Challenging Assumptions: Statistical Power and Replicability in Ecology
Published in Ecology & Evolution

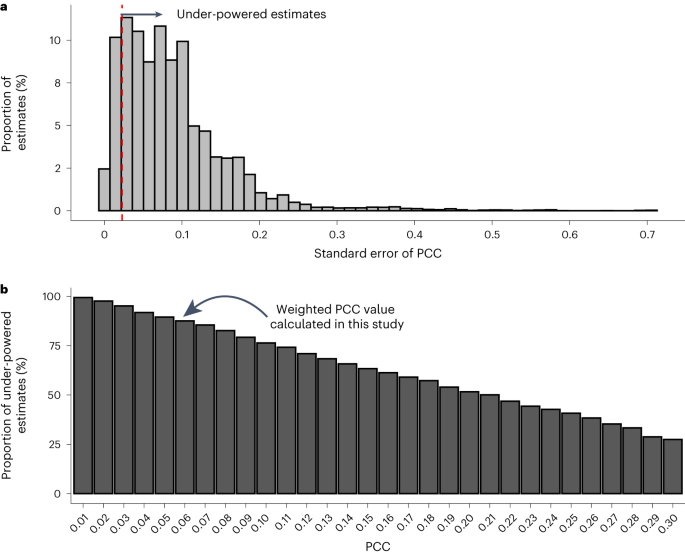
The paper, authored by me (Kaitlin) and my co-authors Paul and Meghan, is available in Nature Ecology and Evolution: https://www.nature.com/articles/s41559-023-02144-3
A pre-print is available on our Open Science Framework page: https://osf.io/9yd2b/
The first and only time I spoke to Paul in person (a downside to starting a postdoc the first week of March 2020), he drew a graph on the whiteboard in Meghan’s office of reported effect sizes before and after pre-registration (i.e., publicly sharing your research and analysis plan before starting your research) was required in clinical trials. Before pre-registration was required – effect sizes were mostly large and positive. After pre-registration was required – effect sizes were much smaller and swung around 0. The hypothesized cause of this difference: pre-registration takes away many biases and external incentives to publish exciting, ‘sexy’ results and instead pushes scientists towards more replicable and transparent practices.
Replicability is a recognized problem in many quantitative disciplines. Yet, Meghan and I, both highly trained quantitative ecologists, had only had a slight acquaintance with the specifics of it and the larger credibility issues low replicability can cause. To become more knowledgeable about these topics, Paul suggested I begin with a straightforward analysis looking at replicability in ecology for one of my postdoc projects. Because our manuscript focuses on exaggeration bias (e.g., a bias towards results with large magnitude effects in literature), I want to ground everyone in this concept before reflecting on our manuscript more broadly.
Exaggeration bias is directly connected to statistical power. When statistical power is low, effect sizes vary around the true effect. Studies that are underpowered and report significant results likely calculate an effect larger than the true effect because the spread of the data is greater than in higher powered studies (there is a nice figure in an article by Tim Parker and Yefeng Yang illustrating this: https://www.nature.com/articles/s41559-023-02156-z). If several scientists repeat the study, they could get widely different effect sizes where only a fraction are statistically significant. This variation in effect sizes is not the issue. If all the studies ended up being published – a meta-analysis would be able to calculate the true effect. However, studies with significant results (e.g., the ones that are likely exaggerated when power is low) are more likely to get published than those with null results (a.k.a. publication bias). This is the crux of the issue highlighted by our work: publication bias coupled with low power increases the prevalence of exaggerated results in the literature.
After understanding the connections between statistical power, exaggeration bias, and publication bias, I felt a bit defeated. No one had made these connections for me before, and now I was grappling with the fact that because of these biases, science was not as impartial and perhaps credible as I thought. It made me wonder, was I the only ecologist left in the dark about low power in ecological studies?
As part of our study, we conducted a survey to gain insight into ecologists’ perception of statistical power (note: the survey was not included in our final publication because it did not follow best practices for survey ). Our results indicated that over half (about 55%) of our 238 respondents thought that 50% or more of statistical tests in our dataset would be powered at the 80% power threshold. Indeed, only about 3% of respondents chose the bin that corresponded to our finding that 13.2% of tests met the 80% threshold. We also asked respondents who performed experiments how frequently they performed power tests (we hypothesized that power tests would be more common among experimentalists and thus, give us an upper bound on frequency). Of these respondents, the majority (54%) perform power analyses less than 25% of the time before beginning a new experiment, and only 8% always perform power analyses.
These results highlight two things. First, Meghan and I were not alone. Most ecologists were not aware of what a huge issue low statistical power was in our discipline. Meghan, Paul, and I were by no means the first to publish a study about statistical power in ecology. Researchers have been thinking about replicability in ecology at least since the early 1990’s, and it has a rich history in other disciplines – so we had a wealth of knowledge to build upon. However, based on the results of our survey it was apparent that this literature was not being widely taught to ecologists or talked about regularly when training new scientists.
Second, there is an incongruity between what people think about statistical power and how frequently they actually incorporate it into study design, quantify it, or report it when conducting their own research. On top of our survey results that indicated that power analyses are conducted infrequently at best by most people, only one paper out of the 354 papers included in our dataset even mentioned statistical power. My personal takeaway is that we trust other scientists and the review process to produce credible results, and perhaps some of that trust is misplaced, given that the majority of the time the larger research community is not adhering to best practices necessary to guard against bias and the exaggeration of results.
I am not suggesting that scientists need to only conduct studies that hit a specific statistical power threshold. Most scientists do not fall into a scenario where there are few logistic constraints on their studies. Paul used to tell his lab members to design the ideal experiment in our heads and then work backward to the best-case scenario based on logistical constraints and reasonable assumptions. In an ideal situation, a scientist would likely sample thousands of plots or collect data from every tropical forest or monitor hundreds of wolves for their studies but in reality no one can meet this ideal because of constraints like limited time or money. In many cases, it may be logistically infeasible to conduct a study that meets a high (or even moderate) statistical power threshold. So with that understanding, where do we go from here?
Realistically, the challenge is to move from the current scenario where statistically significant and ‘exciting’ results are valued to a scenario where all results are valued. Incentives must shift such that replication studies are seen as a valuable contribution to the literature. Another giant step forward would be if more ecologists pre-registered their analyses or submitted registered reports (i.e., a two-stage peer review process – check out this link for more information) for publication.
In science, no single study by itself tells the entire story. It is the collection of studies that allows scientists to quantify and synthesize a more accurate effect size by pooling many results together. Replication studies will help amass more data for meta-analyses that look to quantify the effect of a certain impact or process. Pre-registration and registered reports will also help amass more results – results that may not currently fit the bias of the type of results that are most valued. So, if we assume that only 13% of ecological studies can realistically be highly powered, we need many more lower powered studies looking at the same effect to understand our world with more confidence.
Undertaking this study was anything but straightforward for me. Performing the analysis proved relatively simple but thinking about the ramification of our results still occupies a large part of my mind. Since completing this analysis, I have incorporated many of the changes we propose in our manuscript in my own work. I convinced several of my colleagues to publish a study in the registered report format which is currently under stage 2 review. I have held two non-academic positions where I have pushed for pre-analysis plans to be made part of the research process. I make sure my data and code are easily accessible, and I am getting better at documenting my code so others can understand my approach.
I am also more cautious about what I consider to be the best and most exciting science. I am more dubious about big and ‘exciting’ effect sizes and am more enthusiastic about meticulous methods sections (sounds thrilling, I know). As we say in our manuscript, we believe that most ecologists would be willing to make changes in how they perform and consume science, but they first must be educated about the issues that lead to the prevalence of studies with low likelihood of being replicable. This shift in awareness is happening in different spheres of the ecology world, and I hope our paper can be part of this educational growth for current and future ecologists.
Follow the Topic
-
Nature Ecology & Evolution
This journal is interested in the full spectrum of ecological and evolutionary biology, encompassing approaches at the molecular, organismal, population, community and ecosystem levels, as well as relevant parts of the social sciences.

Related Collections
With Collections, you can get published faster and increase your visibility.
Understanding species redistributions under global climate change
Publishing Model: Hybrid
Deadline: Dec 31, 2026




Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in