Explore the Research
Continuous evolution of base editors with expanded target compatibility and improved activity - Nature Biotechnology
Improved base editors are generated by continuous evolution.
When I started my postdoc in the Liu group back in 2015, I knew I wanted to work with the lab’s trademark phage-assisted continuous evolution (PACE) system. Learning the system and all its fiddly bits was what attracted me – but I was agnostic about what to actually evolve. While I was sitting around brainstorming, my labmate Dr. Alexis Komor was working furiously – she had just gotten proof of concept data showing that C to T base editing worked in mammalian cells. This was huge news for the lab, and prompted a seismic shift as everyone started thinking about the followup experiments and applications that cytosine base editors (CBEs) would enable.
Maybe this was perfect timing. Could we use PACE to evolve base editors? In some ways it was a great match. We didn’t know for sure how base editors worked; they were enormous fusions of three proteins, only two of which had known structures, all performing some non-native function to accomplish C to T conversion. They had a lot of room for improvement, and rational engineering would be tricky. On the other hand, once a good PACE selection is set up, it needs little researcher guidance. The system will quickly test out a mind-boggling number of possible solutions (billions every hour), ideally while the researcher is browsing journals, drinking coffee or sleeping. I was excited at the thought of being able to improve base editor function without having to figure out how base editors worked.
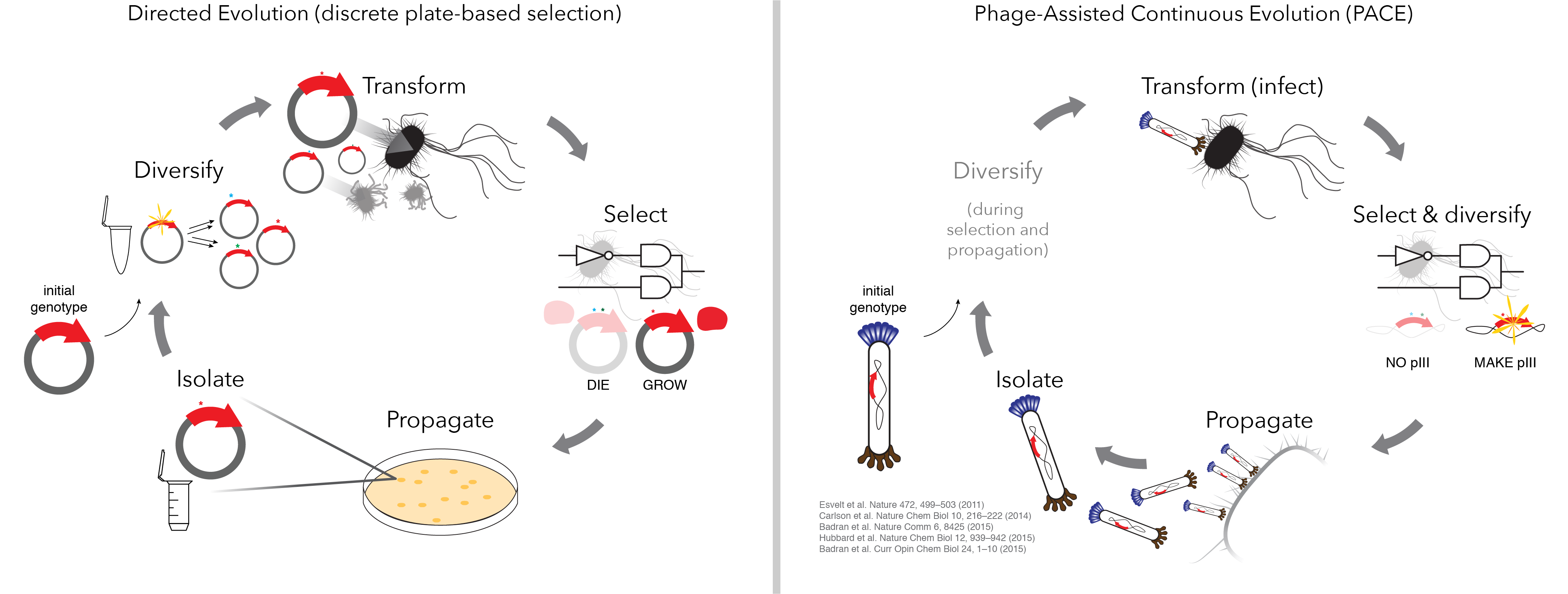
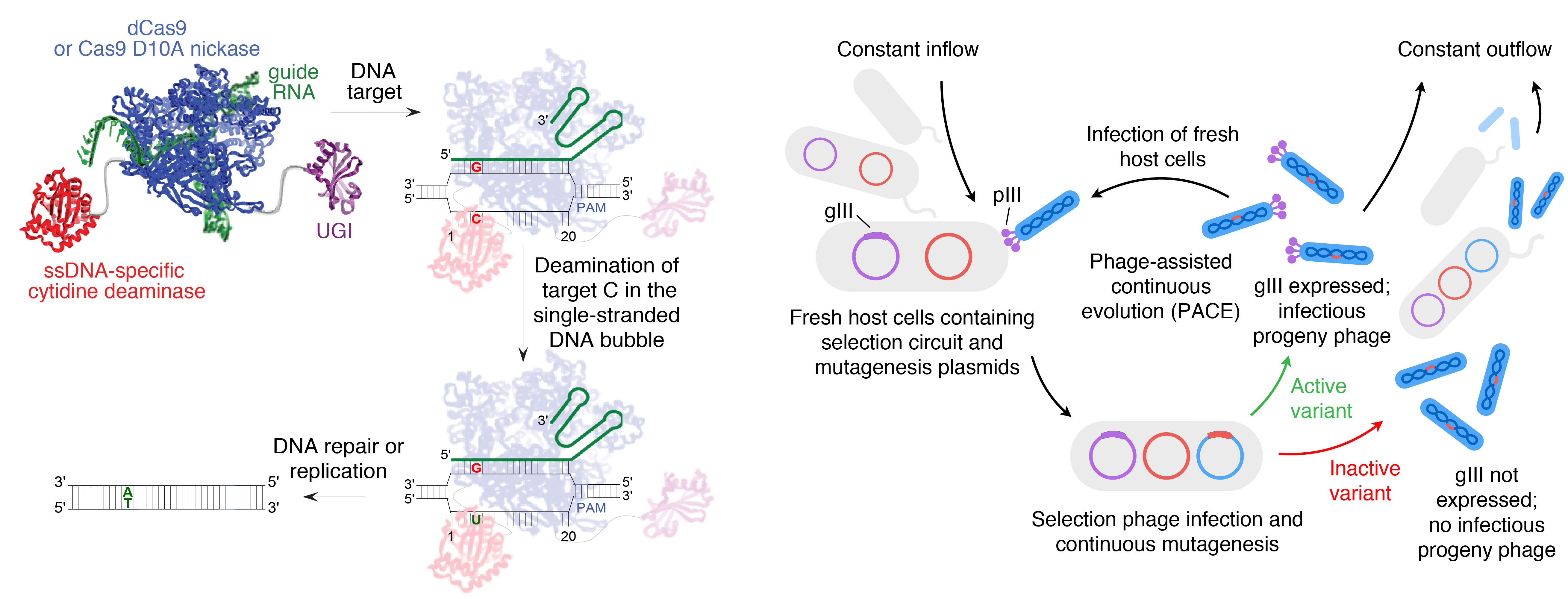
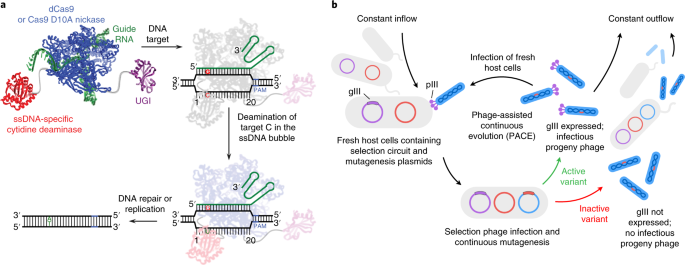
But building a new PACE selection from scratch can be a huge undertaking. PACE selections have to be fast (genotype to phenotype in minutes, not hours) and have to work in an E. coli cell that’s infected with phage, which is roughly like asking someone to solve math problems while their house is on fire. This is all in addition to the usual requirements for low background, high dynamic range and dealing with cheaters that come with any selection.
There were plenty of good reasons that CBE activity might be hard or impossible to select for in PACE. But we did some careful thinking and built our best guess for a circuit that might do the job. Funnily enough, it worked right away! At least, it did when we expressed CBE from plasmid. Getting it to function well enough with phage-encoded CBEs to support PACE was a much longer process, and we tried to lay out the difficulties, frustrations and surprises in the paper. You can actually try the optimization process for yourself! I made a chooseable-path-adventure style slide deck (PDF; downloading and viewing full screen works best) with real data for each possible combination of the adjustments we made (it’s in the Supplementary Info too, but that format is somewhat less fun). It turns out the solution we found isn’t the only one that works, but good circuits are pretty rare.
I learned a couple of important lessons about directed evolution from this project. First, I know now that it can be such a heavy lift to get a selection working (especially for PACE) that rational engineering can overtake you easily, especially in a rapidly developing field. The process of building a working circuit and starting to evolve CBEs took about 2 years. While I was developing the selection, our lab and others improved CBEs by leaps and bounds through engineering, solving some of the problems I had been hoping to tackle. Dr. Nicole Gaudelli and others even developed a totally new base editor class (ABE) in the time it took me to start evolving CBEs.
I also learned not to underestimate the effort needed to test and characterize evolution outputs. We probably spent >5x the person-hours on testing as we did on the evolution itself, although PACE did make the evolution very fast. I’m eternally grateful to the whole team, especially co-second authors Luke Koblan and Dr. Jon Levy, whose thousands of transfections let us figure out what we had and what it could do, and whose expertise with base editing and mammalian systems made up for my total ignorance at the start of the project.
In the end, two things about our project stand out to me as especially valuable. First, BE-PACE let us explore the space of deaminase activity and sequence preference, giving us CBEs to compare that spanned a full range of properties, and letting us collect data that expanded our picture of how base editing actually works (though our model is still full of assumptions that need additional experimental testing). Second, I’m really excited about the work that has yet to be done. Now that BE-PACE has gone from a long shot to an established system, our lab and others can use it, modify it and build on it to take on much more ambitious goals than I dared to when I was starting out. We just have to make sure those goals have enough potential impact – and are challenging enough – to warrant bringing our heaviest directed evolution machinery to bear.
I'm a synthetic biologist hoping to make the fast-growing bacterium Vibrio natriegens into a powerful platform for directed evolution.
Follow the Topic
-
Nature Biotechnology
A monthly journal covering the science and business of biotechnology, with new concepts in technology/methodology of relevance to the biological, biomedical, agricultural and environmental sciences.

Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in