation for the Master of Science degree in Data Engineering at Edinburgh Napier University, which was a unique learning experience on many levels.
My intention to enrol in a master’s program was not recent; it began in my final college year. In 2010, I heard that a university-wide research competition had started; hence, I formed and led a research group of three members and participated in the competition. Our research achieved third place, with only four marks behind the project in first place.
At that time, I knew I wanted to have a similar experience again, but I decided first to gain hands-on experience in the technology industry. Later, in 2020, after a decade, I enrolled in the Data Engineering master's program at Edinburgh Napier University, where I experienced significant growth in my personal, academic, and professional skills. During the dissertation, Dr. Peter J. Barclay, the supervisor of my dissertation, suggested creating a peer-reviewed paper based on it.
Later, in 2024, I started working with Dr. Peter J. Barclay, Dr. Christos Chrysoulas, and Dr. Nikolaos Pitropakis on a peer-reviewed paper summarizing the dissertation findings to create a blueprint using DataOps, Kubernetes, and the Cloud-Native ecosystem to build a resilient Big Data platform following the Data Lakehouse architecture, for use as a base for Machine Learning and Artificial Intelligence.
In that journey, I faced many challenges, however, it presented a chance to step up and be a better version of myself. At this point, I persevered and achieved my goals. Therefore, the research group chose these quotes from our respective languages/cultures to emphasize the importance of perseverance and diligence:
“عِندَ الصَّباحِ يَحمَدُ القومُ السُّرَى”
(In the morning, the people praise the night’s journey)
- Arabic Proverb
“Αρχή ήμισυ παντός”
(The beginning is half of everything)
- Greek Proverb
“Is obair latha tòiseachadh”
(Beginning is a day's work)
- Scottish Gaelic Proverb
Motivation
Data sizes and types have changed dramatically in recent years, and the old methods and architectures cannot cope with that kind of data, which is different in both quantity and quality. Data Warehouses started in the 1980s, Data Lakes started around 2010, and finally, the Data Lakehouse, a relatively new hybrid architecture shown for the first time in 2020, combines the capabilities of a Data Warehouse and a Data Lake.
Still, based on the reviewed related work, no prior study covered building a generic data platform focusing on specific aspects like openness, portability, averting vendor lock-in (cloud-agnosticism), and emphasising flexibility and extensibility. Hence, our paper fills this gap by proposing and evaluating a data platform that leverages modern practices and technology and helps to create a data-centric business, where different personas smoothly interact with the data platform while managing and benefitting from Big Data.
In short, the motivation for this work was the lack of any reference for building a data platform that uses state-of-the-art technology to handle AI and Big Data challenges.
Challenges
The main challenges could be narrowed down to:
- Fast-paced changes in the data landscape.
- Massive dataset size.
First, writing an academic paper in a highly paced domain like Data Engineering and Artificial Intelligence is challenging as the landscape shifts quickly all the time. Staying ahead requires continuous monitoring of emerging trends, preprints, and cutting-edge developments. This dynamic environment makes impactful academic papers an uphill battle; however, with the industrial and academic skills available within the research team, it was possible to produce a high-quality paper.
Second, another Big Data challenge is handling massive datasets, which is challenging for academic research as it requires powerful computational resources. Also, working with that kind of data requires different types of systems to deal with storage, processing, and scalability, all while ensuring accuracy and reproducibility, which limits the ability to iterate quickly. Leveraging Cloud Computing capabilities and a Cloud-Native ecosystem helped to optimize costs and speed up the processing time by accessing computational resources on demand.
Conclusion
Undoubtedly, “data is the new gold” as everything now revolves around data. Therefore, modern data platforms must prioritize openness, portability, agility, and extensibility, while avoiding vendor lock-in through a cloud-agnostic approach to keep up with the dynamic changes in the data landscape.
Resources
All technical resources are available on the paper's GitHub repository, “modern-data-platform-research-paper”. This repository includes but is not limited to: Cloud infrastructure as code, Kubernetes manifests, data pipelines, TPC-DS data generation scripts, and a benchmarking Jupyter Notebook.
Tech Lead with Agility | M.Sc. in Data | Cloud-Native at Core | DevOps Transformation Advisor and Mentor
Find more at: aabouzaid.com
Follow the Topic
-
Discover Applied Sciences
This is a multi-disciplinary, peer-reviewed journal for the disciplines of Applied Life Sciences, Chemistry, Earth and Environmental Sciences, Engineering, Materials Science and Physics, fostering sound scientific discovery to solve practical problems.

Related Collections
With Collections, you can get published faster and increase your visibility.
Earth and Environmental Sciences: Crop Diversification for Resilient Ecosystem
Crop diversification is a strategic approach in agriculture that involves cultivating a range of different crops on a farm rather than relying solely on one type of crop. This practice offers numerous advantages, including reducing the risk of crop failure due to pests, diseases, or adverse weather conditions. By growing a variety of crops, farmers can also maintain soil health and fertility more effectively, as different crops have varying nutrient requirements and growth patterns. Moreover, crop diversification provides farmers with opportunities to tap into diverse markets, stabilize their income throughout the year, and contribute to environmental sustainability by promoting biodiversity and reducing reliance on chemical inputs. Overall, crop diversification is a key aspect of modern farming practices aimed at enhancing resilience, profitability, and ecological stewardship. Along with this, a resilient ecosystem is one that demonstrates the capacity to withstand and recover from disturbances while maintaining its essential functions and supporting biodiversity. These ecosystems possess several key characteristics that contribute to their resilience. Firstly, they have high levels of biodiversity, including a variety of species with different functions and niches. This diversity helps buffer against environmental changes and increases the likelihood that some species will thrive even under adverse conditions. Additionally, resilient ecosystems often exhibit strong ecological connectivity, allowing for the movement of species and genetic material across landscapes, which promotes adaptation and enhances overall resilience. They also tend to have robust feedback mechanisms and adaptive management strategies in place, enabling them to respond flexibly to disturbances and incorporate new information into their resilience strategies. Overall, resilient ecosystems play a crucial role in sustaining life on Earth by providing essential services such as clean air and water, climate regulation, and habitat for wildlife, while also supporting human well-being and livelihoods.
In this Topical Collection, we invite novel research and constrictive review works that share new insight results on the subject, as well as establish a positive discussion about the Crop Diversification for Resilient Ecosystem.
Major themes include:
- Ecosystem services for soil health management
- Biodiversity conservation for ecosystem resilience
- Sustainable soil health management through crop diversification
- Climate resilience farming for ecosystem management
- Reduced pesticide dependency through crop management
- Water quality management for enhancing nutrient use efficiency
- Crops nutritional dietary diversity
- Food security through crop management
- Economic stability through crop management
- Ecosystem services and crop risk management
- Crop diversification through building resilient ecosystems
- Water management through crop diversification
- Sustainable agriculture through
- Cultural Heritage and crops diversification
This Collection supports and amplifies research related to: SDG 2, SDG 15
Publishing Model: Open Access
Deadline: Dec 31, 2026
Engineering: Technological Advancement in Wireless Sensor Networks and Its Scope in Industry 4.0 IoT
This Topical Collection is dedicated to highlighting the cutting-edge methods and latest research in the field of smart sensing, primarily in terms of exploring the latest machine learning analytics to extract information from the consequent sensory data, and investigating potential risk and countermeasures to ensure the security and privacy of sensing devices in WSN based Internet of Things/ Industrial Internet of things (IoT/IIoT). It allows researchers in WSN and IoT community to demonstrate their new ideas which may potentially reshape the future of IoT/IIoT. While sensing data have been traditionally processed within a powerful remote cloud server, the recent emergence of edge computing with these communication technologies makes it feasible to perform AI processing at the edges. Edge processing is aimed at overcoming the slower and more expensive method of sending the data to the cloud. The benefits of the parallel development of cloud-edge technologies in wireless sensor networks and communications are manifold. The progress in the development of these technologies has opened several new opportunities in multi-domain applications, such as smart cities, transportation, intelligent manufacturing, and e-Health.
Publishing Model: Open Access
Deadline: Sep 30, 2026




Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in